







项目地址:https://github.com/spicymelon1/bart/tree/master
引言
自然语言生成(NLG)是自然语言处理(NLP)领域的重要研究方向之一。近年来,随着深度学习技术的发展,尤其是预训练语言模型的兴起,NLG任务取得了显著进展。BART模型作为一种强大的生成式模型,因其独特的双向编码器和自回归解码器结构,以及高效的去噪自编码器训练方式,成为了许多生成任务的首选模型。本文首先会对相关概念做一个介绍,然后通过一个具体的NLG任务项目,详细介绍如何使用BART模型进行文本生成,并通过代码示例展示实现过程,整个项目是一个完整的NLG流程:1. 数据处理 → 2. 词表处理 → 3. 预训练 → 4. 微调 → 5. 推理。
一、项目背景与目标
随着医疗影像技术的快速发展,计算机断层扫描(CT)已成为临床诊断中不可或缺的工具。CT扫描能够提供人体内部结构的详细图像,帮助医生发现病变、评估病情并制定治疗方案。然而,CT扫描产生的大量数据需要专业的放射科医生进行解读,这在医疗资源紧张的情况下可能导致诊断效率降低。
自然语言生成(NLG)技术在医疗领域的应用,尤其是在自动生成诊断报告方面,展现出巨大的潜力。通过NLG技术,可以从CT扫描的原始数据中自动生成描述性文本,辅助医生快速理解和总结影像学发现,从而提高诊断效率和准确性。
本项目旨在开发一个基于NLG技术的系统,该系统能够自动从CT扫描的影像表现中生成医生描述。项目的主要模块包括数据处理、模型训练、模型验证和推理等部分。

二、BART模型简介
BART(Bidirectional and Auto-Regressive Transformers)是自然语言处理领域用于文本生成任务(如图像描述、摘要生成、机器翻译等)的深度学习模型,其设计核心是结合双向编码器和自回归解码器的Transformer架构。它利用双向Transformer编码器捕获输入文本上下文信息,自回归Transformer解码器生成输出文本,并采用去噪自编码器框架,通过文本扰动(如删除、遮盖、替换等)破坏输入文本,训练模型恢复原始文本,以此提升模型的生成能力和鲁棒性,综合了BERT和GPT的优势。 有关BART模型的具体介绍,之后会写在另一篇文章中。
三、数据预处理
打开数据文件,可以看到最开始只有train.csv和test.csv两个文件,分别打开两个文件,会发现train.csv中有三列,第一列是id,第二列是ct描述,第三列是医生描述。test.csv中只有两列,没有医生描述这一列,这一列就是要给模型预测的。这里不是句子而是数字是因为官方给出的数据集已经做了脱敏处理。


3.1 数据处理
由于原始数据集是没有验证数据的,所以我们要把原来的测试集数据划分成测试集和验证集两部分,这次我们使用pandas中的sample采样方法来抽取90%的数据当作测试集,剩下的10%当作验证集。
代码实现:
pre_train_file= "data/train.csv"
train_df = pd.read_csv(pre_train_file,header=None,names=["id","input","tgt"]) #读入数据
# 划分训练集和验证集
train_data = train_df.sample(frac=0.9, random_state=0, axis=0) #frac采样比例、random_state随机种子、axis轴
val_data = train_df[~train_df.index.isin(train_data.index)] #train_data.index是取到的数据的下标,train_df.index是全部数据的下标,isin包含,~取反。包含了train_df中不在train_data中的所有行,也就是剩余的10%
# 将数据集保存为csv文件
train_data.to_csv("data/pro_train_data.csv", index=False,header=False)
val_data.to_csv("data/pro_val_data.csv", index=False,header=False)


3.2 词表处理
在处理数据集中的数字时,我们需要将这些数字转换为模型可以理解的输入格式(input_ids)。然而,由于官方数据集中的数字与我们自己的词表(vocabulary)可能不对应,我们需要对词表进行处理。有以下三种思路:
- 直接数字当id:这种方法是将数据集中出现的每个数字直接映射为一个唯一的id。这种方法简单直接,但这种方法的问题是,无法确保数据集中的数字含义和词表一一对应,训练出来的模型效果欠佳。
- 直接加字:这种方法是将数字作为新的词汇添加到词表中。这样可以确保数据集中的所有数字都能被模型识别。但是,如果数据集中的数字变化很大或者有很多未见过的数字,这种方法可能会导致词表过大,影响模型的泛化能力。
- 重新制作词表:这种方法是只将数据集中实际出现的数字加入到词表中,而不是将所有可能的数字都加入。这样可以减少词表的大小,同时确保模型能够处理数据集中的所有数字。这种方法需要对数据集进行分析,确定哪些数字是实际需要的,然后根据这些数字重新构建词表。
综合来看,决定使用第三种方法,它只包含实际出现的数字,可以避免不必要的复杂性,能够更好地平衡词表的大小和模型的泛化能力。
代码实现:
# 1、读数据
train_data = load_data('./data/train.csv')
# 2、统计所有出现过的数字
token2count = Counter() #计数工具 哈希表
for i in train_data:
token2count.update(i)
# 把数字从count中取出来变成列表
tail = []
ct = 0 #阈值
for k, v in token2count.items():
if v >= ct: #超过阈值就加入列表
tail.append(k)
tail.sort()
vocab = tail
# 3、处理词表:建立自己的词表
vocab.insert(0,"[PAD]")
vocab.insert(100,"[UNK]")
vocab.insert(101,"[CLS]")
vocab.insert(102,"[SEP]")
vocab.insert(103,"[MASK]")
vocab.insert(104,"[EOS]")
new_vocabs = vocab
# 4、保存新的词表
with open(args.pre_model_path+'/vocab.txt', 'w', encoding='utf-8') as f: #词表在mybart_base_chinese下面
for v in new_vocabs:
f.write(f"{v}\n") #保存
# 5、更新模型
model = BartForConditionalGeneration.from_pretrained(args.pre_model_path) #原模型Embedding(1297, 768),表示词汇表大小为 1297,lm_head(768, 1297)
model.resize_token_embeddings(len(new_vocabs)) #新模型Embedding(51440, 768),表示词汇表大小为 51440,lm_head(768, 51440)
state_dict = model.state_dict()
torch.save(state_dict, args.pre_model_path+'/pytorch_model.bin') #保存新模型
bartconfig = BartConfig.from_pretrained(args.pre_model_path)
bartconfig.vocab_size = len(new_vocabs)
bartconfig.save_pretrained(args.pre_model_path)
3.3 数据转换
由于测试数据的特殊性,虽然我们得到的数据是数字的形式,但实际上它们是很多句话,所以我们模型的输入是token,输出也是token,但是我们需要的是字符串,并且在模型评估阶段要求的输入也是字符串,所以我们要把模型的输出和标签都转成字符串的形式。
1. validate 函数:
res.append({'image_id': tot, 'caption': [array2str(pred[i], args)]})
gts[tot] = [array2str(targets[i][1:], args)]
这里调用了 array2str 函数对 pred[i] 和 targets[i][1:] 进行数据转换。pred[i] 是模型预测得到的数组,targets[i][1:] 是目标标签数组,通过 array2str 函数将它们转换为字符串形式,之后将转换后的字符串添加到 res(预测结果存储列表)和 gts(真实标签存储字典) 中,以便后续使用 CiderD_scorer 计算相似度。
2. inference 函数:
writer.writerow([tot, array2str(pred[i][2:], args)])
在推理过程里,把模型预测结果 pred[i][2:] 通过 array2str 函数转换为字符串形式,然后将其写入到 CSV 文件里,这里同样进行了从数组到字符串的数据转换操作。
四、模型训练与微调
处理完数据后,我们要进行模型的预训练、微调过程。先是使用处理后的训练数据进行预训练,保存预训练模型权重;然后在预训练的基础上,使用训练集和验证集进行微调,保存最优模型权重。
4.1 预训练
大型的预训练模型是在大量的网络数据上面进行的,但是模型没有见过我们的数据集,所以在使用之前我们要使用自己的数据集再做一次预训练。预训练之前要解决两个问题:1、预训练的数据从哪来?2、哪些数据可以用来预训练?哪些不能?
1、预训练的数据从哪来?前面我们已经保存了处理好的数据,这些数据就是预训练的数据来源。
2、哪些数据可以用来预训练?哪些不能?训练集的x、y,验证集和测试集的x可以用来预训练,验证集的y不能用来预训练。
明确了这几点之后我们就可以从数据、模型与训练模块着手进行代码实现了。
1. 数据部分
all_data = loadData(args.data_path) #加载所有数据
train_MLM_data = MLM_Data(all_data, args) #数据转换
train_dataloader = DataLoader(train_MLM_data, batch_size=args.batch_size, shuffle=True,collate_fn=train_MLM_data.collate) #创建了训练数据集
2. 模型部分
model = preModel(args) #加载预训练模型
optimizer, scheduler = build_optimizer(args, model) #优化器设置,学习率调整
3. 训练部分
# 开始进行训练,遍历指定的最大轮数 args.max_epochs
for epoch in range(args.max_epochs):
for batch in train_dataloader: # 对于每个 epoch,遍历训练数据加载器中的每个批次
model.train()
loss = model(batch) # batch 是一个包含数据的列表,调试时可以看到其长度为 4
loss = loss.mean()
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
# 每完成一个批次的训练,step 加 1
step += 1
if step % args.print_steps == 0:
time_per_step = (time.time() - start_time) / max(1, step)
remaining_time = time_per_step * (num_total_steps - step)
remaining_time = time.strftime('%H:%M:%S', time.gmtime(remaining_time))
logging.info(f"Epoch {epoch} step {step} eta {remaining_time}: loss {loss:.3f}") # 记录当前 epoch、步数、剩余时间和损失值的信息
logging.info(f"VAL_Epoch {epoch} step {step}: loss {loss:.3f}") # 每个 epoch 结束后,记录当前 epoch、步数和损失值的信息
# 预训练不进行验证,并且每 5 个 epoch 保存一次模型
if epoch % 5 == 0:
torch.save({'epoch': epoch, 'model_state_dict': model.module.state_dict()},
f'{args.savedmodel_path}/lr{args.learning_rate}epoch{epoch}loss{loss:.3f}pre_model.bin')
4.2 微调
微调是在预训练模型的基础上,针对特定任务进行进一步训练。
1. 数据部分
train_dataloader, val_dataloader = create_dataloaders(args) #加载数据
2. 模型部分
model = myModel(args)
#是否使用预训练模型,如果还没有预训练就设为false
use_pre = True #已经训练过了就设为True
if use_pre: #加载预训练过的模型
print('use_pre')
checkpoint = torch.load(args.my_pre_model_path, map_location='cpu')
new_KEY = model.load_state_dict(checkpoint['model_state_dict'],strict=True) #strict=True,表示在加载模型权重时,要求模型的结构与预训练模型的结构完全一致
optimizer, scheduler = build_optimizer(args, model)
model = model.to(args.device)
3. 训练(和验证)部分
#进入训练!!!
model.train()
#-------------------------------
step = 0
best_score = args.best_score #评估指标,类似分类任务里面的准确率
for epoch in range(args.max_epochs):
for (source, targets) in tqdm(train_dataloader): #读数据
source = source.cuda()
targets = targets.cuda() #targets 最初是 torch.Tensor 对象
# 训练模式
model.train()
pred = model(source[:, :args. input_l], targets[:, :args.output_l]) #得到预测值,source[:, :args. input_l]的第一个":"是样本数,第二个":"是输入长度不能超过input_l
loss = CE(pred[:, :-1], targets[:, 1:]) #求loss,targets里面去掉第一个(调试可以看到每个target第一个都是101,这是之前补的,所以要去掉),pred里面去掉最后一个(因为target和pred的长度要一致,而且最后一个一般都是padding这种,所以去掉最后一个)
loss = loss.mean() #多卡训练取均值
loss.backward() #loss回传
optimizer.step()
model.zero_grad()
scheduler.step()
step += 1
# 验证
if epoch % 1 == 0: #恒成立:每一轮都要做验证
cider_score = validate(model, val_dataloader, args)
logging.info(f"Epoch {epoch} step {step}: loss {loss:.3f}, cider_score {cider_score}")
if cider_score >= best_score:
best_score = cider_score
torch.save({'epoch': epoch, 'model_state_dict': model.state_dict()},
f'{args.savedmodel_path}/model_epoch_{epoch}_cider_score_{cider_score}.bin')

五、结果评估
在图像描述任务中,有许多常用的评估指标,如基于 n - 元组匹配的指标的BLEU和ROUGE、基于语义理解的指标的METEOR和SPICE、基于嵌入空间的指标的WMD和Embedding - based Similarity以及综合性较强的CiderD,在这次项目中,我们将使用CiderD作为评估指标。
5.1 CiderD概述
CiderD(Consensus-based Image Description Evaluation with Diversity)是一种用于评估图像描述生成质量的指标,通过计算真实文本与预测文本的相似度来评估模型性能,分数越高表示生成结果越接近真实文本。它在 Cider(Consensus-based Image Description Evaluation)的基础上进行了改进,考虑了描述的多样性。CiderD_scorer 是实现该评估指标的工具,常用于图像描述任务中评估生成的描述与参考描述之间的匹配程度和多样性。
代码实现
1. validate函数:
CiderD_scorer = CiderD(df='corpus', sigma=15) # 这一步就是把res和gts的描述求相似度
cider_score, cider_scores = CiderD_scorer.compute_score(gts, res)
这里首先创建了一个CiderD的评分器对象CiderD_scorer,并指定了参数df='corpus'和sigma=15,然后使用该评分器的compute_score方法计算gts和res之间的cider_score。
2. train_and_validate函数:
cider_score = validate(model, val_dataloader, args)
logging.info(f"Epoch {epoch} step {step}: loss {loss:.3f}, cider_score {cider_score}")
if cider_score >= best_score: # 不同3:注重验证过程中的 cider_score,并根据验证结果保存模型
best_score = cider_score
torch.save({'epoch': epoch, 'model_state_dict': model.state_dict()},
f'{args.savedmodel_path}/model_epoch_{epoch}_cider_score_{cider_score}.bin')
这里调用了validate函数获取cider_score,并根据cider_score的值来判断是否保存当前模型。
六、模型推理
推理模块主要是利用已经训练好的模型对测试数据进行预测,不需要进行模型的训练和参数更新,因此任务相对简单。它只需要加载模型、加载测试数据,然后将数据输入模型得到预测结果并保存即可。
1. 加载数据和模型
test_loader = create_dataloaders(args, test=True) #创建测试集
model = myModel(args) # 加载模型
checkpoint = torch.load(args.ckpt_file, map_location='cpu') # 加载模型的检查点
model.load_state_dict(checkpoint['model_state_dict'], strict=False)
model.to('cuda:0') # 将模型移动到GPU上
# 设置模型为评估模式
model.eval()
2. 模型推理和保存
# 遍历测试数据加载器
for source in tqdm(test_loader):
source = to_device(source, 'cuda:0') # 将数据移动到GPU上
pred = model(source) # 进行模型推理
pred = pred.cpu().numpy() # 将预测结果移动到CPU并转换为numpy数组
for i in range(pred.shape[0]):
writer.writerow([tot, array2str(pred[i][2:], args)]) # 将预测结果写入CSV文件
tot += 1
实际上直接在做模型推理的就是pred = model(source)这一句代码,其他都是关于数据、模型和保存文件的一些设置。推理只需要利用已经训练好的模型对测试数据进行预测,它的任务相对简单、数据处理和模型状态管理的复杂度较低,因此代码相对较短。
3. 结果展示
取一些数据来做个示例,每条数据是两列,第一列是每张图片的编号,第二列是模型生成的医生描述,同样是用阿拉伯数字表示的一句话,且每个结果的输出长度是不同的。

七、解决PyTorch的NVIDIA 驱动版本问题(CUDA)
我当时在模型微调时出现了报错:RuntimeError: The NVIDIA driver on your system is too old (found version 11050). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver.在网上搜了一下发现这个错误是由于我的系统中安装的 NVIDIA 驱动版本太旧,无法满足 PyTorch 对 CUDA 的要求。具体来说,PyTorch 需要一个较新的 NVIDIA 驱动版本来支持其 CUDA 功能,而我的系统中的驱动版本是一个较旧的版本。
以下是解决这个问题的两种方法:
方法 1:更新 NVIDIA 驱动
我是跟着这篇文章做的更新:【Windows】安装NVIDIA驱动 / 更新驱动
首先要找到自己电脑的显卡版本,我的显卡信息是这样子的:

然后去官网下载驱动GeForce® 驱动程序。在页面上选择你的 GPU 型号、操作系统版本等信息,然后下载最新的驱动程序。
再就是要安装下载好的驱动程序,我的NVIDIA驱动安装路径是这个:C:\NVIDIA\DisplayDriver\572.42\Win11_Win10-DCH_64\International。接着每一步我是和文章勾选的一样。
最后就是重启一下电脑,在终端输入nvidia-smi,看到自己的显卡驱动信息,就安装成功啦!

方法 2:安装与当前驱动兼容的 PyTorch 版本
如果你不想更新 NVIDIA 驱动,或者你的系统无法安装较新的驱动版本,可以试试这个方法。
之前没讲到位,后面我又装了一个新环境,可以跟着这篇文章来装,一次性把pytorch和torchvision的问题都解决,地址在这里:pythorch版本和torchvision版本对应关系及torchvision安装
首先要查看自己的CUDA版本,在python中输入:
import torch
print(torch.cuda.is_available()) # 检查 CUDA 是否可用
print(torch.version.cuda) # 打印 PyTorch 支持的 CUDA 版本
我的CUDA版本是12.1
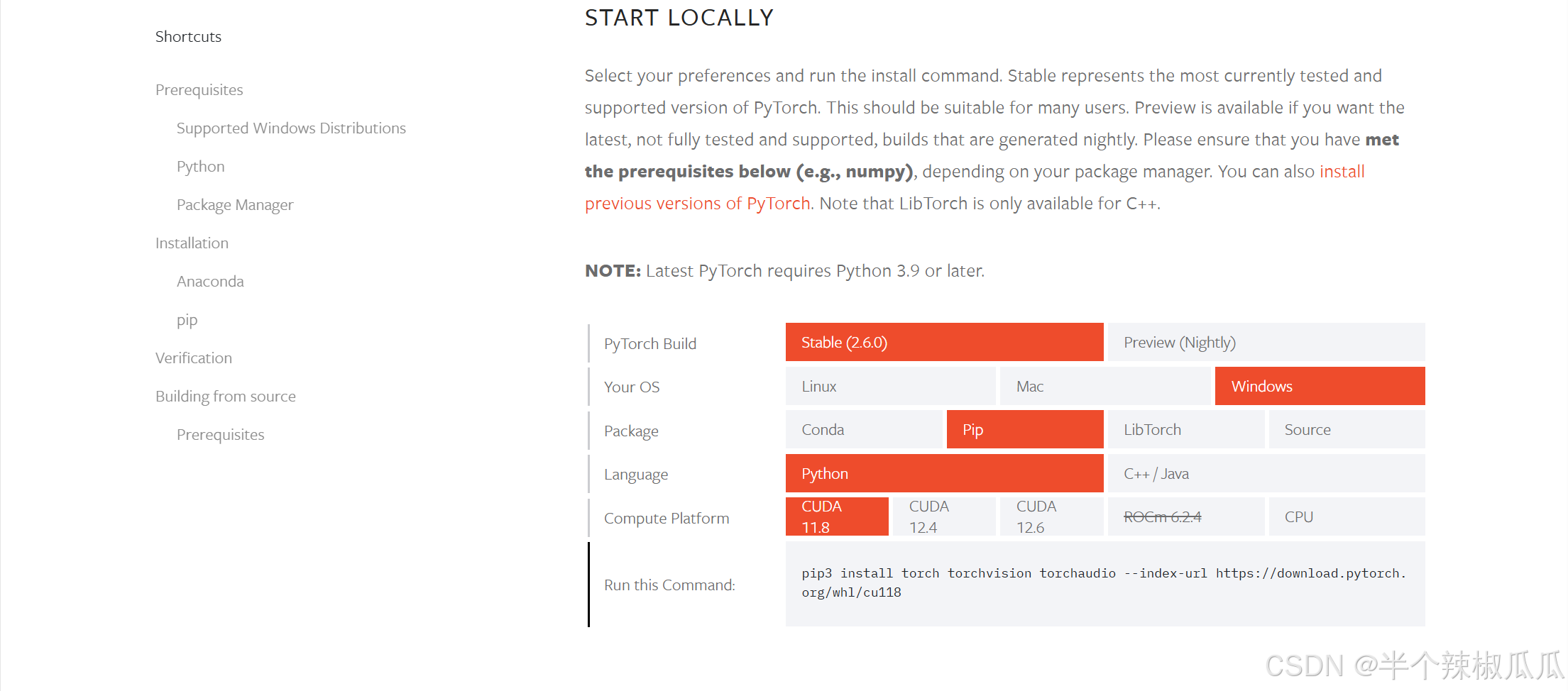
 然后访问 PyTorch 官方网站。在页面上找到“Get Started”部分,根据你的 CUDA 版本选择合适的 PyTorch 安装命令(貌似这里没有我的CUDA版本)。
然后访问 PyTorch 官方网站。在页面上找到“Get Started”部分,根据你的 CUDA 版本选择合适的 PyTorch 安装命令(貌似这里没有我的CUDA版本)。
使用提供的命令安装即可。


















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









