






引言
随着人工智能领域的发展,GPGPU(General-Purpose Graphics Processing Unit)领域获得了前所未有的关注,凭借其高性能计算的特点,以及 SIMT(Single Instruction Multiple Threads)编程的易用性,促进了整个生态的蓬勃发展。
这里首先介绍 SIMT 的编程界面,通过对比普通的C语言标量编程及 SIMD(Single Instruction Multiple Data)向量编程,展示其易用性。再结合 GPGPU 的架构,分析其代码执行过程。最后介绍 SIMT 代码编译流程。
SIMT 编程及其易用性分析
高性能计算,最常见的操作便是 Element-wise 操作,这里以N个整型数据进行 Element-wise 的加法计算为例。
普通的C语言编程,常见的写法如下:
void foo(int *x, int *y, int N) {for (int i=0, i < N, i++)y[i] = x[i] + y[i];}
上面的写法执行效率低,需要循环执行N次。为了提高性能,这里展示常见的 SIMD 编程方案(以 Arm 的 Neon 为例):
#include <arm_neon.h>void neon_add(int32_t* x, int32_t* y, int N) {int i;int32x4_t vx, vy, vc; // 自定义向量类型for (i = 0; i < N; i += 4) {vx = vld1q_s32(x + i); // 将原地址x的数据提取到向量vxvy = vld1q_s32(y + i); // 将原地址y的数据提取到向量vxvc = vaddq_s32(va, vb); // 进行向量加法计算,写入vc向量vst1q_s32(y + i, vc); // 将vc数据存放到目标地址}}
以及常见的 SIMT 编程方案(以 CUDA 为例):
__global__ void foo(int *x, int *y) {int i = threadIdx.x; // 用于标记线程idy[i] = x[i] + y[i]; // 进行标量提取、计算、存储}int main(){int N = 256; // threads数量// Run kernelfoo<<<1, N>>>(dev_x, dev_y);}
上述 SIMD 和 SIMT 的编程方案均能达到 Element-wise 的加法效果,具体过程见代码标注。从编程界面来看,SIMT 编程方案最符合一般编程人员的编程习惯,使用常规的C语言运算符即可满足,而 SIMD 编程需要使用很多内置的数据类型(int32x4_t)和函数(例如vld1q_s32、vaddq_s32 和 vst1q_s32),所以 SIMT 的编程易用性更好。
介绍完 SIMT 的编程,下面介绍下 SIMT 代码如何在 GPGPU 硬件执行。
SIMT 代码执行及性能分析
为了更加清晰的介绍 SIMT 代码的编译和执行,这里以 NVIDIA 的 Maxwell_GeForce-GTX-750 芯片为例,如下图所示。
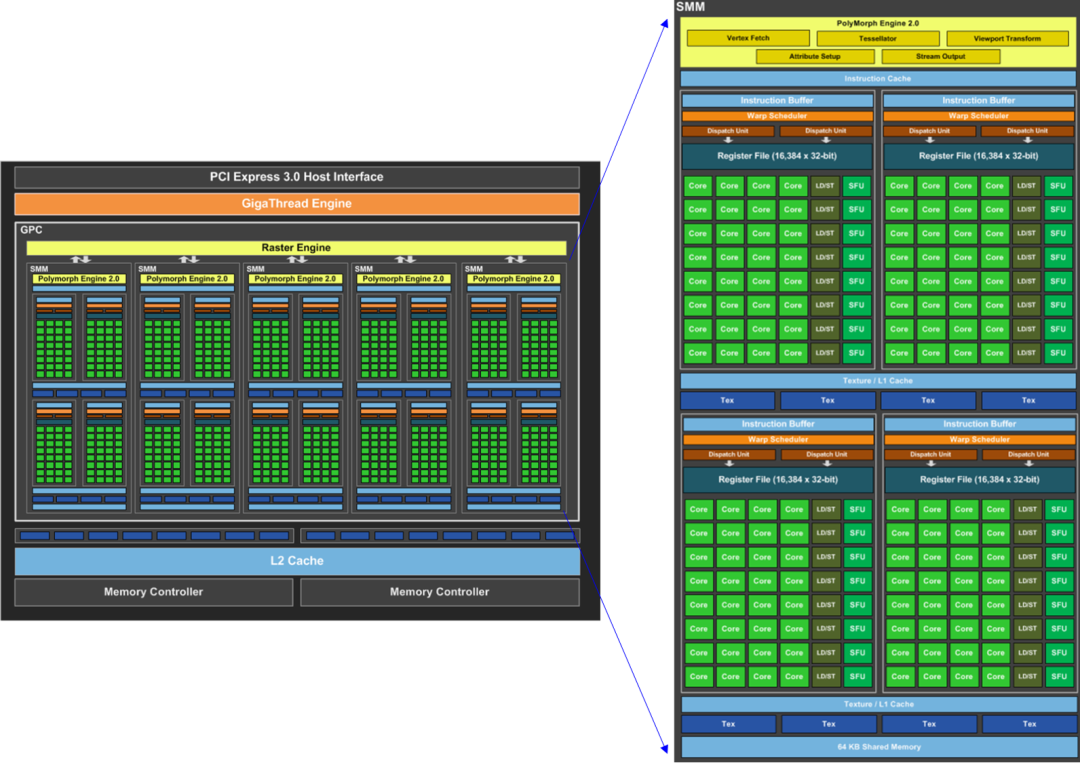
图1 Maxwell_GeForce-GTX-750
从图中,可以发现,每个 SM 核中有 Warp Scheduler、Instruction Fetch/Dispatch、RegisterFile、Core、Shared Memory等。还是以上个章节介绍的 SIMT 代码为例,最终编译的硬件指令序列如下:
MOV R1, c[0x0][0x20] ;S2R R0, SR_TID.X ;SHL R2, R0.reuse, 0x2 ;SHR R0, R0, 0x1e ;IADD R4.CC, R2.reuse, c[0x0][0x140] ;IADD.X R5, R0.reuse, c[0x0][0x144] ;IADD R2.CC, R2, c[0x0][0x148] ;LDG.E R4, [R4] ;IADD.X R3, R0, c[0x0][0x14c] ;LDG.E R6, [R2] ;IADD R0, R4, R6 ;STG.E [R2], R0 ;EXIT ;
上述 SIMT 代码,总的 thread 数 N 为 256,对应 Warp 个数为 8(Warp size=32),总的指令数为 13,那么代码执行过程如下图所示:
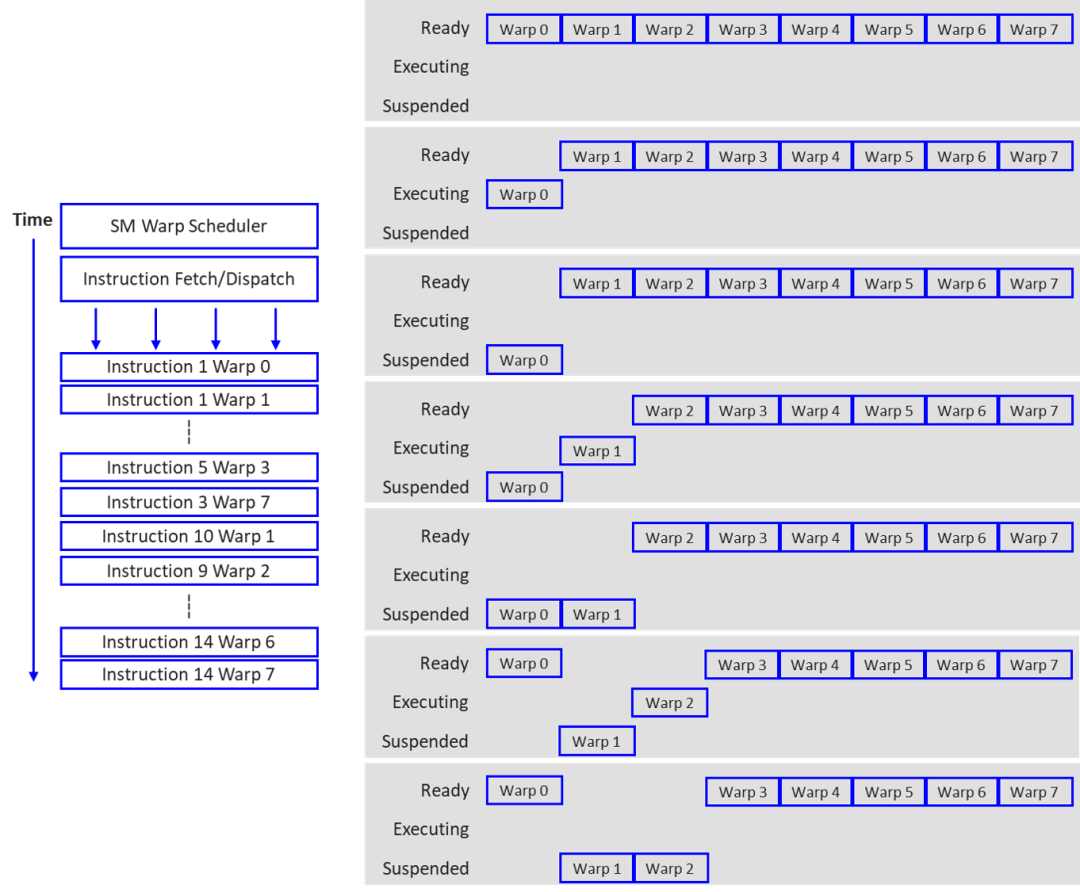
图2 SIMT代码执行过程
所有 Warp 均由 Warp Scheduler 统一下发,每个 Warp 的指令顺序执行,可以发现,执行过程中,第 n 个 Warp 的指令 a 在 suspended 状态下,可以切换到第 m 个 Warp 下发 b 指令,等到第 n 个 Warp 的 a 指令执行完成后,又可以下发 a+1 指令。由于同时存在多个 Warp 下发执行,这样就可以进行指令 latency 的隐藏,提高计算并行度。
SIMT 代码编译
介绍完 SIMT 代码的硬件执行逻辑,这里以 CUDA 为例介绍 SIMT 代码的编译流程。CUDA 的官方编译流程,主要包括 PTX 和 SASS 两个阶段,如下图所示:

图3 CUDA编译流程
其中 cicc 编译阶段主要实现 PTX 的编译,包括 PTX 指令选择、Generic 地址空间推导、指令调度等。ptxas 编译阶段主要实现硬件指令 SASS 的编译,包括寄存器分配、指令调度、divergence 处理、指令依赖关系处理(fix latency 和 variable latency 指令分开处理)等。
由于 PTX 指令集开源,LLVM 社区维护了 NVPTX 后端实现,可以完成 CUDA 到 PTX 的 CICC 编译。这边整理了下 NVPTX 的编译流程中的关键 pass,如下图所示。可以看到,该编译流程核心实现了 PTX 的指令选择,并没有实现寄存器分配、divergence 等复杂逻辑。
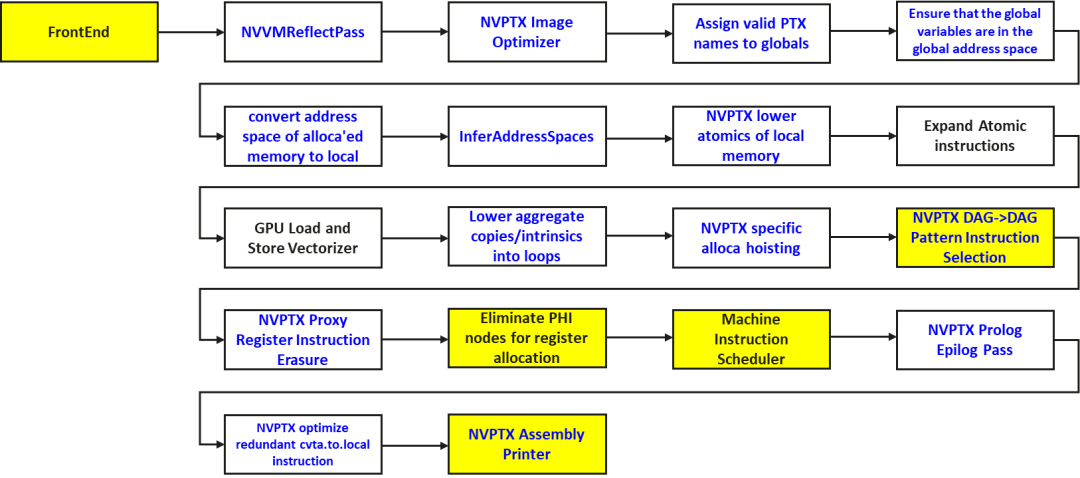
图4 LLVM NVPTX后端编译流程
结语
在高性能计算领域,相比 SIMD 的编程,SIMT 由于其编程的易用性,生态蓬勃发展。
本文以 CUDA 为例,简单介绍了下 SIMT 的硬件指令在硬件上的执行逻辑,通过 Warp 间的隐藏实现代码的并行执行。
由于 SIMT 是标量编程,所以编译流程遵循传统的标量编译流程方案。不过由于硬件本身是多线程的并行执行,特别需要处理的是 divergence 及指令依赖关系的逻辑。
参考
https://www.techpowerup.com/gpu-specs/docs/nvidia-gtx-750-ti.pdf
User Guide for NVPTX Back-end — LLVM 19.0.0git documentation
CUDA Toolkit Documentation 12.5
转载自鲲鹏社区:https://www.hikunpeng.com/zh/developer/techArticles/20231127-10















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









