





 该研究提出了一种通用的多关系学习框架,涵盖NTN和TransE等模型。通过双线性模型在链接预测任务上取得优秀效果,并提出了一种基于表示学习的逻辑规则挖掘算法,该算法在实验中优于AMIE系统。实验表明,简单的模型可能优于复杂的模型,预训练的实体向量能提升性能,而单词向量可能造成负面影响。此外,还讨论了如何利用实体类型减少规则挖掘的搜索空间。
该研究提出了一种通用的多关系学习框架,涵盖NTN和TransE等模型。通过双线性模型在链接预测任务上取得优秀效果,并提出了一种基于表示学习的逻辑规则挖掘算法,该算法在实验中优于AMIE系统。实验表明,简单的模型可能优于复杂的模型,预训练的实体向量能提升性能,而单词向量可能造成负面影响。此外,还讨论了如何利用实体类型减少规则挖掘的搜索空间。
embedding entities and relations for learning and inference knowledge base 解读
来源
ICLR 2015 微软研究院 和 康奈尔大学
背景
目前很多研究工作致力于大型知识图谱上的关系学习,其中张量分解以及神经网络embedding方法是其中重要的两种方法。这些表示学习的方法可以应用到知识图谱的推理任务上,用于发现一些没有在知识库中的事实。本文主要考虑的是基于神经网络的embedding 的方法,在过去的研究工作中,典型的方法有TransE、NTN(neural tensor network)等, 这些方法的区别在于实体以及关系的表示方法。基于表示学习的方法是将实体以及关系嵌入到低维向量中,来刻画潜在的语义关系。表示学习方法通常存在可解释性差的问题,对于提取的关系特征以及在embedding过程中关系属性提取的程度。
本文的贡献
- 本文提出了一个一般化的多关系学习框架,涵盖了NTN、TransE等经典模型
- 在这个一般化表示的框架下,通过选择不同的实体以及关系表示,在链接预测任务上进行了表示,一个简单的双线性模型取得了最好的结果
- 提出了一个基于表示学习方法的逻辑规则挖掘算法,这些逻辑规则可以通过组合关系embedding方法得到,通过矩阵乘法来提取组合关系的语义。
- 本文的逻辑规则挖掘算法优于规则挖掘系统AMIE
一般化的多关系学习框架
实体表示:
y
e
1
=
f
(
W
x
e
1
)
y_{e_{1}} = f(Wx_{e_1})
ye1=f(Wxe1),
y
e
2
=
f
(
W
x
e
2
)
y_{e_{2}} = f(Wx_{e_2})
ye2=f(Wxe2),
f
f
f是一个线性或者非线性的函数,
W
W
W是一个随机初始化或者预训练的参数矩阵,
e
1
e_1
e1和
e
2
e_2
e2是实体的向量表示,可以是one-hot表示,或者是实体中单词表示的平均值(NTN 模型)
关系表示:
线性表示
g
r
a
(
y
e
1
,
y
e
2
)
=
A
r
T
(
‘
y
e
1
‘
‘
y
e
2
‘
)
g^a_r(y_{e_1}, y_{e_2}) =A^T_r \begin{pmatrix} `y_{e_1}` \\ `y_{e_2}` \end{pmatrix}
gra(ye1,ye2)=ArT(‘ye1‘‘ye2‘),
双线性表示:
g
r
b
(
y
e
1
,
y
e
2
)
=
y
e
1
T
B
r
y
e
2
g^b_r(y_{e_1}, y_{e_2}) =y^T_{e_1}B_ry_{e_2}
grb(ye1,ye2)=ye1TBrye2
目前一些方法中关系的表示以及打分函数:

其中NTN是提取特征能力最强的模型,融合了线性表示以及双线性表示,在本文中考虑一个基本的双线性打分函数
g
r
b
(
y
e
1
,
y
e
2
)
=
y
e
1
T
M
r
y
e
2
g^b_r(y_{e_1}, y_{e_2}) =y^T_{e_1}M_ry_{e_2}
grb(ye1,ye2)=ye1TMrye2
M
r
M_r
Mr是一个对角矩阵
参数学习
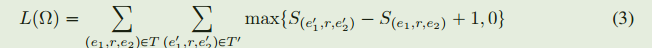
其中
T
T
T 表示正例集合,
T
′
T^{\prime}
T′表示负例集,是通过破坏头实体或者尾实体得到的三元组集合
S
(
)
S()
S()是打分函数,目标函数是最小化上面公式(3)
实验部分
本节将考虑基于上面表示学习的方法,用于链接预测任务上。
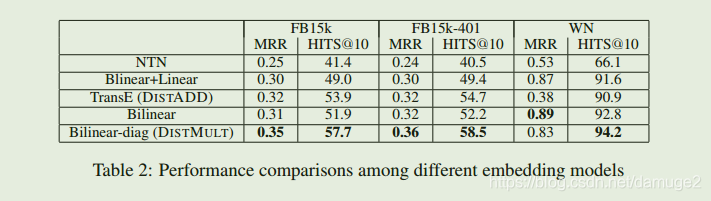
上述表格中发现简单的模型取得了更好的效果,说明模型过拟合了。Bilinear-diag 模型不能编码关系以及逆关系的取别。

DISTMULT基本在各种类型的关系上都优于DISTADD模型
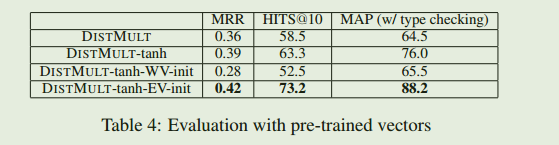
上面实验考虑预训练的向量对结果的影响,发现实体级的预训练向量有利于提升实验的性能,但是单词级的预训练向量往往起到不好的作用,原因是和数据集有较大关系,在FB15k-401数据集中,73%的实体是姓名、地点、机构和电影名等等,因此我们怀疑这是因为单词向量不适合非组合短语描述的实体建模。
推理任务
这个小节,本文研究根据学习到的embedding进行逻辑规则的挖掘,举个列子如下: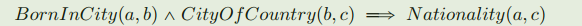
抽取这样逻辑规则的关键问题是高效的搜索空间,传统的规则挖掘的方法直接在知识图谱上通过剪枝掉一些相关度低的路径,但是这样的方法受限于搜索空间在大型知识图谱上是不合适的。本文提出基于embedding的方法和知识图谱的规模无关,和关系的数量有关,因此具有更广泛的意义。
通常实体有自己的类型,一个关系适用的实体通常只是部分实体类型,因此可以使用实体类型作为约束条件来减少搜索空间。

提出上述基于embedding的逻辑规则抽取算法,很容易理解,4-6行中找到整个路径空间, 7-8 行根据距离约束对候选规则进行过滤。
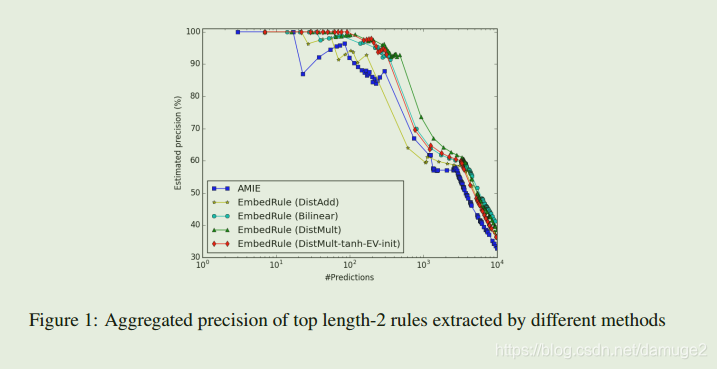
横坐标表示topK rules, EmbedRule 都取得了很好的效果,相对于AMIE。EMbedRule(DistMult)取得了比EmbedRule(DistAdd)更好的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









