





OptaPlanner最终支持多线程增量求解 。 加速是惊人的。 即使只有几个CPU内核,它的得分计算速度也可以提高三倍。 请参阅下面的结果。 要激活它,只需在配置中添加一行即可。
最初的功能要求始于2007年。多年来,我们逐步为之准备了内部架构。 所以现在,十年后,我们从7.9.0.Final开始完全支持它。
但是为什么要花这么长时间实施呢?
要求
让我们看一下多线程增量求解的要求:
- 在CPU上水平扩展算法。
- 不要破坏增量分数计算的速度。
- 运行必须是可重复的。
在CPU上水平扩展算法
有多种方法可以使用多个线程而不进行真正的多线程解决:
- 多租户 :解决多个数据集,每个线程一个。
- 从第一个OptaPlanner版本开始工作。
- 多重下注解决方案 :以多种方式解决一个数据集,彼此完全独立。 取得最佳结果。
- 从第一个OptaPlanner版本开始工作。
- 分区搜索 :分解一个数据集并分别求解每个数据集。
- 自OptaPlanner 7.0起已完全受支持。
但是这些都不是真正的并行启发式,如下面右下角所示:
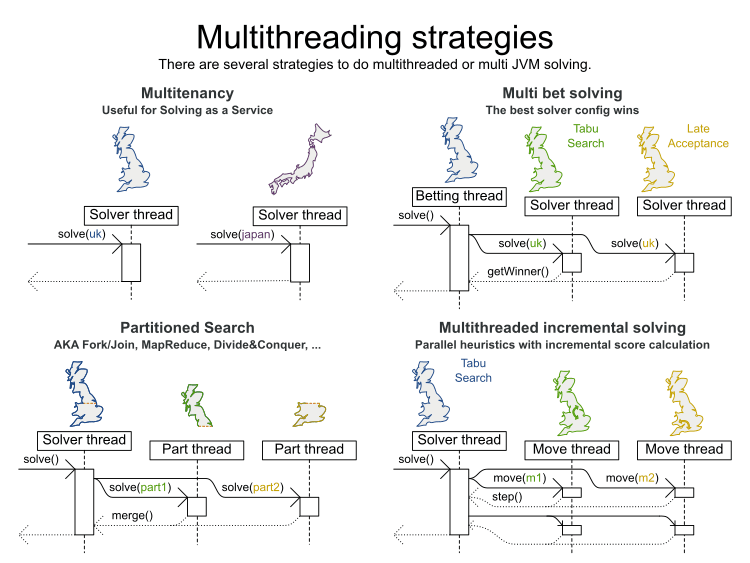
在实际的多线程解决方案中,我们通过将1种算法(可能是多种算法的组合)的繁重计算工作分流到单独CPU内核上的多个线程中而无需分区即可解决1个数据集。
在OptaPlanner的构造试探法和本地搜索中,最耗CPU的工作是计算移动分数。 例如,在禁忌搜索中,每个步骤(外部迭代)的计算结果约为1000个动作。 以此作为分数计算速度 。 它通常在每秒1k个评估动作与每秒500k个评估动作之间变化。
多线程求解只是将步骤的运动评估分布到多个线程中的问题。 那很简单。 甚至有一些用户通过入侵我们的代码来做到这一点(最著名的是航天局的供应商)。 但是他们没有看到性能提升。 实际上恰恰相反(除了使用简单分数计算器)。 这些变化破坏了增量分数的计算。 多线程求解很容易。 但是多线程增量求解很难。
不要破坏增量分数计算的速度
嗯,这使我们可以进行增量分数计算。 性能的关键。 带来巨大可扩展性的是OptaPlanner核心的火箭科学。 并且-对于少数看到它们的人-臭名昭著的得分腐败异常的原因。
什么是增量分数计算? 对于每一步,我们在应用该步后计算解状态的分数。 使用非增量分数计算时,将从头开始计算整个分数。 但是通过增量分数计算,我们仅计算增量,如下所示。 这样效率更高。

可以这样说:在具有1000个位置的车辆路径问题上,增量式分数计算器在理论上比非增量式分数计算器快约500倍。 要弥补增量求解器在1000个计划实体的数据集上的损失,多线程非增量求解器将需要大约500个CPU内核(理论上)。 在实践中,数字各不相同,但是增量求解的收益总是大于多线程求解的收益。
当然,现在,我们可以吃蛋糕了。
每个增量分数计算器本质上都是单线程的,因此每个移动线程都有其自己的分数计算器和其解决方案状态。 克隆两者都太昂贵了。 要使用增量分数计算来评估移动线程上的移动,我们必须重用先前评估的分数计算器。 这意味着开始时工作解决方案必须处于完全相同的状态。 但是,由于外部步骤迭代会不断更改解决方案状态,因此移动线程必须在每个步骤之后与主求解器线程同步。
它类似于任何实时多人游戏(如《星际争霸》),在该游戏中,多个主机需要同步以显示相同的游戏状态,但不能为每次更改都传递整个游戏状态。
一旦一个线程不同步,该线程的所有计算都将被破坏,并且整个系统都将受到影响。 但是,通过精心设计的并发组件编排(以及多天的测试运行),我们可以防止出现竞争情况。 而且有效。 像个魅力。
此外,即使只是共享获胜的举动,线程也必须能够彼此发送举动。 这也带来了挑战。 OptaPlanner是一个面向对象的约束求解器 ,因此它的决策变量可以是任何有效的Java类型(不仅是布尔值,数字和浮点数),例如Employee或Foo 。 这些变量可以位于任何域类(称为计划实体)中,例如Shift或Bar 。 移动实例引用这些类实例。 当克隆解决方案以启动移动线程时,那些计划实体(例如Shift被克隆。 因此,当从线程A的移动发送到线程B时,OptaPlanner将移动基于线程B的解决方案状态重新进行。这将线程实例的解决方案状态的等效引用替换了从移动实例到线程A的解决方案状态的引用。 很漂亮
运行必须具有可重复性
再现性为王。 通过OptaPlanner运行两次相同的数据集并在经过相同数量的步骤(以及每一步)后获得完全相同的结果的能力,值得用金子来衡量。 否则,将使调试,问题跟踪和生产审核极为困难。
多核计算机上线程执行顺序固有的不可预测性,使得可重复性成为一个有趣的要求。 将其与对种子随机数生成器(不是线程安全的)的许多优化算法的依赖结合起来,确实是一个挑战。
但是我们做到了。 我们具有100%的可重复性。 这涉及多种巧妙的机制,例如使用主种子随机数生成每个线程的种子随机数,生成可预测数量的选定缓冲移动(因为移动生成通常也依赖于随机生成器),并对原始选择的已评估移动进行重新排序它们从移动线程回来时的顺序。
配置
多线程增量求解很容易激活。 只需在您的求解器配置中添加<moveThreadCount>行:
<solver>
<moveThreadCount>4</moveThreadCount>
...
</solver> 这基本上为求解器捐赠了4个额外的CPU内核。 使用AUTO使OptaPlanner自动推断出它。 (可选)为不喜欢创建任意线程的环境指定<threadFactoryClass> 。
如果您有足够的CPU内核可以将其与其他功能结合使用,则可以将其与其他所有功能结合使用,包括其他多线程策略(例如多租户,分区搜索等)。
基准测试
方法
使用optaplanner-benchmark,我运行了一组宏基准测试:
- 在具有32GB物理RAM的64位8核 Intel i7-4790台式机上。
- 在Linux上使用OpenJDK 1.8.0_171。
- 将JVM最大堆(
-Xmx)设置为4GB。- 我还尝试了2GB,但结果却更糟,尤其是对于更多数量的移动线程。
- 将日志记录设置为
info日志记录。- 我还尝试了
debug日志记录,结果显然更糟(因为运行速度越快,调试日志记录就越多)。
- 我还尝试了
- 得分为DRL。
- 我还尝试使用增量Java计算器,这些结果每秒执行的动作更多,但每个动作线程的相对增益较低(由于拥塞较高)。
- 每个数据集5分钟。
车辆路径问题(VRP)的结果
以下是针对不同的VRP数据集的结果,首先进行递减(构造启发式),然后进行禁忌搜索(本地搜索)。 越高越好。
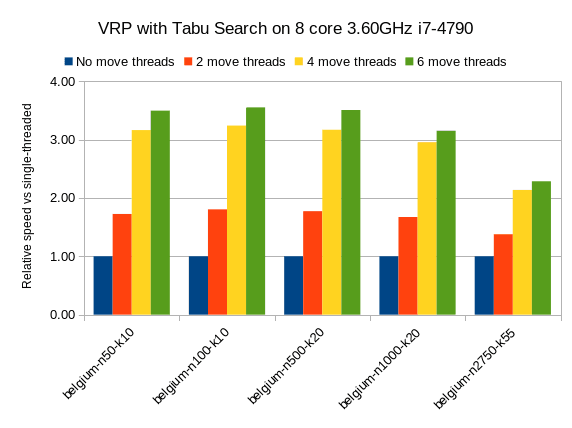
蓝条是传统的单线程OptaPlanner。 它的平均得分计算速度为26,947移动。 即上升到45,565 2移动螺纹,以80,757具有4个移动线程和到88,410 6个移动螺纹。
因此,通过向OptaPlanner捐赠更多的CPU内核,可以花费一小部分时间来达到相同的结果。
在其他本地搜索算法(例如后期接受)上,我们看到类似的结果:
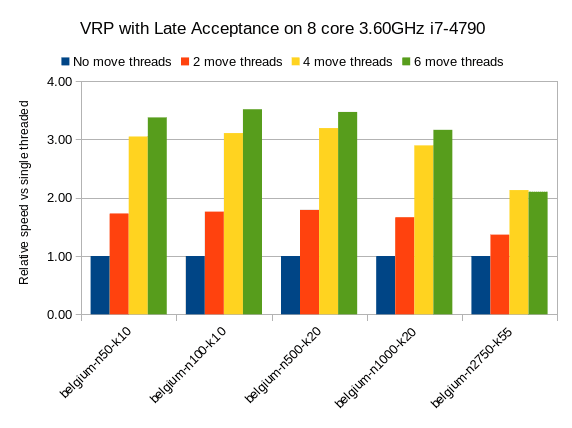
后期接受是一种快速的步进算法(尤其是在开始时),这意味着每步移动较少。 然而,它对于车辆路径问题具有类似的相对速度增益。
我们还看到具有2750个VRP位置的最大数据集的相对速度增益略有降低,但是我怀疑这可能是因为4GB最大堆内存太低而无法充分发挥作用。 我将对此进行进一步调查。
护士名册结果
我还在护士排班用例上运行了基准测试,但是将JVM最大堆( -Xmx )设置为2GB。 在这里,我尝试了禁忌搜索,模拟退火和后期验收:
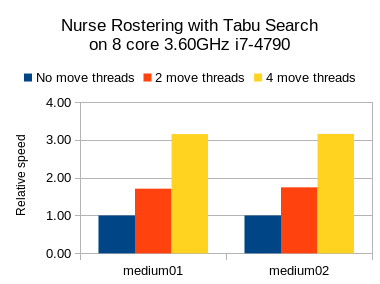
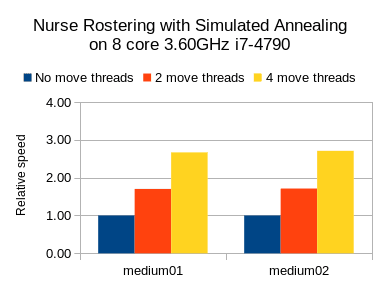
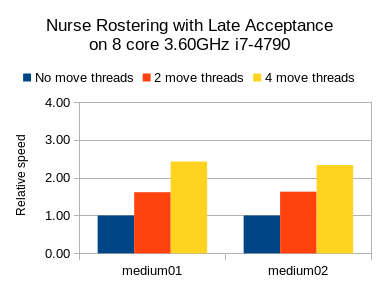
在这三种情况下,我们都看到了可喜的速度增益,但是禁忌搜索(一种慢速步进算法)的相对增益要高于其他两种(快速步进算法)。
无论如何,很明显, 您的里程可能会有所不同 ,具体取决于用例和其他因素。
未来的改进
随着我们增加移动线程数或减少评估一个线程上单次移动的时间,我们看到线程间通信队列上的拥塞程度更高,从而导致相对的可伸缩性增益较低。 有几种解决方法,将来我们将研究这种内部改进。
结论
您所有的CPU都属于OptaPlanner。 [1]
通过一条额外的配置线, OptaPlanner可以在短时间内获得相同的高质量解决方案。 当然,如果您还有CPU核心可用。
翻译自: https://www.javacodegeeks.com/2018/07/multithreaded-incremental-solving.html















 1911
1911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









