





IT行业中发生的一种大趋势是从基于查询的面向批处理的系统向(软)实时更新的系统的转变。 尽管这仅与金融交易相关,但还有许多其他示例,例如“准时”物流系统,根据需求和负载对乘客座位进行实时定价的飞行公司,像EBay这样的C2C拍卖系统,实时流量控制等等。
随着信息的(商业)价值与时间有关 ,这种趋势可能会持续下去,价值随着信息的年龄而降低。
金融领域的自动交易只是该领域的先驱,因为几微秒的时间优势可以价值数百万美元。 它的自然实时处理系统在这一领域的发展更快。
但是,传统IT基础结构的大部分内容都不是为基于事件的反应性系统设计的。 从基于查询的数据库到基于请求响应的Http协议,常见的范例是“在需要时”存储和查询数据。
当前数据库是静态的且面向查询
当前的数据管理方法(例如SQL和NOSQL数据库)侧重于数据事务和数据的静态查询 。 数据库提供了对数据进行切片和切块的便利,但是它们不支持实时更新复杂的查询。 起义的NOSQL数据库仍然专注于计算静态结果。
数据库显然不是“反应性的”。
当前的邮件产品提供差的查询/筛选选项
当前的消息传递产品在过滤方面很弱。 消息被分为不同的流(或主题),因此客户端可以对接收到的数据进行原始的预选择。 但是,这通常意味着客户端应用程序接收的数据比需要的多10倍,并在“顶部”进行了细粒度的筛选。
一个很大的缺点是,主题方法将过滤器功能“内置”到系统的数据设计中。
例如,如果一个股票交易系统按每个股票拆分流,则客户端应用程序仍需要订阅所有流,以便提供“最活跃”股票的动态更新列表。 查询通常意味着“重放+搜索完整的消息历史记录”。
可伸缩的“连续查询”分布式Datagrid。
我很乐意为大型实时系统进行概念和技术设计,所以我想分享一个通用的可扩展解决方案,以进行大批量,大规模的连续查询处理。
实时处理系统通常被设计为“事件源”。 这意味着,持久性被日记帐交易所代替。 系统状态保存在内存中,事务日志仅用于历史分析和崩溃恢复。
客户端应用程序不查询,而是侦听事件流。 事件源系统的一个常见问题是“后期加入客户端”问题。 迟来的客户端将必须重播整个系统事件日志,以获取系统状态的最新快照。
为了支持后期加入的客户端,需要一种“高价值缓存”(LVC)组件。 LVC保持当前系统状态,并允许后加入者通过查询进行引导。
在高性能,大数据系统中,随着客户端数量的增加,LVC组件成为瓶颈。
通用化最后一个值缓存:连续查询
在连续查询数据缓存中,查询结果会自动保持最新。 查询将被订阅替换。
subscribe * from Orders where
symbol in ['ALV', 'BMW'] and
volume > 1000 and
owner='MyCompany'创建一个消息流,该消息流最初执行查询操作,此后每当发生影响查询结果的数据更改(对客户端应用程序透明)时,都会更新结果集。 该系统确保每个订户都能准确接收保持其“实时”查询结果最新所需的更改通知。
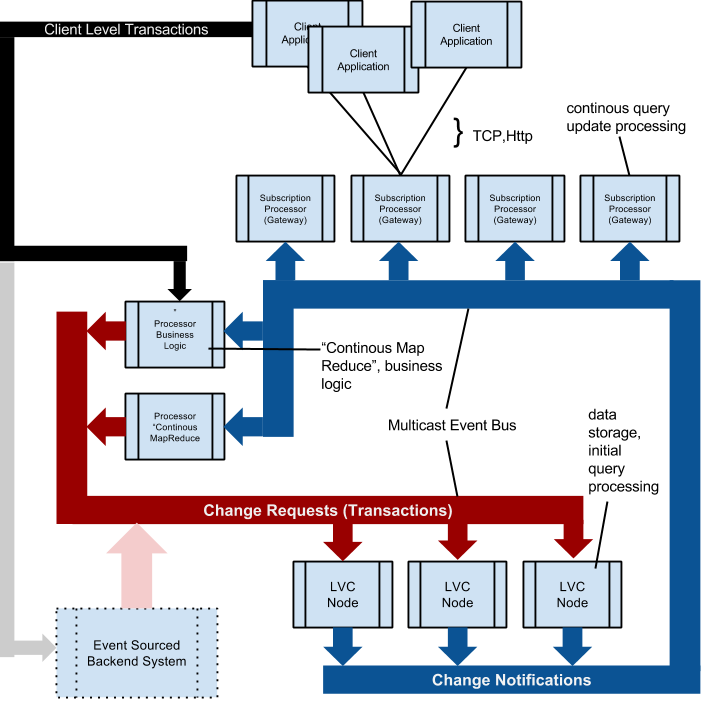
分布式连续查询系统:LVC节点保存数据。 事务通过消息总线(红色)发送给它们。 LVC节点计算由事务引起的实际差异,并在消息总线(蓝色)上发送更改通知。 这使“处理节点”可以保持其相关数据分区的最新镜像。 通过TCP / Http连接的外部客户端不会监听消息总线(因为在WAN中不是多播选项)。 “订阅处理器”通过侦听(蓝色)消息总线并将所需的更改通知仅分发到客户端的point2point连接,来使客户端的连续查询保持最新状态。
与静态数据管理相比,数据访问模式的差异:
- 高写入量
实时系统会产生大量的数据写访问/更改。 - 较少的全表扫描。
仅后期加入的客户端或查询条件的更改需要完整的数据扫描。 由于连续查询使“刷新”查询结果变得过时,因此读/写比率约为1:1(如果将交易产生的更改通知计为“读访问权”)。 - 当评估每次数据更改时对活动连续订阅的查询时,将产生大部分负载。 假设每秒有100.000个更改的事务负载和10.000个活动连续查询:这需要每秒100.000 * 10.000 = 10亿个查询条件评估 。 这仍然是一个低估:更新记录时,必须测试记录在更新之前是否与查询条件匹配以及在更新之后是否与查询条件匹配。 记录的更新可能会导致向查询订阅(或“更新”或“跳过” ofc)添加(因为更改后匹配)或删除事务(因为记录更改后不再匹配)。
数据集群节点(“ LastValueCache节点”)
数据以表格形式组织,面向列。 每个表的数据平均分配在所有数据网格节点(=高速缓存节点=“ LVC节点”)之间。 通过将数据节点添加到群集,容量会增加,并发性提高会加快快照查询(初始化订阅)的速度。
数据网格节点处理三种基本的事务/消息:
- AddRow(table,newRow),
- RemoveRow(table,rowId),
- UpdateRow(表,rowId,diff)。
数据网格节点提供了一个类似lambda的(行迭代器)接口,该接口使用纯Java代码支持表行的迭代。 这可以用于执行map-reduce作业,并且可以专门化用于新订阅客户端所需的初始查询。 由于正在进行的连续查询的计算是在“网关”节点中完成的,因此数据节点的负载和客户端数量之间的相关性很弱。
数据网格节点处理的所有事务都使用多播“更改通知”消息进行(重新)广播。
网关节点
网关节点跟踪到客户端应用程序的订阅/连接。 他们侦听变更通知的全局流,并检查变更是否影响连续查询(=订阅)的结果。 这非常占用CPU。
两件事情使这项工作:
- 通过使用普通的Java定义查询,查询条件将从JIT编译中受益,而无需解析和解释查询语言。 HotSpot是地球上最优化的JIT编译器之一。
- 由于多播用于全局更改流,因此可以添加其他网关节点,而不会影响群集的吞吐量。
处理器(或Mutator)节点
这些节点在群集数据的顶部实现逻辑。 例如,统计处理器对每个表进行连续查询,对每个表的行数进行递增计数,然后将结果写回到“统计”表中,以便监视客户端应用程序可以订阅当前表大小的实时数据。 另一个示例是股票交易所中的“匹配处理程序”,侦听股票的订单,如果订单匹配,则将其删除并将交易添加到“交易”表中。
如果人们将整个集群视为一种“巨型电子表格”,则处理器将执行该电子表格的公式。
扩大
- 数据大小:
增加LVC节点的数量 - 客户数量
增加订阅处理器节点。 - TP / S
扩展处理器节点和LVC节点
原因是系统严重依赖“真实”多播消息传递总线系统的可用性。 任何面向点对点或面向代理的网络/消息传递都是巨大的瓶颈。
结论
构建由连续查询系统支持的实时处理软件可以极大地简化应用程序开发。
- 大规模的模型视图控制器。
令人惊讶的是:数十年来在GUI应用程序中使用的模式尚未定期扩展到支持数据存储系统。 - 任何服务器端处理都可以自然方式分区。 处理器节点使用连续查询创建其数据分区的内存中镜像。 处理结果将流回数据网格。 可以通过添加订阅数据的不同分区的处理器实例(“分片”)来扩展计算密集型工作(例如,衍生工具的风险计算)的规模。
- 代码库的大小显着减少(业务逻辑和前端)。
手工系统中的许多代码都涉及保持数据最新。
翻译自: https://www.javacodegeeks.com/2014/01/big-data-the-reactive-way.html















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









