





作为我的日志分析的一部分,我想从发布说明中获取Neo4j的发布日期,并决定尝试Hadley Wickham于2014年底发布的rvest抓取库 。
rvest基于Python的beautifulsoup ,它已成为我选择的抓取库,因此我觉得上手并不难。
首先,我们需要在本地下载发行说明,因此在进行抓取时不必遍历网络:
download.file("http://neo4j.com/release-notes/page/1", "release-notes.html")
download.file("http://neo4j.com/release-notes/page/2", "release-notes2.html")我们想将这些页面解析回来,并返回包含版本号和发行日期的行。 HTML看起来像这样:
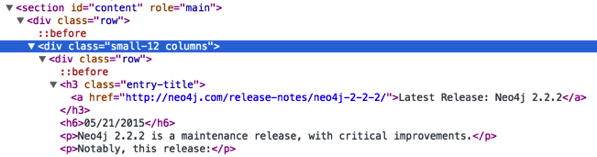
我们可以使用以下代码获取行:
library(rvest)
library(dplyr)
page1 <- html("release-notes.html")
page2 <- html("release-notes2.html")
rows = c(page1 %>% html_nodes("div.small-12 div.row"),
page2 %>% html_nodes("div.small-12 div.row") )
> rows %>% head(1)
[[1]]
<div class="row"> <h3 class="entry-title"><a href="http://neo4j.com/release-notes/neo4j-2-2-2/">Latest Release: Neo4j 2.2.2</a></h3> <h6>05/21/2015</h6> <p>Neo4j 2.2.2 is a maintenance release, with critical improvements.</p> <p>Notably, this release:</p> <ul><li>Provides support for running Neo4j on Oracle and OpenJDK Java 8 runtimes</li> <li>Resolves an issue that prevented the Neo4j Browser from loading in the latest Chrome release (43.0.2357.65).</li> <li>Corrects the behavior of the <code>:sysinfo</code> (aka <code>:play sysinfo</code>) browser directive.</li> <li>Improves the <a href="http://neo4j.com/docs/2.2.2/import-tool.html">import tool</a> handling of values containing newlines, and adds support f...</li></ul><a href="http://neo4j.com/release-notes/neo4j-2-2-2/">Read full notes →</a> </div>现在,我们需要遍历各行,仅提取版本和发行日期。 我编写了以下函数来执行此操作,并删除我们不感兴趣的所有多余文本:
generate_releases = function(rows) {
releases = data.frame()
for(row in rows) {
version = row %>% html_node("h3.entry-title")
date = row %>% html_node("h6")
if(!is.null(version) && !is.null(date)) {
version = version %>% html_text()
version = gsub("Latest Release: ", "", version)
version = gsub("Neo4j ", "", version)
releases = rbind(releases, data.frame(version = version, date = date %>% html_text()))
}
}
return(releases)
}
> generate_releases(rows)
version date
1 2.2.2 05/21/2015
2 2.2.1 04/14/2015
3 2.1.8 04/01/2015
4 2.2.0 03/25/2015
5 2.1.7 02/03/2015
6 2.1.6 11/25/2014
7 1.9.9 10/13/2014
8 2.1.5 09/30/2014
9 2.1.4 09/04/2014
10 2.1.3 07/28/2014
11 2.0.4 07/08/2014
12 1.9.8 06/19/2014
13 2.1.2 06/11/2014
14 2.0.3 04/30/2014
15 2.0.1 02/04/2014
16 2.0.2 04/15/2014
17 1.9.7 04/11/2014
18 1.9.6 02/03/2014
19 2.0 12/11/2013
20 1.9.5 11/11/2013
21 1.9.4 09/19/2013
22 1.9.3 08/30/2013
23 1.9.2 07/16/2013
24 1.9.1 06/24/2013
25 1.9 05/13/2013
26 1.8.3 //最后,我想将'date'列转换为R date格式,并删除1.8.3行,因为它不包含日期。 lubridate是我在R中用于日期处理的goto库,因此我们将在这里使用它:
library(lubridate)
> generate_releases(rows) %>%
mutate(date = mdy(date)) %>%
filter(!is.na(date))
version date
1 2.2.2 2015-05-21
2 2.2.1 2015-04-14
3 2.1.8 2015-04-01
4 2.2.0 2015-03-25
5 2.1.7 2015-02-03
6 2.1.6 2014-11-25
7 1.9.9 2014-10-13
8 2.1.5 2014-09-30
9 2.1.4 2014-09-04
10 2.1.3 2014-07-28
11 2.0.4 2014-07-08
12 1.9.8 2014-06-19
13 2.1.2 2014-06-11
14 2.0.3 2014-04-30
15 2.0.1 2014-02-04
16 2.0.2 2014-04-15
17 1.9.7 2014-04-11
18 1.9.6 2014-02-03
19 2.0 2013-12-11
20 1.9.5 2013-11-11
21 1.9.4 2013-09-19
22 1.9.3 2013-08-30
23 1.9.2 2013-07-16
24 1.9.1 2013-06-24
25 1.9 2013-05-13然后,我们可以轻松地查看每年发布的版本数:
releasesByDate = generate_releases(rows) %>%
mutate(date = mdy(date)) %>%
filter(!is.na(date))
> releasesByDate %>% mutate(year = year(date)) %>% count(year)
Source: local data frame [3 x 2]
year n
1 2013 7
2 2014 13
3 2015 5或按月:
> releasesByDate %>% mutate(month = month(date)) %>% count(month)
Source: local data frame [11 x 2]
month n
1 2 3
2 3 1
3 4 5
4 5 2
5 6 3
6 7 3
7 8 1
8 9 3
9 10 1
10 11 2
11 12 1在进行这种快速的黑客攻击之前,每当我想抓取数据集时,我总是转向Ruby或Python,但看起来rvest使R现在成为此类工作的不错选择。 美好时光!
翻译自: https://www.javacodegeeks.com/2015/06/r-scraping-neo4j-release-dates-with-rvest.html















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









