






多标签学习中的一些评价指标及python代码实现
- 写在前面
- 指标代码部分
- 指标公式原理部分
- Subset Accuracy
- Hamming Loss
- A c c u r a c y e x a m Accuracy_{exam} Accuracyexam, P r e c i s i o n e x a m Precision_{exam} Precisionexam, R e c a l l e x a m Recall_{exam} Recallexam, F e x a m β F^β_{exam} Fexamβ
- One-error
- Coverage
- Ranking Loss
- Average Precision
- Macro-averaging
- Micro-averaging
- A U C m a c r o AUC_{macro} AUCmacro
- A U C m i c r o AUC_{micro} AUCmicro
写在前面
允许我以小人之心度君子之腹一下,我相信很多人跟我当初一样–不想知道原理只需要代码,所以这篇帖子先给出代码(不想看原理直接拿去用,但不一定正确,省得看文字浪费时间)后面部分再介绍公式(不想看就省得往下翻了)。
注:也是我搜集来的,不敢保证正确性,仅供参考哈!!!
指标代码部分
很大一部分都是sklearn库中就有的
indicator1 = metrics.hamming_loss(y_true, y_pred) //1.Hamming Loss
indicator2 = (metrics.coverage_error(y_true, y_score) - 1) //2.Coverage
indicator3 = metrics.label_ranking_loss(y_true, y_score) //3.Ranking Loss
indicator4 = One_Error(y_true, y_score) //4.One Error,没有库函数,自己写的
indicator5 = metrics.label_ranking_average_precision_score(y_true, y_score) //5.Average Precision
indicator6 = metrics.zero_one_loss(y_true, y_pred) // 6.Zore One
indicator7 = metrics.accuracy_score(y_true=y_true, y_pred=y_pred) //7.Accuracy
indicator8 = metrics.precision_score(y_true=y_true, y_pred=y_pred, average='samples') //8.Presicion
indicator9 = metrics.recall_score(y_true=y_true, y_pred=y_pred, average='samples') // 9.Recall
indicator10 = metrics.f1_score(y_true, y_pred, average='samples') // 10.F1
indicator11 = metrics.precision_score(y_true, y_pred, average='micro') // 11.Precision
indicator12 = metrics.recall_score(y_true, y_pred, average='micro') // 12.Recall
indicator13 = metrics.f1_score(y_true, y_pred, average='micro') // 13.F1
indicator14 = metrics.precision_score(y_true, y_pred, average='macro') // 14.Precision
indicator15 = metrics.recall_score(y_true, y_pred, average='macro') // 15.Recall
indicator16 = metrics.f1_score(y_true, y_pred, average='macro') //16.F1
try:
// 因为会报错,所以我加了一个try
// 错误信息:ValueError: Only one class present in y_true. ROC AUC score is not defined in that case.
indicator17 = metrics.roc_auc_score(y_true, y_score, average='micro') //17.AUC
except ValueError:
pass
try:
indicator18 = metrics.roc_auc_score(y_true, y_score, average='macro') // 18.AUC
except ValueError:
pass
这些公式与图中的对应如下(按照我自己的理解进行对应的)
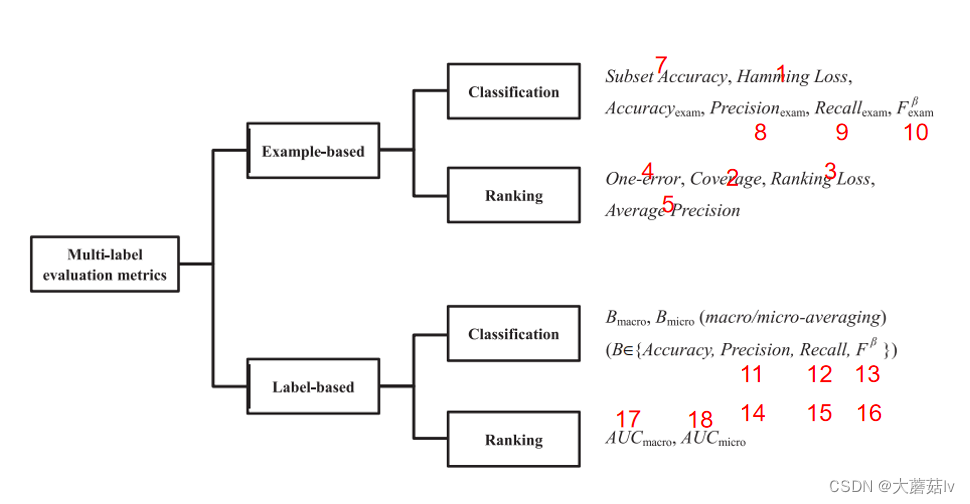
其中accuracy的没有找到关于样本和关于macro、micro的库函数。
上图来自论文A Review on Multi-Label Learning Algorithms,感兴趣的同学可以直接去看原文,接下来介绍的公式也是出自原文。
指标公式原理部分
S = { ( x i , Y i ) ∣ 1 ≤ i ≤ p } 表示测试集, h ( ⋅ ) 代表学习的多标签分类器。 S = \{(x_i,Y_i)|1\leq i \leq p\} 表示测试集,h(\cdot)代表学习的多标签分类器。 S={(xi,Yi)∣1≤i≤p}表示测试集,h(⋅)代表学习的多标签分类器。
Subset Accuracy
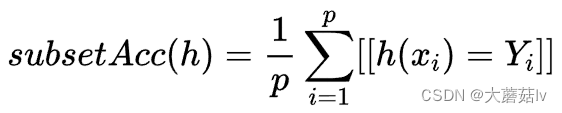
Hamming Loss
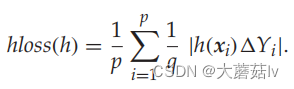
A c c u r a c y e x a m Accuracy_{exam} Accuracyexam, P r e c i s i o n e x a m Precision_{exam} Precisionexam, R e c a l l e x a m Recall_{exam} Recallexam, F e x a m β F^β_{exam} Fexamβ
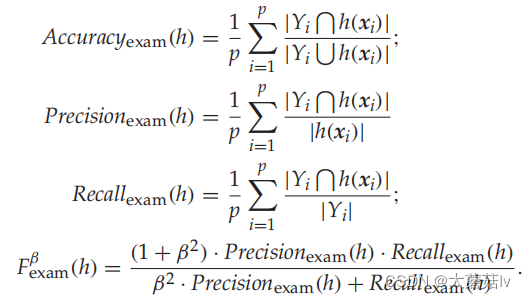
One-error
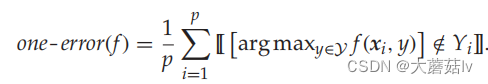
Coverage
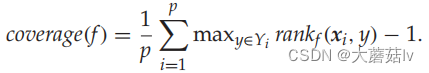
Ranking Loss
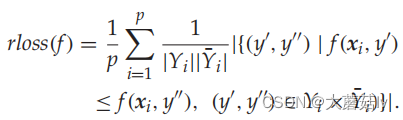
Average Precision
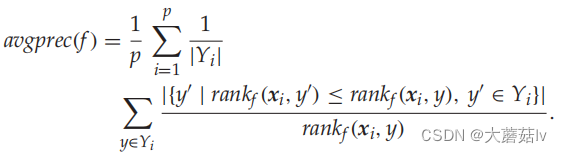
对于第j类标签
y
j
y_j
yj,可以基于
h
(
⋅
)
h(\cdot)
h(⋅)定义表征该标签上的二进制分类性能的四个基本量:
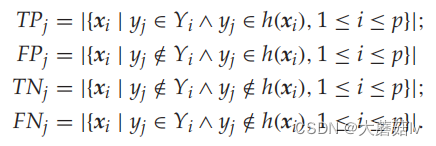
Macro-averaging
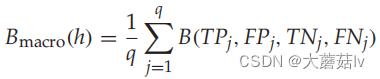
Micro-averaging
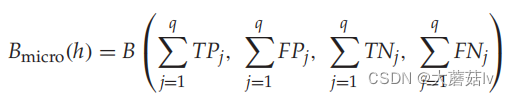
A U C m a c r o AUC_{macro} AUCmacro
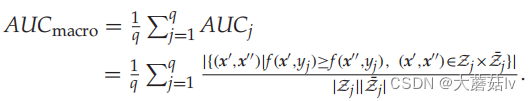
A U C m i c r o AUC_{micro} AUCmicro
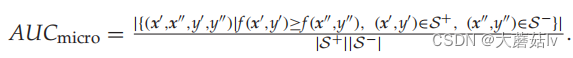
其中,
S
+
=
{
(
x
i
,
y
)
∣
y
∈
Y
i
,
1
≤
i
≤
p
}
,
S
−
=
{
(
x
i
,
y
)
∣
y
∉
Y
i
,
1
≤
i
≤
p
}
S^+=\{(x_i,y)|y\in Y_i,1 \leq i \leq p\},S^-=\{(x_i,y)|y\notin Y_i,1 \leq i \leq p\}
S+={(xi,y)∣y∈Yi,1≤i≤p},S−={(xi,y)∣y∈/Yi,1≤i≤p}
再次强调,只是把搜集来的内容分享给需要的同学,不保证正确性,仅供参考交流,论文数据需要严谨,确保正确性之后再使用。














 7713
7713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









