





不停机与停机更新
软件世界的发展比以往任何时候都快。 为了保持竞争力,需要尽快推出新的软件版本,而又不影响活动用户。 许多企业已将工作负载转移到Kubernetes,Kubernetes的构建考虑了生产就绪性。 但是,为了使用Kubernetes实现真正的零停机时间而又不中断或丢失单个飞行请求,我们需要采取更多步骤。
这是关于如何使用Kubernetes入口和Istio网关资源实现(实际)零停机时间的两篇系列文章的第一部分。 这部分内容涵盖普通的Kubernetes。
滚动更新
默认情况下,Kubernetes部署具有滚动更新策略的滚动Pod版本更新。 该策略旨在通过在执行更新时的任何时间点保持至少一些实例的正常运行来防止应用程序停机。 只有在新部署版本的新Pod启动并准备好处理流量之后,才会关闭旧Pod。
工程师可以进一步指定Kubernetes在更新期间如何处理多个副本的确切方式。 根据我们可能要配置的工作负载和可用的计算资源,我们随时可能要配置多少个实例。 例如,给定三个所需的副本,我们是否应该立即创建三个新的Pod并等待它们全部启动,我们是否应该终止除一个之外的所有旧Pod,还是要一一过渡? 以下代码段显示了具有默认RollingUpdate升级策略的咖啡店应用程序的Kubernetes部署定义,并且在更新过程中最多可以有一个超额配置的pod( maxSurge ),并且没有不可用的pod。
kind: Deployment
apiVersion: apps/v1beta1
metadata:
name: coffee-shop
spec:
replicas: 3
template:
# with image docker.example.com/coffee-shop:1
# ...
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0 coffee-shop部署将导致创建coffee-shop:1的三个副本coffee-shop:1映像。
此部署配置将通过以下方式执行版本更新:它将一次创建一个具有新版本的Pod,等待Pod启动并准备就绪,触发其中一个旧Pod的终止,然后继续下一个新的Pod,直到所有副本都已转换。 为了告诉Kubernetes我们的Pod何时运行并准备处理流量,我们需要配置活动和就绪探针 。
以下显示了随着时间的推移kubectl get pods以及新旧kubectl get pods的输出:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
zero-downtime-5444dd6d45-hbvql 1/1 Running 0 3m
zero-downtime-5444dd6d45-31f9a 1/1 Running 0 3m
zero-downtime-5444dd6d45-fa1bc 1/1 Running 0 3m
...
zero-downtime-5444dd6d45-hbvql 1/1 Running 0 3m
zero-downtime-5444dd6d45-31f9a 1/1 Running 0 3m
zero-downtime-5444dd6d45-fa1bc 1/1 Running 0 3m
zero-downtime-8dca50f432-bd431 0/1 ContainerCreating 0 12s
...
zero-downtime-5444dd6d45-hbvql 1/1 Running 0 4m
zero-downtime-5444dd6d45-31f9a 1/1 Running 0 4m
zero-downtime-5444dd6d45-fa1bc 0/1 Terminating 0 4m
zero-downtime-8dca50f432-bd431 1/1 Running 0 1m
...
zero-downtime-5444dd6d45-hbvql 1/1 Running 0 5m
zero-downtime-5444dd6d45-31f9a 1/1 Running 0 5m
zero-downtime-8dca50f432-bd431 1/1 Running 0 1m
zero-downtime-8dca50f432-ce9f1 0/1 ContainerCreating 0 10s
...
...
zero-downtime-8dca50f432-bd431 1/1 Running 0 2m
zero-downtime-8dca50f432-ce9f1 1/1 Running 0 1m
zero-downtime-8dca50f432-491fa 1/1 Running 0 30s检测可用性差距
如果我们执行从旧版本到新版本的滚动更新,并按照输出显示哪些Pod处于活动状态并准备就绪,则该行为首先似乎是有效的。 但是,正如我们可能看到的那样,从旧版本到新版本的切换并不总是十分顺畅,也就是说,应用程序可能会释放某些客户端的请求。
为了测试是否丢失了运行中的请求,特别是针对正在退出服务的实例发出的请求,我们可以使用连接到我们的应用程序的负载测试工具。 我们感兴趣的要点是所有HTTP请求(包括HTTP保持活动连接)是否得到正确处理。 为此,我们使用负载测试工具,例如Apache Bench或Fortio 。
我们使用多个线程(即多个连接)以并发方式通过HTTP连接到正在运行的应用程序。 而不是关注延迟或吞吐量,我们对响应状态和潜在的连接失败感兴趣。
在Fortio的示例中,每秒具有500个请求和50个并发的keep-alive连接的调用如下所示:
$ fortio load -a -c 8 -qps 500 -t 60s "http://coffee.example.com/.../coffees" -a选项使Fortio保存报告,以便我们可以使用HTML GUI查看报告。 如果在滚动更新部署进行时启动此测试,则可能会看到一些请求无法连接:
Fortio 1.1.0 running at 500 queries per second, 4->4 procs, for 20s
Starting at 500 qps with 50 thread(s) [gomax 4] for 20s : 200 calls each (total 10000)
08:49:55 W http_client.go:673> Parsed non ok code 502 (HTTP/1.1 502)
[...]
Code 200 : 9933 (99.3 %)
Code 502 : 67 (0.7 %)
Response Header Sizes : count 10000 avg 158.469 +/- 13.03 min 0 max 160 sum 1584692
Response Body/Total Sizes : count 10000 avg 169.786 +/- 12.1 min 161 max 314 sum 1697861
[...]输出表明并非所有请求都可以成功处理。 我们可以运行几种测试方案,这些方案通过不同的方式(例如,通过Kubernetes入口或通过服务直接从集群内部)连接到应用程序。 我们将看到滚动更新期间的行为可能会有所不同,具体取决于测试设置的连接方式。 与通过入口连接相比,从群集内部连接到服务的客户端可能不会遇到那么多失败的连接。
了解发生了什么
现在的问题是,当Kubernetes在滚动更新期间从旧的Pod实例版本到新的Pod实例版本重新路由流量时,会发生什么情况。 让我们看看Kubernetes如何管理工作负载连接。
如果我们的客户(即零停机时间测试)直接从群集内部连接到coffee-shop服务,则它通常使用通过群集DNS解析的服务VIP,最终到达Pod实例。 这是通过在每个Kubernetes节点上运行并更新路由到Pod的IP地址的iptables的kube-proxy来实现的。
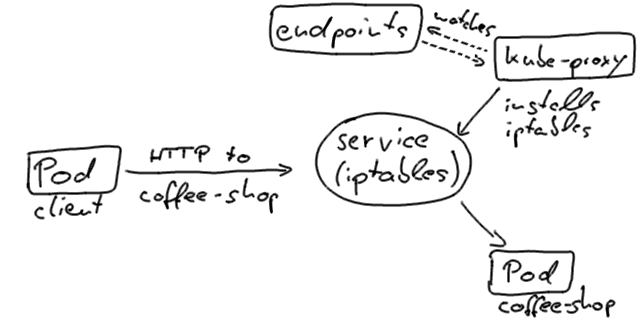
Kubernetes将更新Pod状态中的终结点对象,使其仅包含准备处理流量的Pod。
但是,Kubernetes入口以稍微不同的方式连接到实例。 这就是为什么当客户端通过入口资源连接到应用程序时,在滚动更新中会注意到不同的停机时间行为的原因。
NGINX入口直接在其上游配置中包含Pod地址。 它独立监视端点对象的更改。
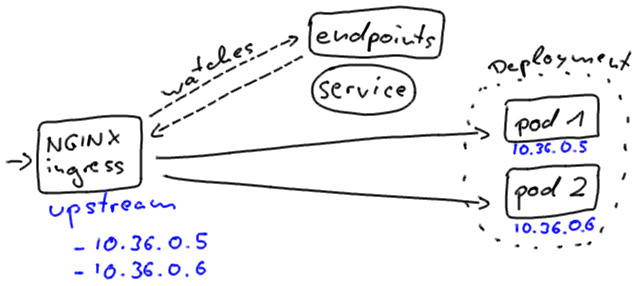
无论我们如何连接到应用程序,Kubernetes的目标都是在滚动更新过程中最大程度地减少服务中断。
一旦新的Pod处于活动状态并准备就绪,Kubernetes将使旧的Pod停止服务,从而将Pod的状态更新为Terminating ,将其从端点对象中删除,然后发送SIGTERM 。 SIGTERM使容器以(希望)正常的方式关闭,并且不接受任何新连接。 在将Pod从端点对象中逐出后,负载均衡器会将流量路由到其余(新的)流量。 这就是造成我们部署中的可用性差距的原因。 在负载均衡器注意到更改并可以更新其配置之前或之时,通过终止信号停用Pod。 这种重新配置是异步发生的,因此不能保证正确的排序,并且可以并且将导致很少的不幸请求被路由到终止Pod。
走向零停机
如何增强我们的应用程序以实现(真正的)零停机时间迁移?
首先,实现此目标的前提是我们的容器正确处理终止信号,即该进程将在Unix SIGTERM上正常关闭。 看看Google 打造容器的最佳做法 。 所有主要的Java Enterprise应用服务器都处理终止信号。 取决于我们的开发人员,我们是否可以正确地对其进行docker化 。
下一步将包括准备情况探针,以检查我们的应用程序是否已准备好处理流量。 理想情况下,探针已经检查了需要预热的功能状态,例如缓存或Servlet初始化。
准备情况调查是我们平滑滚动更新的起点。 为了解决pod终端当前不会阻塞并等到负载均衡器重新配置之后的问题,我们将提供一个preStop生命周期挂钩。 在容器终止之前调用此钩子。
生命周期挂钩是同步的,因此必须在将最终终止信号发送到容器之前完成。 在我们的例子中,我们使用此钩子仅在应用程序保持完整功能时禁用就绪状态。 一旦准备就绪探针失败,无论当前终止尝试如何,都将pod从服务端点对象中排除,因此也将从我们的负载平衡器中排除。 为了确保重新配置我们的负载均衡器,我们将在生命周期挂钩返回和容器终止之前包括一个等待期。
为了实现此行为,我们在coffee-shop部署中定义了一个preStop挂钩:
kind: Deployment
apiVersion: apps/v1beta1
metadata:
name: coffee-shop
spec:
replicas: 3
template:
spec:
containers:
- name: zero-downtime
image: docker.example.com/coffee-shop:1
livenessProbe:
# ...
readinessProbe:
# ...
lifecycle:
preStop:
exec:
command: ["/bin/bash", "-c", "/deactivate-health-check.sh && sleep 20"]
strategy:
# ... 在很大程度上取决于您选择的技术如何实现就绪性和活动性探针以及生命周期挂钩行为。 后者表示为具有20秒同步宽限期的deactivate-health-check.sh脚本。 该脚本将立即导致准备就绪探针失败,而关闭过程仅在20秒的等待时间之后才继续。
对于Java Enterprise,我们通常使用例如JAX-RS或MicroProfile Health将探针实现为HTTP资源。 生命周期挂钩将需要通过另一种方法或某些容器内部共享资源来停用运行状况检查资源。
当我们现在部署在看我们豆荚的行为,我们将看到终端仿真器会在状态Terminating ,慢慢地改变它的准备false之前它最终终止。 如果我们使用Apache Bench重新测试我们的方法,我们将看到零失败请求的理想行为:
Fortio 1.1.0 running at 500 queries per second, 4->4 procs, for 20s
Starting at 500 qps with 50 thread(s) [gomax 4] for 20s : 200 calls each (total 10000)
[...]
Code 200 : 10000 (100.0 %)
Response Header Sizes : count 10000 avg 159.530 +/- 0.706 min 154 max 160 sum 1595305
Response Body/Total Sizes : count 10000 avg 168.852 +/- 2.52 min 161 max 171 sum 1688525
[...]结论
考虑到生产就绪性,Kubernetes在编排应用程序方面做得很好。 但是,为了在生产环境中运行我们的企业系统,关键是我们的工程师必须了解Kubernetes是如何在后台运行的,以及我们的应用程序在启动和关闭期间的行为。
在本系列文章的第二部分中,我们将看到当我们在Kubernetes上运行Istio时,如何实现零停机时间更新的相同目标。 我们还将发现如何将这些方法与持续交付环境相结合。
更多资源
- GitHub项目示例(Kubernetes入口版本)
- 服务— Kubernetes文档
- 吊舱的终止— Kubernetes文档
- 克里斯·穆斯(Chris Moos)在Kubernetes中实现零停机部署 -感谢作者启发了这些文章
- 建立容器的最佳做法-Google Cloud
翻译自: https://www.javacodegeeks.com/2018/10/zero-downtime-rolling-updates-kubernetes.html
不停机与停机更新















 7568
7568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









