







本文转自:从GPU编程到SIMT核心 - 知乎 (zhihu.com)
1、前言&本文重点
在 GPGPU 显得愈发重要的今天,仅凭 nVidia, AMD 提供的编程接口来了解 GPU 未免显得太单薄了些。时至今日, GPU 内部如何执行一条指令的对程序员来说依然是透明的、不可见的。为了达到程序效率最优化的目的,就必须要对 GPU 工作过程有一定了解和认知,故本文以前人成果 (GPGPU-SIM)为例,试分析 GPU 执行指令的具体过程。
/*
本文最开始的目的是翻译一下GPGPU-SIM的文档,中文文档在网络上并没有看到很好的,有,还剩一些访存的部分,这周争取读完。
*/
2、基础知识
2.1 CUDA编程简介
以下参考《CUDA C Programming Guide》
CUDA 是 NVIDIA 发布的在其统一架构 GPU 上进行通用程序设计的并行编程环境。 CUDA 软件环境包括一组 Runtime API、一组设备驱动函数、以及一个库文件。它们的层次关系如图下图所示。
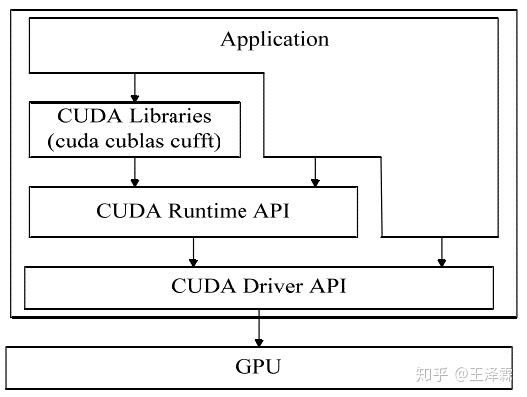
由上图我们可以很清晰地看到,CUDA 驱动库函数直接控制底层硬件结构Runtime 函数是对驱动函数的封装。应用程序可以直接调用底层驱动函数,也可以通过调用 Runtime函数间接操作底层硬件。
CUDA 还包括有多个数学工具库——诸如cuBLAS, cuFFT, cuRAND 。英伟达还提供一个被称为 nvcc的编译器。CUDA 所使用的编程语言基于 C/C++,并在 C/C++语言上进行了一系列的扩展,拓展主要包括以下四个方面:
- 用来表示函数是在主机 CPU 还是在设备 GPU 上执行的关键字,
__global__表示该函数为内核函数,只能在设备上执行,__device__表示 在设备上执行的非内核函数,__host__表示只能在主机 CPU 上执行的函 数; - 用来表示变量位于 GPU 哪一种内存空间中,
__constant__表示该变量位于常亮存储中,__shared__表示该变量位于共享内存中; - 指定内核函数的并行度,也就是 Grid 、 Block 的维度,例如
gridDim,blockDim; - 用于存储 Grid 和 Block 的维度信息和线程的索引标号,例如
blockIdx.x,blockIdx.y,blockIdx.z,threadIdx.x,threadIdx.y,threadIdx.z.
2.2 CUDA 线程组织模型
2.2.1 抽象的线程组织
以下参考《PARALLEL THREAD EXECUTION ISA:2.3 Memory Hierarchy》
具体到硬件的执行部分,每个CTA所能包含的线程数是有限的,与此同时,每个内核函数均是被组织成多个CTA,这些个CTA是同时执行的,因此,一个内核函数可以启动数量庞大的线程,不幸的是,不同CTA之间的线程无法通信或同步,但相同CTA之间的线程可以同步或通信。
每个线程可以访问不同的数据空间,但略有限制:每个线程之内有自己的私有内存空间,每个线程块之内有自己的共享内存,对块内所有线程可见,与整个块具有相同的生命周期,但所有线程均可以访问全局内存。
Tip: A cooperative thread array (CTA) is a set of concurrent threads that execute the same kernel program. A grid is a set of CTAs that execute independently.
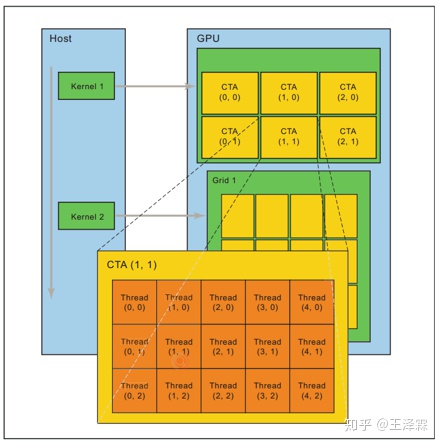
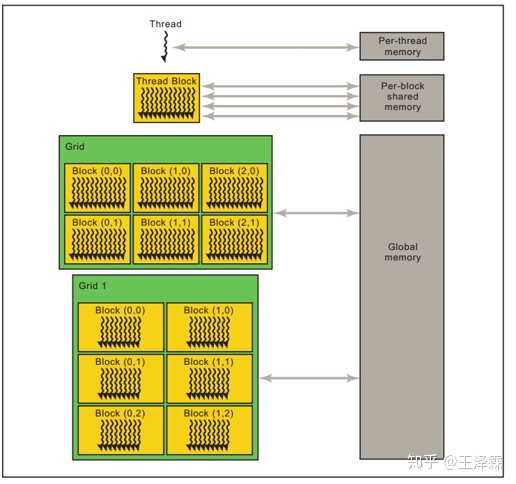
2.2.2 实际的线程组织
以下参考《CUDA C编程权威指南》
下面以二维矩阵元素为例,介绍 CUDA 软件中线程组织形式
- 首先我们知道,在 CUDA 中矩阵是行优先存储的,如下图

- 前文介绍了,CUDA 中线程索引、块索引为拓展字,因此我们可以直接拿来计算矩阵的元素位置
ix = threadIdx.x + blockIdx.x * blockDim.xiy = threadIdx.y + blockIdx.y * blockDim.y- 所以不难推知,当前线程块内、当前线程操作的矩阵元素索引为
idx = iy * nx + ix
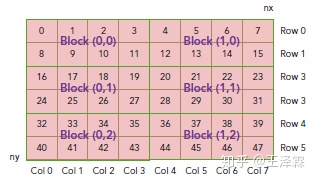
2.3 CUDA 机器模型
2.3.1 浅谈三种并行模型:SIMD、SIMT、SMT
以下参考
《SIMD < SIMT < SMT: parallelism in NVIDIA GPUs》
《PARALLEL THREAD EXECUTION ISA:3. PTX MACHICE MODEL》
首先厘清概念:
- SIMD:单指令多数据,首先获取多个数据,同时使用一条指令处理
- SMT:同时多线程,不同线程之间的指令可以并行执行
- SIMT:二者折中方案,单指令多线程,线程内部执行相同指令,但比SIMD更灵活,比SMT效率更高
其次,对比 SIMT 与 SIMD ,上文说到,SIMT 比 SIMT 更灵活,其主要体现在以下三点
1. 单指令,可以访问多个寄存器组。(联系上文,每个线程有自己的寄存器)
- 单指令,多种寻址方式。
- 单指令,多种执行路径
(每组线程中,如果出现分支指令,则不同线程之间串行执行,直到分支指令执行完毕,每组线程继续并行执行相同指令,下文会提供一种分支指令预测机制)
最后,对比 SIMT 与 SMT,上文说到,SIMT比SMT效率更高,主要体现在 SIMT 可同时运行的线程更多、寄存器更多这两点:
- 足够多的线程,可以获得足够高的吞吐率
- 一方面延迟是竭力避免的,另一方面寄存器的价格是可以接受的。
2.3.3 什么是Warp
Warp是SM的基本执行单元。一个Warp包含32个并行thread,这32个thread执行于SIMT模式。也就是说所有Thread执行同一条指令,并且每个Thread会使用各自的数据执行该指令。
不难推知,每个block中Warp数量可以很简单地推算出来,目前 nVidia 的GPU中 WarpSize = 32。
一个 Warp 中的线程必然在同一个 Block 中,如果 Block 所含线程数目不是 WarpSize 的整数倍,那么多出的那些thread 所在的 Warp 中,会剩余一些 inactive 的 thread,也就是说,即使凑不够 Warp 整数倍的thread,硬件也会为 Warp 凑足,只不过那些 thread 是 inactive 状态,需要注意的是,即使这部分thread是inactive的,也会消耗SM资源。
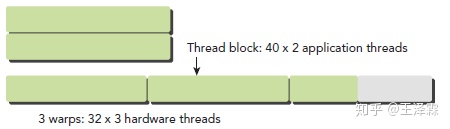
一个Warp内部产生的分支分歧问题,将在下文详述。
2.4 CUDA 汇编语言举例分析
2.4.1 回顾CUDA 代码格式
以下参考《CUDA C Programming Guide》
- 函数的声明,需要指出其执行的具体位置,是GPU还是CPU?
__global__ void foo(...) // runs on GPU, callable from CPU
__device__ void bar(...) // function callable from a GPU thread
- 需要制定 Grid ,block 的大小,以启动核函数,用三个尖括号括起:
<<<gridSize,blockSize>>>
foo<<<500, 128>>>(...); // 500 blocks, 128 threads 来启动核函数
- 在核函数内部,需要通过计算来得到当前线程的ID
dim3 threadIdx; dim3 blockIdx; dim3 blockDim
2.4.2 CUDA 代码示例
以向量加运算为例,A[1..N] + B[1..N] = C[1..N]
如果是用 C 语言书写,只能用for循环实现
void vecADD_serial(
const int* a,
const int* b,
int *c,
const int n)
{
for (int i = 0; i < n; ++i)
c[i] = a[i] + b[i];
}
但我们现在尝试用 CUDA 语言书写,每个元素均用一个线程操作,其内核函数如下所示:
__global__ void add_vectors(
const int* a,
const int* b,
int *c,
const int n)
{
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= n) return;
c[idx] = a[idx] + b[idx];
}主函数大意如下所示,这里需要申请GPU内存,交换数据CPU -> GPU ,启动内核,传回数据 GPU->GPU:
int main() {
… // omitted: allocate and initialize memory
// Invoke parallel kernel with 256 threads/block
int nblocks = (n + 255) / 256;
add_vectors<<<nblocks, 256>>>(a,b,c,1024);
… // omitted: transfer results from GPU to CPU
}
2.4.3 CUDA PTX分析
以下参考 《Demystifying PTX Code》
承接上文,通过nvcc yourname.cu --ptx 生成的汇编语言如下所示:
//
// Generated by NVIDIA NVVM Compiler
// Compiler built on Sun May 18 04:44:51 2014 (1400399091)
// Driver 331.79
//
.version 3.0
.target sm_21, texmode_independent
.address_size 32
//文件以nvcc编译器的信息注释作为开头,紧接着跟着三行:
//PTX ISA版本
//目标架构,计算能力
//使用的地址模式
.entry add_vectors(
.param .u32 .ptr .global .align 4 add_vectors_param_0,
.param .u32 .ptr .global .align 4 add_vectors_param_1,
.param .u32 .ptr .global .align 4 add_vectors_param_2,
.param .u32 add_vectors_param_3
)
//接下来是 .entry 指令指引的 kernel 函数入口
//下面是四个参数
//此Kernel函数的参数组指针,和一个32位整型变量(输入和输出向量的数是三个指向32位整型全局内存中的长度)。
//每个参数以 .param 伪指令开头,接着是其数据类型 .u32 (优化成了无符号整形)
//.ptr 参数为指针类型
//.global 数据都在全局内存中
//.align 4数据对齐的方式,
//本例中是4字节对齐
//注意,常量和非常量指针在这里没有区别
{
.reg .pred %p<2>;
.reg .s32 %r<21>;
//这里是寄存器的定义
//以伪指令 .reg 开头,寄存器名字是以 % 作为前缀。
//有.pred指令的用来条件分配,比如分支指令。由于PTX是中间语言,因为寄存器的定义是虚拟的,不一定完全 和硬件寄存器是一对一的关系。
//一组包含N个虚拟寄存器的寄存器组可以用<N>的形式来定义,并且可以通过r0, r1, .. , rN-1,r是通过%r给 寄存器组赋的名字。
ld.param.u32 %r9, [add_vectors_param_3];
//ld.param指令则将函数参数拷贝给了寄存器。因为绝大多数PTX指令都不能直接操作函数参数。所以第四个参数 传递的是地址,因此需要添加[ ]中括号来获取其数据。
mov.u32 %r5, %envreg3;
mov.u32 %r6, %ntid.x;
mov.u32 %r7, %ctaid.x;
mov.u32 %r8, %tid.x;
//接下来,一些特殊的数值被拷贝给了GPU寄存器
//envreg3: 由驱动定义的、只读特殊寄存器
//ntid.x:每个CTA的x维度的线程数量,相当于 get_local_sizeo(0)
//ctaid.x:grid里的CTA标识符,相当于 get_group_id(0)
//tid.x :CTA x维度的线程号,相当于 get_local_id(0)
add.s32 %r10, %r8, %r5;
mad.lo.s32 %r4, %r7, %r6, %r10;
//首先是一个加法 add
//R10 = envreg3 + tid.x;
//其次一个乘法&加法 mad :
//R4 = ntid.x * ctaid.x + tid.x = get_global_id(0);
//PTX 文档中指出,envreg3 由驱动负责,可以不理会
setp.lt.s32 %p1, %r4, %r9;
@%p1 bra BB0_2;
//接下来就是本例中唯一的一个条件指令。
//setp指令是指比较 r4 (当前线程 ID )是否比 r9(数组长度)小(lower than,.lt指令)
//以此设定谓词p1。
//@指令则判断p1,如果p1是true,执行分支BB0_2
//bra指令,注意bra指令的目标一定要是label或者指向label的寄存器
//如果p1是false,则直接执行后面的代码。
//本例中,分支指令后仅有ret指令表示当前分支的结束。
ret;
BB0_2:
//实际的运算部分指令位于标签 BB0_2 之下,总体包括
//计算数据指针
//从全局内存中读取数据
//实际的运算
//保存数据到全局内存中
shl.b32 %r11, %r4, 2;
//r4 寄存器内容,左移两位(*4)存入r11,左移不考虑符号位
ld.param.u32 %r18, [add_vectors_param_0];
//读取第一个函数参数,向量A起始地址,ld.param 读参数
add.s32 %r12, %r18, %r11;
//相加得到当前线程 ID 操作的数据地址,存入%r12
ld.param.u32 %r19, [add_vectors_param_1];
add.s32 %r13, %r19, %r11;
//上同,获得向量B的当前数据位置,存入%r13
ld.global.u32 %r14, [%r13];
//读取向量B当前欲操作数,地址在r13中,ld.global 读全局内存
ld.global.u32 %r15, [%r12];
//读取向量B当前欲操作数,地址在r12中
add.s32 %r16, %r14, %r15;
//实际的相加指令
ld.param.u32 %r20, [add_vectors_param_2];
add.s32 %r17, %r20, %r11;
st.global.u32 [%r17], %r16;
//上面三条指令,得到向量C的当前存储地址,存数
ret;
}2.5 记分牌算法扼要
2.5.1 简介
记分牌是一集中控制部件,其功能是控制数据寄存器与处理部件之间的数据传送。在记分牌中保存有与各个处理部件相联系的寄存器中的数据装载情况。当一个处理部件所要求的数据都已就绪(装载完毕),记分牌允许处理部件开始执行。当执行完成后,处理部件通知记分牌释放相关资源。所以在记分牌中记录了数据寄存器和多个处理部件状态的变化情况,通过它来检测和消除或减少数据相关性,加快程序执行速度。
2.5.2 方法
尽可能提早指令的执行。当一条指令暂停执行时,如果其他后继指令与暂停指令及已发射的指令无任何相关,则仍然可以发射,执行。(发射是顺序的,执行时乱序的)
因此将指令的执行分为4级:
1. 发射:指令译码 并 检测结构冒险(ID1) ,按照指令顺序发射
指令的功能部件没有结构竞争和没有WAW冒险的时候,则这条指令可以发射。将会把指令发射到相应的功能部件,同时修改记分牌的内部数据结构。如果存在结构竞争或者是存在WAW冒险时候,指令暂停发射。
2. 读操作数:等待到没有数据冒险,再读取操作(乱序读) ,乱序读操作数
记分牌监控源操作数是否就绪。一个源操作数就绪的条件为: 早前发射的活动指令对该操作数不进行写入操作(即无RAW冒险)记分牌在这一步解决了RAW冒险问题。 当源操作数准备就绪,记分牌通知功能单元读出操作数,并开始执行。 检测RAW, 若有,则停顿该指令。但是在动态调度时,有多条指令并行操作,所以可能有另外指令满足条件,则继续执行下去,从而消除了停顿的损失。
3. 执行:对操作数进行操作 (EX),乱序执行
功能单元开始对操作数执行操作。当得到“结果”后,功能单元通知记分牌该操作已执行完毕。
4. 写结果:完成执行 (WB),顺序写结果
检查是否有WAR冒险,如果存在,则暂停指令。否则就写入寄存器。 记分牌在各执行步骤中需检测和记录的事件。示例DIVD F0,F2,F4 ADDD F10,F0,F8 SUBD F8,F8,F14 ,记分板将暂停SUBD指令,直到ADDD指令读取了操作数。
3、 GPU微架构模型
以下内容参考 1. GPGPU-SIM Manual 2. GPGPU-SIM-Presentation-On-Micro42
3.1 概览 GPU 硬件体系结构(假想模型)
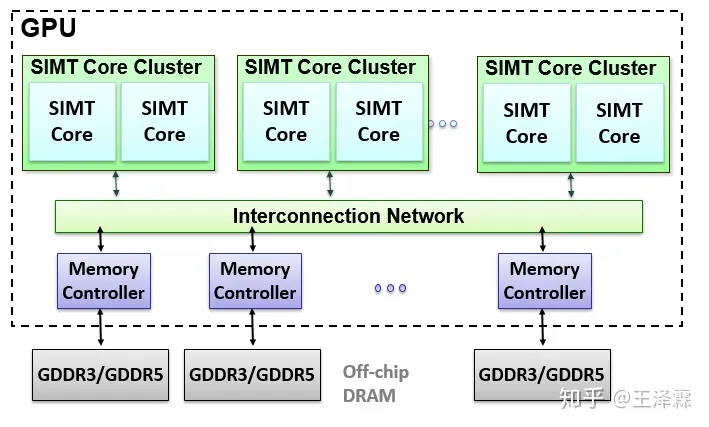
GPGPU-Sim 所模拟的 GPU 结构如上图所示。与现实中的 GPU 硬件结构相对应,其功能模块由三部分组成,分别为流多处理器(Stream Multiprocessors, SM), 存储器系统以及它们之间的互联网络。模拟器所模拟的每个 SIMT核心 中都包含有一个类似于简单 MIPS 五段顺序的流水线结构,SIMT核心簇通过虚拟的互联网络连接到存储器子系统。每个存储控制器控制两个片外的 GDDR3/5 芯片模型。最新版本的 GPGPU-Sim 模拟器添加了对现实中 GPU 线程处理簇(TPC,Thread Processing Cluster)的支持,这使得多个 SM 之间共用一个到互联网络的接口访问数据。
3.2 SIMT 核心簇(假想模型)
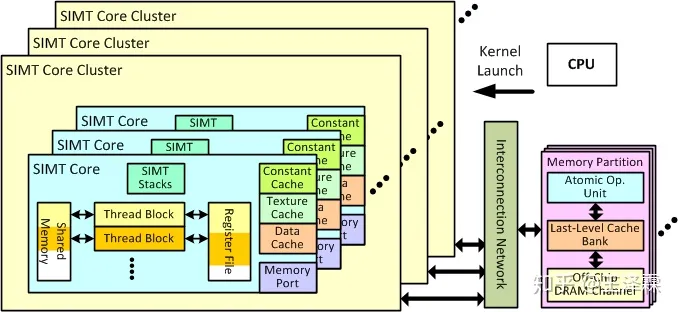
如上图所示,SIMT核心簇是包含一系列的SIMT核心,核心簇内部所有SIMT核心共享一个内部互联网络端口。核心簇共享一个FIFO队列,用来保存从互联网络取到的数据。这些个数据被定向发送到SIMT核心的指令高速缓存、或其存储访问单元 。为了使每个SIMT核心均能处理LD\ST指令,每个核心的LDST单元均有端口与外部请求端口相连、但同一簇内所有核心共用一个请求缓冲区。
3.3 GPU中SIMT核心(模拟对应实际的SM核心)
3.3.1 SIMT 核心概览
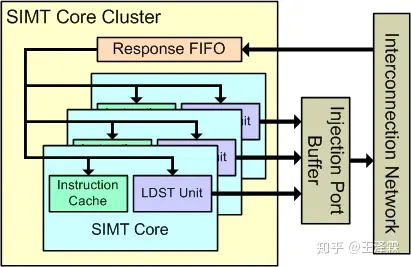
每个SIMT核心模拟了一个SIMD处理器,其大致相当于nVidia所言的SM(Streaming Multiprocessor ,流式多处理器),或相当于AMD所言的CU (Compute Unit),SIMT核心的组织如上所示。
3.3.2 细探SIMT核心
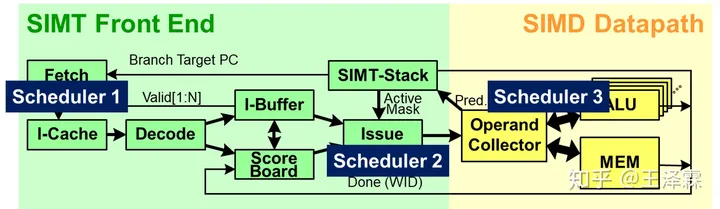
SIMT核心被分为前端、后端,并且配有三个独立的调度器。每部分
实际的SM对应于上图的一个SIMT,而实际的SP核心对应于一组ALU流水线。
3.3.2.1 SIMT核心前端
- FETCH 取指令(one instruction, one cycle, per warp)
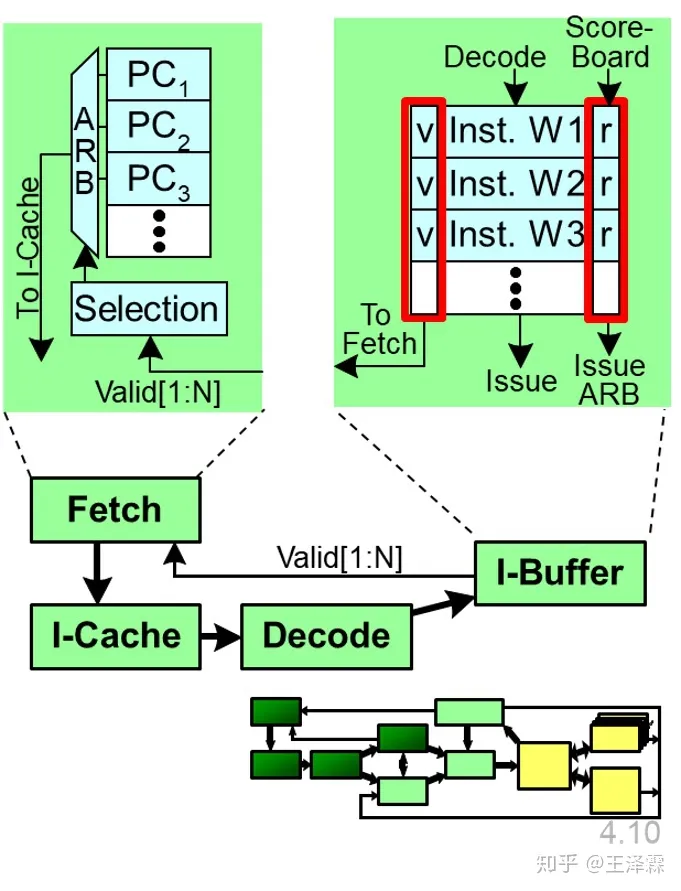
- 这里出现了第一个调度器:取指调度器。负责将取到的指令送入 I-Cache 中。
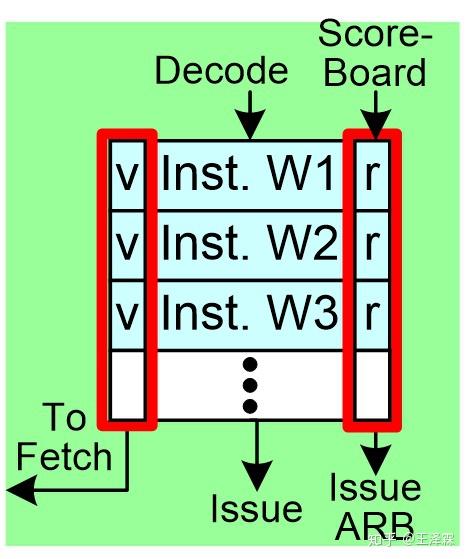
- SIMT 前端中的指令缓存模块( I-Buffer)用于缓存从 指令Cache中取出的指令。I-Buffer 被静态划分,使得运行在 SIMT 核心上的所有 warp 在其中都有专门的空间存储指令。在当前的模型中,每个 warp 有两个 I-Buffer 条目。 每个 I-Buffer 条目有一个有效位(valid bit),一个就绪位 (ready bit) 以及一个对应于该 warp 当前指令的译码后的指令。有效位表示当前 I-Buffer 的该条目中还有一个未发射的指令。 (该条目上的指令有效),就绪位表示该 Warp 当前指令已经准备好被发射到执行流水线中。
- 通常情况,没有结构冒险、没有WAW冲突的时候,就绪位置1。
- 如果在 I-Buffer 中没有任何有效指令,所有需要取指的 warp 会以轮询的方式访问 I-Cache 。一旦被选中,一个读请求以及下一条指令的地址被送入到 I-Cache 。默认情况下,两条连续的指令被取出。只要一个 Warp 被取指调度器调度进行取指操作,对应的 I-Buffer 条目有效位即为1, 直到该 Warp 内所有指令均执行完毕。
- 只有当一个线程执行完所有指令,并且没有未完成写回存储器、写回寄存器请求时,才能说一个线程执行完毕;只有当一个Warp内所有线程均执行完毕,该Warp才被认为执行完毕,并且不再受取值调度器调度;只有一个线程块内所有Warp执行完毕,该线程块才被认为执行完毕;只有所有块执行完毕,该内核函数函数才算执行完毕。
- DECODE 指令译码 (one instruction, one cycle, per warp)
在译码阶段,当前被取出的指令被译码,确定指令种类(算术/分支/访存)和要被使用的寄存器。之后便存储到 I-Buffer 相应的条目中等待被发射。译码的同时也会检查寄存器的记分牌(score board),以确定可能有相关性的冲突。一旦检测到冲突,将清空译码阶段的输入流水线寄存器,使正在译码的指令失效。若没有冲突,将在记分牌入口设置标识,表示这些指令的流出的寄存器正被使用。
- ISSUE 指令发射(multi instructions, one cycle, per warp)
- 这里出现了第二个调度器:发射调度器,功能是从 I-Buffer 中选择一个 Warp 发射到后续流水线中。此调度器独立于之前的取指调度器。调度方式是循环优先级策略(指不同Warp)。
- 发射调度器可以进行配置,每个周期从同一个 warp 中发射多条指令。更进一步地
- GT200 (e.g. Quadro FX 5800): 允许双Warp同时发射。
- Fermi架构:Warp奇偶独立调度器。
被发射的指令必须满足以下条件
- 该 warp 没有处于栅栏同步(barrier)的等待状态
(CUDA允许同一Block内不同Thread间实现块内通信) - I-Buffer 对应条目中的有效位为1(为0说明该条目上的指令无效)
- 通过记分板检测
- 指令流水线中的取操作数阶段(operand access stage)不是挂起状态。
发射指令目的地
- 存储器相关指令(load, store , memory barriers etc),被发射到存储流水线(参看下文 MEM PIPELINE)
- 运算指令被发射到ALU计算单元,其包括多个SP流水线、SFU流水线。
- 分支指令将清空 I-Buffer 内所有与该 Warp 相关指令(参看下文SIMT STACK)
- SIMT STACK:SIMT指令栈
每个 Warp 均有一个SIMT-stack,来解决一个Warp内的线程指令分歧问题。考虑到每个Warp内所有线程必须执行相同指令,因此,当不同线程出现不同分支情况时,所有线程将串行执行,这将会大大降低硬件的效率,因此我们需要一个方案,来降低这种分歧带来的影响,最简单的方法就是 PDOM(post-dominator stack-based reconvergence ) 机制。
以下参考 Dynamic Warp Formation: Efficient MIMD Control Flow on SIMD Graphics Hardware
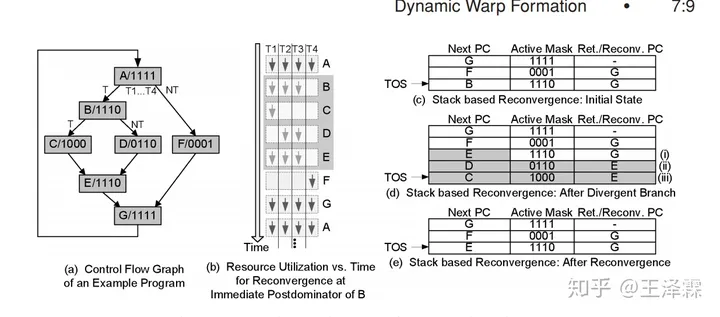
上图 a&b 两个子图说明了一个假想线程块内四个线程的分支情况:其中 a 图中每个 Flow Graph 指令中、按位代表该线程经过这个路径。
精髓在于 c、d、e三个子图:现在考虑四个线程,T1, T2, T3,T4 均运行到了 A指令 ,T1, T2, T3下一条指令为B,汇合点为G。(见 c 图)
当执行完分支指令B时,Stack更新状态成 d 图,更新过程如下:
说明:TOS:Top Of Stack 栈首元素;x栈:某个 x 子图所示栈;大写字母,执行流上的指令;小写字母:子图
1)c栈的TOS,与d栈的TOS相同。只有Next PC 域被改变,变成了三个线程汇合点E;
2) B的一个分支 (D) 压入栈(见标号d栈ii),连同将 D 分支对应的活动掩码、汇合点E入栈,活动掩码按位指示T2, T3线程执行该分支。
3)B的另一个分支(C)压入栈(见标号d栈iii),连同将 C 分支对应的活动掩码,汇合点E入栈,同样的,活动掩码按位指示 T1 线程执行该分支。
当执行B指令的后续分支指令时,开始弹栈:
1)当 T1 线程执行后续指令时,弹栈,栈顶元素的活动掩码指示 T1 执行 C 分支,汇合点是 E (继续弹栈,直到Next PC域为E)
2)当 T2, T3 线程执行后续指令时,弹栈,栈顶元素的活动掩码指示 T2, T3 执行 D 分支,汇合点是 E (继续弹栈,直到Next PC域为E)
3) 到达汇合点 E 时,SIMT stack如 e 所示,继续重复上述过程。
nVidia 并没有明示他们是如何处理分支指令的,在PTX文件中也没有有效信息(见上述分析),但如果反编译的话(cuobjdump),会得到和上述方法相同的结果。
- SCOREBOARD 记分板
记分板部件检查结构冒险、WAW冲突。如上所述,被某个Warp的一条指令写入的寄存器在发射阶段被预留。记分板装置依靠Warp的ID进行索引。它存储了对应某个Warp ID指令的所需要的寄存器的数目。预留的寄存器在写回阶段被释放。
3.3.2.2 SIMT核心后端
- OPRAND COLLECTOR 操作数收集器(本节用OP.COL.代替)
以下参考专利US7834881B2 - Operand collector architecture
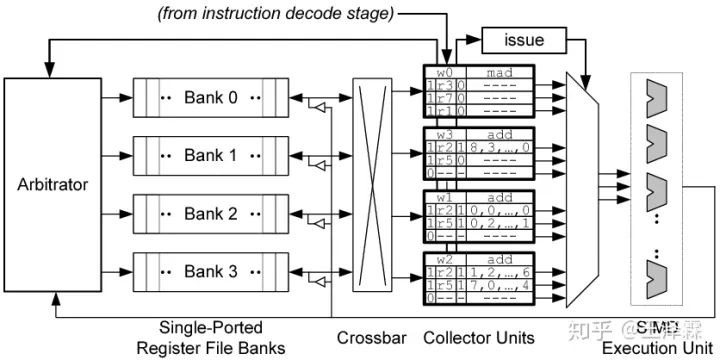
上图为假想图,根据nVidia发布的专利推测出来的Oprand Colloctor具体结构。
注意,这里出现了第三个调度器,称之为取数调度器。
组成 OP.COL. 的是一组缓冲器、和一个调度器。
每当一条指令被译码后,OP.COL.便为该指令分配空间,用于取数。OP.COL. 单元并没有通过寄存器换名技术来消除寄存器名字依赖,而是通过另一种方式:确保每个周期内,对一个 Bank 的访问,不得超过一次。
观察上图,其包含四个Collector Units,每个Unit包含三个操作数条目,和一个标志符,用于指示当前该Unit属于哪个Warp的哪条指令。
每个操作数条目包含四个字段:
- 一个就绪位
- 一个有效位
- 一个寄存器识别符
- 操作数:该域包含128字节,可以存放32个4字节数,可以满足一个Warp内的32个线程。
- 注意:每个Thread 有自己的寄存器,因此仅需一个寄存器标志符即可
- 另外,调度器为每个Bank均保留了一个请求读队列,直到所有Unit对该Bank的访问均已完毕。
当一条指令经过译码阶段并且存在Collector Unit可用,则该Collector Unit 被分配给该指令,相应的Warp标志、有效位、寄存器识别符被设置,操作数域被初始化为 0 。此外,操作数的读请求被排队到调度相应Bank队列。实际上,执行单元写回的数据的优先级总是高于读请求。调度器每周期选择一组至多4个无bank冲突的数据发送到寄存器堆。实际芯片中,为了减少 Crossbar 和 Collector Unit 的面积,每个Collector Unit 每个周期只接收一个操作数。
当每个操作数被从寄存器堆读出并放入到相应的 OP.COL. 单元中,该指令就绪位被设置为1。最终,当一个指令的所有操作数都就绪后,该指令被发射到一个SIMD执行单元。 实际上,对于每种不同的SIMD执行单元(SP,SFU,MEM),均有各自独立的 Collector Units ,同时也有一组共享的 Collector Units。
- MEM PIPELINE 存储流水线

本阶段处理线程访问全局内存与共享内存发出的请求。 每个 SIMT 核心有 4 种不同的片上一级存储器:共享存储器( Shared Memory ), 一级数据缓存( L1-data-cache ), 常量缓存 ( constant cache )以及纹理缓存( Texture Cache )。虽然上述四个存储器物理上独立,但由于其均为是存储流水线 (LDST unit) 的组成部分,因此它们共享同一个写回阶段。
- ALU UNIT 计算单元
GPGPU-Sim有两种ALU计算单元:SP计算单元执行除超越方程外的任何指令;SFU计算单元执行超越方程额指令(sin,cos,log,etc)这两种单元均以SIMD方式执行:
- SP计算单元通常每周期执行一个Warp的一条指令
- SFU计算单元执行周期视指令不同而不同:
- sin指令需要4个周期
- 取倒数指令需要两个周期
3.3.2.3 SIMT核心总览
综合前文分析,把每一部分串联到一起,就得到了下图。
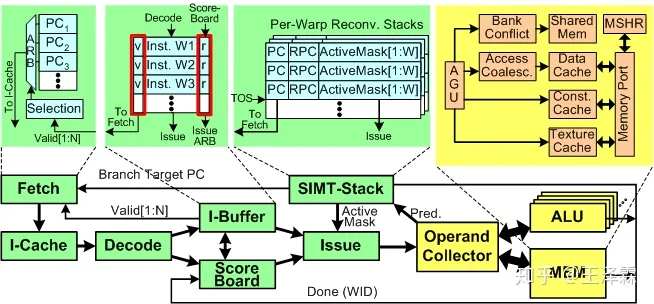

















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









