







Subset accuracy

hamming loss
- 该指标用于考察样本在单个标记上的误分类情况,即隶属于该样本的概念标记未出现在标记集合中而不隶属于该样本的概念标记出现在标记集合中。

其中$h(x_i)$输出一个示例的二元标记向量,
$\Delta$表示两个二元0/1向量的求异操作
one-error
- 该指标用于考察在样本的概念标记排序序列中,序列最前端的标记不属于相关标记集合的情况。 该指标取值越小越好。
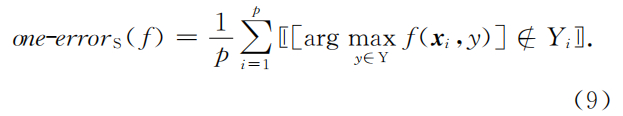
coverage
- 该指标用于考察在样本的类别标记排序序列中,覆盖隶属于样本的所有类别标记所需要的搜索深度情况。
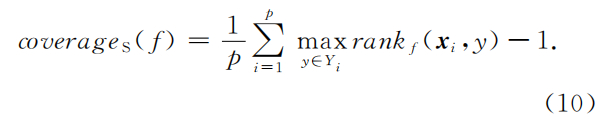
ranking loss
- 该指标用于考察在样本的类别标记排序序列中出现排序错误的情况。即无关标记在排序序列中位于相关标记之前。
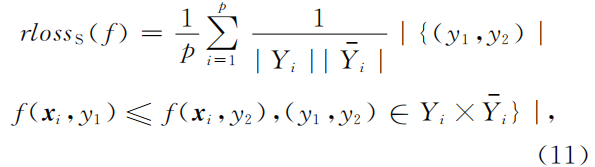

average precision
- 该指标用于考察在样本的概念标记排序序列中,排在隶属于该样本的概念标记之前的标记仍属于样本标记集合的情况。
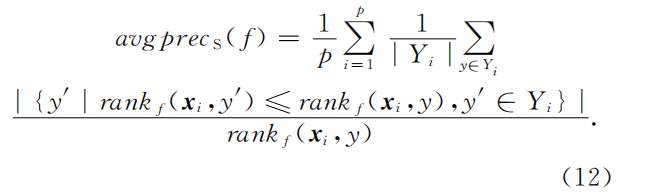
总结
- 对于前四种评价指标(hamming loss、one-error、coverage、ranking loss)而言,指标越小则算法性能越优;
- 对于最后一种评价指标(average precision)而言,指标取值越大则算法性能越优
摘自:多标签数据挖 掘技术 : 研究综述






















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









