







一、分词方法
关于中文分词 参考之前写的jieba分词源码分析 jieba中文分词。
中文分词算法大概分为两大类:
一是基于字符串匹配,即扫描字符串,使用如正向/逆向最大匹配,最小切分等策略(俗称基于词典的)
基于词典的分词算法比较常见,比如正向/逆向最大匹配,最小切分(使一句话中的词语数量最少)等。具体使用的时候,通常是多种算法合用,或者一种为主、多种为辅,同时还会加入词性、词频等属性来辅助处理(运用某些简单的数学模型)。
这类算法优点是速度块,时间复杂度较低,实现简单,文中介绍的mmseg属于这类算法。二是基于统计以及机器学习的分词方式(非词典方法)
一般主要是运用概率统计、机器学习等方面的方法,目前常见的是CRF,HMM等。
这类分词事先对中文进行建模,根据观测到的数据(标注好的语料)对模型参数进行估计(训练)。 在分词阶段再通过模型计算各种分词出现的概率,将概率最大的分词结果作为最终结果。
有关HMM可以参见之前写的 jieba HMM。CRF分词可以参考 这里。
这类算法对未登录词识别效果较好,能够根据使用领域达到较高的分词精度,但是实现比较复杂,通常需要大量的前期工作。
二、mmseg算法
下面介绍下mmseg算法:
mmseg算法
使用过mmseg算法的童鞋都反映其简单、高效、实用、效果还不错,参考论文 mmseg,
其主要思想每次从一个完整的句子里,按照从左向右的顺序,识别出多种不同的3个词的组合,然后根据下面的4条消歧规则,确定最佳的备选词组合。
选择备选词组合中的第1个词,作为1次迭代的分词结果;剩余的词(即这个句子中除了第一个已经分出的词的剩余部分)继续进行下一轮的分词运算。采用这种办法的好处是,为传统的前向最大匹配算法加入了上下文信息,解决了其每次选词只考虑词本身,而忽视上下文相关词的问题。 mmseg论文中说明了(The Maximum Matching Algorithm and Its Variants)Maximum Matching Algorithm的两种方法:
1. Simple方法,即简单的正向匹配,根据开头的字,列出所有可能的结果。比如“国际化大都市”,可以得到:
国
国际
国际化
…
这三个匹配结果(假设这四个词都包含在词典里)。
2. Complex方法,匹配出所有的“三个词的词组”(即原文中的chunk,“词组”),即从某一既定的字为起始位置,得到所有可能的“以三个词为一组”的所有组合。比如“研究生命起源”,可以得到
研_究_生
研_究_生命
研究生_命_起源
研究_生命_起源
这些“词组”(根据词典,可能远不止这些,仅此举例)。
四个规则
消除歧义的规则”有四个,使用中依次用这四个规则进行过滤,直到只有一种结果或者第四个规则使用完毕,4条消歧规则包括:
1. 备选词组合的长度之和最大(Maximum matching (Chen & Liu 1992));
2. 备选词组合的平均词长最大(Largest average word length (Chen & Liu, 1992));
3. 备选词组合的词长变化最小(Smallest variance of word lengths (Chen & Liu, 1992));
4. 备选词组合中,单字词的出现频率统计值最高(取单字词词频的自然对数,然后将得到的值相加,取总和最大的词)(Largest sum of degree of morphemic freedom of one-character words)。
下面分别举例说明一下4个规则:
备选词组合的长度之和最大(Maximum matching (Chen & Liu 1992))
有两种情况,分别对应于使用“simple”和“complex”的匹配方法。对“simple”匹配方法,选择长度最大的词,用在上文的例子中即选择“国际化”;
对“complex”匹配方法,选择“词组长度最大的”那个词组,然后选择这个词组的第一个词,作为切分出的第一个词,如上文 的例子中即“研究生_命_起源”中的“研究生”,或者“研究_生命_起源”中的“研究”。
对于有超过一个词组满足这个条件的则应用下一个规则。备选词组合的平均词长最大(Largest average word length (Chen & Liu, 1992))
经过规则1过滤后,如果剩余的词组超过1个,那就选择平均词语长度最大的那个(平均词长=词组总字数/词语数量)。比如“生活水平”,可能得到如下词组:
生_活水_平 (4/3=1.33)
生活_水_平 (4/3=1.33)
生活_水平 (4/2=2)
根据此规则,就可以确定选择“生活_水平”这个词组。
对于上面的 “研究生命起源” 结果:”研究生_命_起源“ “研究_生命_起源” 利用rule2有
研究生_命_起源 (6/3=2)
研究_生命_起源 (6/3=2)
可见这条规则没有起作用,因为两者平均长度相同。论文中也有说明:
This rule is useful only for condition in which one or more word position in the chunks are empty. When the chunks are real three-word chunks, this rule is not useful. Because three-word chunks with the same total length will certainly have the same average length. Therefore we need another solution.备选词组合的词长变化最小(Smallest variance of word lengths (Chen & Liu, 1992))
由于词语长度的变化率可以由标准差反映,所以此处直接套用标准差公式即可。比如 对于上面的case “研究生命起源”有:
研究_生命_起源 (标准差=sqrt(((2-2)^2+(2-2)^2+(2-2^2))/3)=0)
研究生_命_起源 (标准差=sqrt(((2-3)^2+(2-1)^2+(2-2)^2)/3)=0.8165)
于是通过这一规则选择“研究_生命_起源”这个词组。备选词组合中,单字词的出现频率统计值最高(Largest sum of degree of morphemic freedom of one-character words)
这里的degree of morphemic freedom可以用一个数学公式表达:log(frequency),即词频的自然对数(这里log表示数学中的ln)。这个规则的意思是“计算词组中的所有单字词词频的自然对数,然后将得到的值相加,取总和最大的词组”。比如:
“设施和服务”,这个会有如下几种组合
设施_和服_务_
设施_和_服务_
设_施_和服_
经过规则1过滤得到:
设施_和服_务_
设施_和_服务_
规则2和规则3都无法得到唯一结果,只能利用最后一个规则 第一条中的“务”和第二条中的“和”,从直观看,显然是“和”的词频在日常场景下要高,这依赖一个词频字典和的词频决定了的分词。
假设“务”作为单字词时候的频率是30,“和”作为单字词时候的频率是100,对30和100取自然对数,然后取最大值者,所以取“和”字所在的词组,即“设施_和_服务”。
也许会问为什么要对“词频”取自然对数呢?可以这样理解,词组中单字词词频总和可能一样,但是实际的效果并不同,比如
A_BBB_C (单字词词频,A:3, C:7)
DD_E_F (单字词词频,E:5,F:5)
表示两个词组,A、C、E、F表示不同的单字词,如果不取自然对数,单纯就词频来计算,那么这两个词组是一样的(3+7=5+5),但实际上不同的词频范围所表示的效果也不同,所以这里取自然对数,以表区分(ln(3)+ln(7) < ln(5)+ln(5), 3.0445<3.2189)。
这个四个过滤规则中,如果使用simple的匹配方法,只能使用第一个规则过滤,如果使用complex的匹配方法,则四个规则都可以使用。实际使用中,一般都是使用complex的匹配方法+四个规则过滤。(实际中complex用的最多)。
通过上面的叙述可以发现MMSEG是一个“直观”的分词方法。它把一个句子“尽可能长” && “尽可能均匀”(“尽可能长”是指所切分的词尽可能的长)的区切分,这与中文的语法习惯比较相符,其实MMSEG的分词效果与词典关系较大,尤其是词典中单字词的频率。可以根据使用领域,专门定制词典(比如计算机类词库,生活信息类词库,旅游类词库等,欢迎体验我狗的 细胞词库 ),尽可能的细分词典,这样得到的分词效果会好很多。
总的来说 MMSEG是一个简单、可行、快速的分词方法。
三、mmseg分词算法实现
有关mmseg的分词策略通过上面的介绍,大家有一定的认识了,其**主要**思想就是每次从一个完整的句子里,按照从左向右的顺序,识别出多种不同的3个词的组合(chunk),然后根据mmseg的4条消歧规则,确定最佳的备选词组合,选择备选词组合中的最佳词(即第1个词),作为1次迭代的分词结果;剩余的词(即这个句子中除了第一个已经分出的词的剩余部分)继续进行下一轮的分词运算。可以仔细阅读mmseg的论文,写的挺详细的。指导算法思路,下面来看下实现过程: mmseg分词所需要的工作分为下面几点:- 转码,string转换成utf16( unicode),以及逆转换。
关键部分,是分词的前提。因为每次进行分词前,都需要将string decode成utf16(unicode),分词完要输出的时候又需要将unicode encode成string。 因为在分词算法中,对于句子是按一个字一个字来计算和分词的。所以转换成unicode是完成分词算法的必要前提。转码部分利用了StringUtil.hpp的转码模块。 - trie字典树
将词库字典转换成trie树,从而可以进行高效查找。实现起来利用c++的数据结构unordered_map即可实现,详细参见代码。
mmseg实现起来采用了{.h, .cpp} and {.hpp} 两种组织方式,为什么采用hpp?
mmseg的主要目录结构如下:
mmseg
├── build : 生成*.so 动态链接库
├── data :词典数据
└── src : 实现源码
└── util : 字符串处理通用库
代码采用c++11实现(g++ version >= 4.8 is recommended),已有详细注释,不在敷述,请见源码。
https://github.com/ustcdane/mmseg 。
- 使用方法
在主程序中 如main.cpp
- 如果使用hpp格式的文件 即#include “src/Mmseg.hpp”,编译方式为:
g++ -Ofast -march=native -funroll-loops -o mmseg -std=c++11 main.cpp - 如果使用h格式的文件 即#include “src/Mmseg.h”,编译方式为:
g++ -Ofast -march=native -funroll-loops -o mmseg -std=c++11 main.cpp src/Mmseg.cpp
另外为了能够方便的在其他地方使用mmseg分词,也可以把这部分代码编译成*.so的动态链接库,进入目录build , 里面有已经写好的Makefile文件 直接make 即可生成 libmmseg.so的 动态链接库文件,从而方便在其它程序中调用。
- 如果使用hpp格式的文件 即#include “src/Mmseg.hpp”,编译方式为:
注意 为了更清楚的看mmseg的过程,我分别在 Mmseg.hpp 和 Mmseg.cpp中定义了宏
#define DEBUG_LEVEL , 如果不想看计算过程可以直接注释掉这一行代码。
四、测试结果
进入mmesg ,运行命令,编译main.cpp,生成mmseg可执行文件。
g++ -Ofast -march=native -funroll-loops -o mmseg -std=c++11 main.cpp src/Mmseg.cpp
运行mmseg即可测试,在我的机器上测试结果如下。
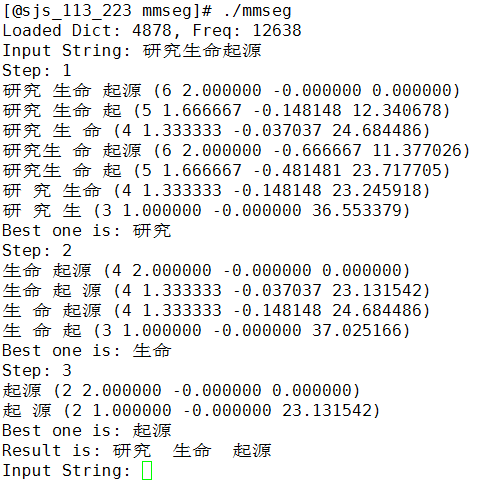
源码见: https://github.com/ustcdane/mmseg ,实现过程参考了 jdeng 关于mmseg的代码。艾玛,搞了一天终于写完。














 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









