





 本文介绍了如何利用AWS Redshift建立长期的日志分析基础架构,通过S3归档支持将日志文件加载到Redshift集群,进行SQL搜索。文章详细阐述了设置过程、集群选项、数据库格式调整以及示例查询,展示了Redshift在处理大规模日志数据时的效率和成本效益。
本文介绍了如何利用AWS Redshift建立长期的日志分析基础架构,通过S3归档支持将日志文件加载到Redshift集群,进行SQL搜索。文章详细阐述了设置过程、集群选项、数据库格式调整以及示例查询,展示了Redshift在处理大规模日志数据时的效率和成本效益。
aws redshift
您将在产品和代码库的整个生命周期中聚集大量日志,因此能够搜索它们非常重要。 在极少数的安全问题中,没有这种功能会带来极大的痛苦。
您也许可以使用允许您快速搜索过去两周日志的服务。 但是,如果您要搜索过去六个月,一年甚至更长时间,该怎么办? 这种可用性可能非常昂贵,甚至根本无法提供现有服务。
许多托管日志服务提供S3归档支持,我们可以使用它们来与AWS Redshift建立长期的日志分析基础架构。 最近,我设置了脚本,以便能够在Codeship上随时创建该基础结构。
AWS Redshift
AWS Redshift是AWS的数据仓库解决方案。 它具有简单的群集和提取机制,非常适合加载大型日志文件,然后使用SQL搜索它们。
由于它会自动平衡多台计算机上的日志文件,因此如果需要更高的速度,则可以轻松扩展。 正如我之前所说的,浏览大量日志文件是一种相对罕见的情况。 您不需要一直存在这个基础架构,这使其成为AWS的完美用例。
设置日志分析
让我们看一下驱动长期日志分析基础结构的脚本。 您可以在flomotlik / redshift-logging GitHub存储库中检出它们。
我将逐步指导您配置所需的环境变量的整个设置,以及开始创建集群和搜索日志。
但是首先,在进入所有可以设置的不同选项之前,让我们对设置脚本的工作有一个总体的了解:
- 创建一个AWS Redshift集群。 您可以配置服务器的数量以及应使用的服务器类型。
- 等待集群准备就绪。
- 在Redshift集群内创建一个SQL表以将日志文件加载到其中。
- 从AWS S3将所有日志文件提取到Redshift集群中。
- 清理数据库并打印psql access命令以连接到集群。
在进入可以通过.env文件设置的所有不同选项之前,请确保在GitHub上签出脚本 。
设置选项
以下是所有可用选项的列表。 您可以简单地将.env.template文件复制到.env,然后填写所有选项以进行选择。
- AWS_ACCESS_KEY_ID
- 应该运行Redshift集群的账户的AWS密钥。
- AWS_SECRET_ACCESS_KEY
- 应该运行Redshift集群的账户的AWS密钥。
- AWS_REGION = us-east-1
- 群集应在其中运行的AWS区域,默认为us-east-1。
- REDSHIFT_USERNAME
- 用psql连接到集群的用户名。
- REDSHIFT_PASSWORD
- 与psql连接到集群的密码。
- S3_AWS_ACCESS_KEY_ID
- 有权访问您要从中提取日志的S3存储桶的AWS密钥。
- S3_AWS_SECRET_ACCESS_KEY
- 有权访问您要从中提取日志的S3存储桶的AWS密钥。
- 端口= 5439
- 与psql连接的端口。
- CLUSTER_TYPE =单节点
- 群集类型可以是单节点或多节点。
- NODE_TYPE
- 用于集群节点的实例类型。
- NUMBER_OF_NODES = 10
- 在多模式下运行时的节点数。
- CLUSTER_IDENTIFIER =日志分析
- DB_NAME =日志分析
- S3_PATH = s3:// your_s3_bucket / papertrail / logs / 862693 / dt = 2015
数据库格式和失败的加载
将日志语句吸收到群集中时,请确保检查正在发生的失败负载量。 您可能必须编辑数据库格式以适合您的特定日志输出样式。 您可以通过首先创建一个单节点集群轻松调试此问题,该集群仅加载日志的一小部分,因此非常快。 在扩展到整个群集之前,请确保没有或几乎没有失败的负载。
如果出现问题,请查看copy命令的文档,该命令会将您的日志加载到数据库中,并提供设置脚本中的参数。
示例和基准
设置整个集群并对其运行示例查询是一件快速的事情。 例如,我将过去九个月的所有日志加载到Redshift集群中,并对它运行几个查询。 我没有花时间优化表格,但是如果需要的话,您肯定可以提高整个系统的速度。 开箱即用对我们来说已经足够快了。
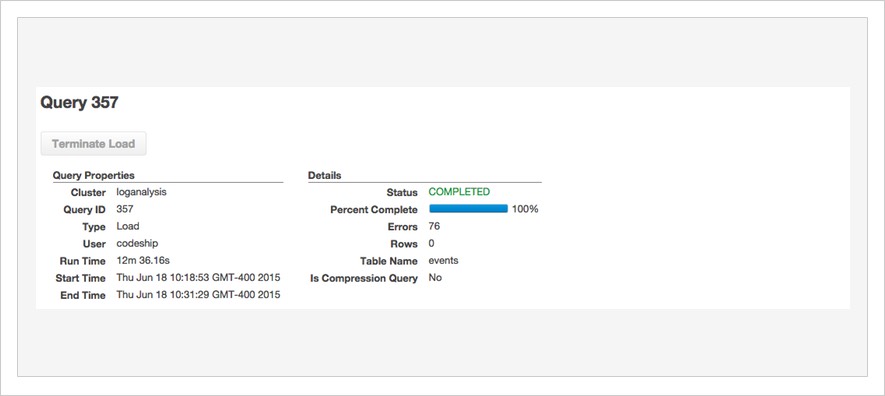
如您所见,在10台计算机的群集上,加载5月份的所有日志(超过6亿条日志行)仅花费了12分钟。 由于有足够的可用存储空间,我们可以轻松地将一个多月的时间加载到该10台机器的群集中,但是对于本帖子来说,一个月就足够了。
之后,我们可以通过SQL搜索所有应用程序和过去服务器的历史记录。 我们与psql客户端连接,并针对“事件”数据库发送SQL查询。
例如,如果我们想知道五月份有多少个构建服务器报告日志,该怎么办:
loganalysis=# select count(distinct(source_name)) from events where source_name LIKE 'i-%';
count
-------
801
(1 row)因此,在5月,我们为客户运行了801台EC2构建服务器。 该查询大约需要3秒钟才能完成。
或假设我们想知道有多少人访问了我们主存储库的配置页面(项目ID被XXXX隐藏):
loganalysis=# select count(*) from events where source_name = 'mothership' and program LIKE 'app/web%' and message LIKE 'method=GET path=/projects/XXXX/configure_tests%';
count
-------
15
(1 row)因此,现在我们知道整个五月在该配置页面上有15次访问。 我们还可以获得所有详细信息,包括谁通过日志访问了它。 如果我们需要研究任何安全问题,这可能会有所帮助。 查询花费了大约40秒钟来遍历我们的所有日志,但是可以在Redshift上进行更多优化。
这些只是您可以用来查看日志的一些查询,从而可以更深入地了解客户对系统的使用情况。 您只需花费每小时2.50美元即可安装所有设备,并且可以立即将其关闭,并在需要再次访问该数据时重新创建。
结论
能够搜索历史并从中学习对构建大型基础架构非常重要。 您需要能够轻松查看历史记录,尤其是涉及安全问题时。
借助AWS Redshift,您拥有了一个出色的工具,可让您启动临时分析的快速而廉价的即席分析基础架构。 当然,Redshift还可以做更多的事情。
让我们知道您的日志,存储和搜索过程和工具在注释中。
翻译自: https://www.javacodegeeks.com/2015/06/long-term-log-analysis-with-aws-redshift.html
aws redshift















 7400
7400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









