






 本文介绍如何利用Apache Spark的spark.ml库进行逻辑回归,以预测乳腺癌的恶性程度。通过介绍数据集、特征提取、模型训练和测试,展示了如何构建一个99%准确率的分类模型。
本文介绍如何利用Apache Spark的spark.ml库进行逻辑回归,以预测乳腺癌的恶性程度。通过介绍数据集、特征提取、模型训练和测试,展示了如何构建一个99%准确率的分类模型。
在此博客文章中,我将帮助您开始使用Apache Spark的spark.ml Logistic回归来预测癌症恶性程度。
Spark的spark.ml库目标是在DataFrames之上提供一组API,以帮助用户创建和调整机器学习工作流程或管道。 将spark.ml与DataFrames一起使用可通过智能优化提高性能。
分类
分类是一类有监督的机器学习算法,该算法基于已知项目的标记示例(例如,已知为恶性的观察结果)来识别该项目属于哪个类别(例如,癌组织观察结果是否为恶性)。 )。 分类采用具有已知标签和预定功能的一组数据,并学习如何基于该信息对新记录进行标签。 功能就是您提出的“如果有问题”。 标签是这些问题的答案。 在下面的示例中,如果它像鸭子一样走路,游泳和嘎嘎叫声,则标签为“鸭子”。

让我们来看一个癌组织观察的例子:
- 我们要预测什么?
- 样本观察结果是否为恶性。
- 您可以用来预测的“如果有问题”或属性是什么?
- 组织样本特征:团块厚度,细胞大小均匀性,细胞形状均匀性,边缘附着力,单个上皮细胞大小,裸核,温和染色质,正常核仁,线粒体。
逻辑回归
Logistic回归是预测二进制响应的流行方法。 这是广义线性模型的一种特殊情况,可以预测结果的可能性。 Logistic回归通过使用Logistic函数估计概率来度量Y“标签”和X“特征”之间的关系。 该模型预测用于预测标签类别的概率。
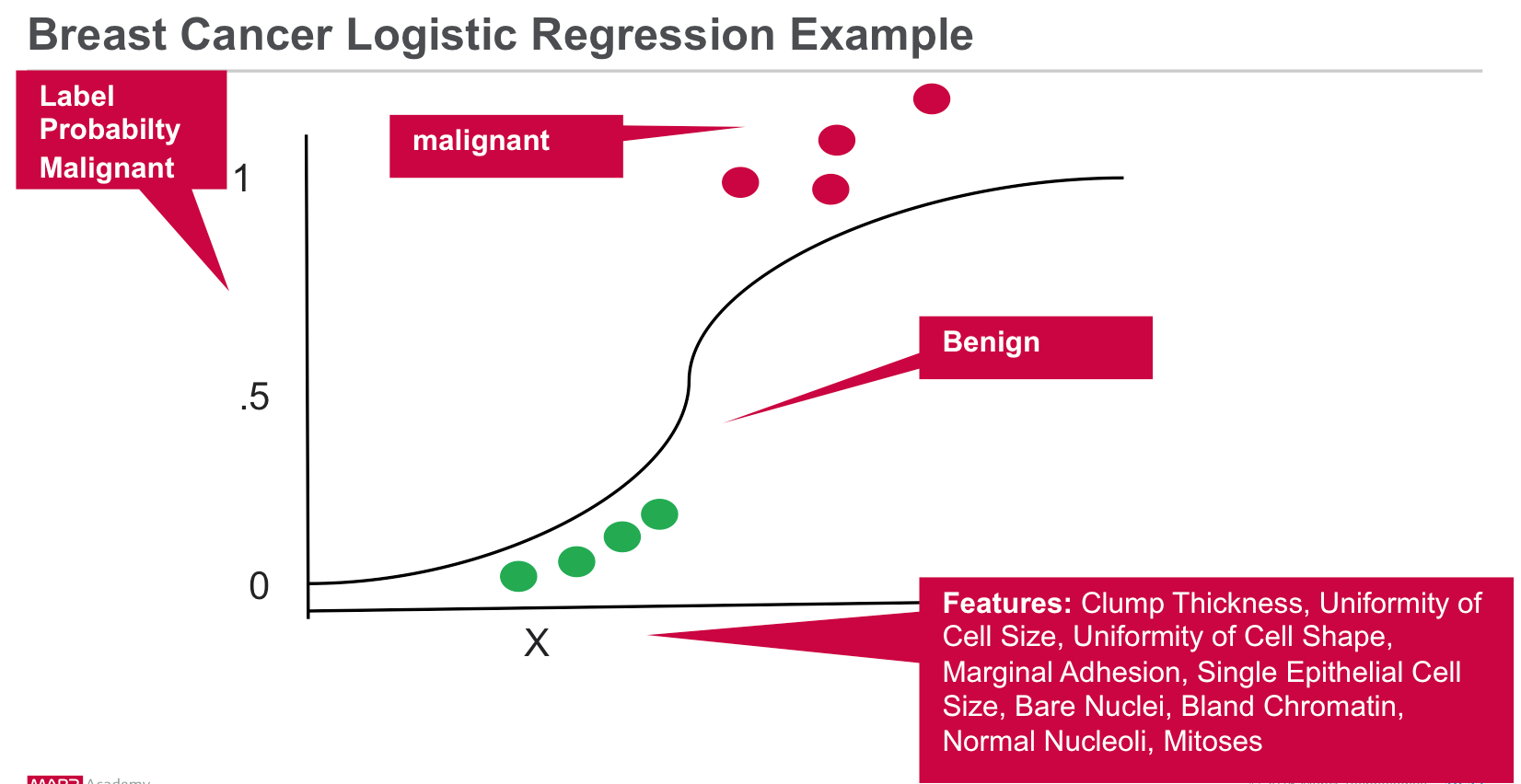
使用Spark机器学习场景分析癌症观察结果
我们的数据来自威斯康星州诊断性乳腺癌(WDBC)数据集,该数据集根据9种特征将乳腺肿瘤病例分为良性或恶性,以预测诊断。 对于每个癌症观察,我们都有以下信息:
1. Sample code number: id number
2. Clump Thickness: 1 - 10
3. Uniformity of Cell Size: 1 - 10
4. Uniformity of Cell Shape: 1 - 10
5. Marginal Adhesion: 1 - 10
6. Single Epithelial Cell Size: 1 - 10
7. Bare Nuclei: 1 - 10
8. Bland Chromatin: 1 - 10
9. Normal Nucleoli: 1 - 10
10. Mitoses: 1 - 10
11. Class: (2 for benign, 4 for malignant)癌症观察csv文件具有以下格式:
1000025,5,1,1,1,2,1,3,1,1,2
1002945,5,4,4,5,7,10,3,2,1,2
1015425,3,1,1,1,2,2,3,1,1,2在这种情况下,我们将基于以下特征构建一个逻辑回归模型,以预测恶性肿瘤的标签/分类:
- 标签→恶性或良性(1或0)
- 特征→{丛集厚度,细胞大小均匀性,细胞形状均匀性,边缘粘附性,单上皮细胞大小,裸核,温和染色质,正常核仁,线粒体}
Spark ML提供了一组基于DataFrames的统一高级API。 Spark ML的主要概念是:
- DataFrame:ML API使用Spark SQL中的DataFrames作为ML数据集。
- 变压器:变压器是一种将一个DataFrame转换为另一个DataFrame的算法。 例如,将具有特征的DataFrame转换为具有预测的DataFrame。
- 估计器:估计器是一种算法,可以适合于DataFrame来生成Transformer。 例如,在DataFrame上进行训练/调整并生成模型。
- 管道:管道将多个“变形器”和“估计器”链接在一起,以指定ML工作流程。
- ParamMaps:要选择的参数,有时也称为“参数网格”。
- 评估者:一种度量标准,用于根据保留的测试数据来衡量拟合模型的表现。
- CrossValidator:确定最佳的ParamMap,并使用最佳的ParamMap和整个数据集重新拟合Estimator。
在此示例中,将使用如下所示的Spark ML工作流程: 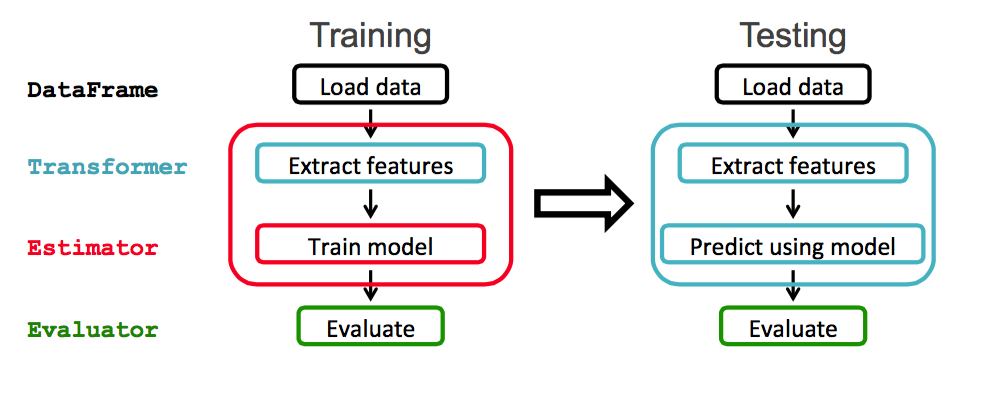
软件
本教程将在Spark 1.6.1上运行
- 您可以从此处下载代码和数据以运行这些示例: https : //github.com/caroljmcdonald/spark-ml-lr-cancer
- 使用spark-shell命令启动后,本文中的示例可以在Spark shell中运行。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9179
9179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









