





 本文介绍了动态编程的概念,通过斐波那契数列的例子展示了动态编程如何解决指数级复杂度的问题,从递归到记忆化再到自底向上迭代的优化过程,探讨了动态编程的重叠子问题和最佳子结构特性,以及在优化算法性能中的作用。
本文介绍了动态编程的概念,通过斐波那契数列的例子展示了动态编程如何解决指数级复杂度的问题,从递归到记忆化再到自底向上迭代的优化过程,探讨了动态编程的重叠子问题和最佳子结构特性,以及在优化算法性能中的作用。
哇,自从我在这里写了东西已经有一段时间了。 在换工作,攻读博士学位和搬到新国家之间,我想你可以说我一直很忙。
但是与此同时,连同我生活中的所有这些变化,几乎每天我都会学习大量的新事物。 而且, 与其他许多人一样 ,我觉得以一种易于他人理解的方式撰写关于他们的文章,是巩固我自己的学习的最好方法之一。 因此,从现在开始,我将尝试在这里写更多的内容。
因此,有了这些内容,让我们转到重要的内容。 由于某些原因,最近我对从有点生锈的算法和数据结构中刷新旧概念非常感兴趣。 与这些旧概念一起出现的还有一些我从未听说过的新概念和技术。 但是,我将在单独的帖子中介绍它们。
在这篇文章中,我想谈谈动态编程。 如果您曾经上过算法大学课程,那么您可能已经听说过它。 如果您还没有这样做,那么这是一个学习极有用,容易和直观的东西的好机会(至少在您正确理解它的情况下)。
那么动态编程到底是什么? 我不会讲太多理论,因为如果您做一个简单的Google搜索,您已经可以找到所有的东西。 我将其定义为“智能递归”,并且像往常一样,我将通过一个示例对其进行说明。
解释动态编程的经典示例是斐波那契计算,因此我也将继续。 数字的斐波那契数的定义显然是递归的:
F(n)= F(n-1)+ F(n-2)和F(1)= F(2)= 1
这意味着前10个斐波那契数字的顺序将变为:
1,1,2,3,5,8,13,21,34,55
您可能还会发现它定义为:
F(0)= F(1)= 1
因此顺序如下:
0,1,1,2,3,5,8,13,21,34,55
出于这篇文章的目的,这种区别是无关紧要的,但我会坚持第一个。
现在,此递归定义可以自然而巧妙地转换为以下递归方法:
public static long fibonacci(int n) {
if (n < 3) return 1;
return fibonacci(n-2) + fibonacci(n-1);
}您甚至可以将其作为一个衬板:
public static long fibonacci(int n) {
return (n < 3) ? 1 : fibonacci(n-2) + fibonacci(n-1);
} 现在,该方法已经可以使用,并且肯定很优雅,但是随着您开始增加参数n的执行时间,会发生什么情况。 好吧,在我的笔记本电脑中,它几乎立即返回0到30之间的任何值。n为40时,它需要更长的时间:0.5秒。 但是对于等于50的n ,几乎需要一整分钟来计算正确的值。
您可能会认为整整一分钟并不多,但是任何大于70的值对我来说都会杀死该应用程序,而50到70之间的任何值都需要花费太多时间才能完成。 多少? 我真的不知道,因为我没有耐心等待,但是肯定要超过30分钟。
那么这种方法有什么问题呢? 好吧,我还没有谈论算法的时间和空间复杂度 (我可能会在另一篇文章中提到),所以现在我只说算法的执行时间随着n的增加呈指数增长。 这就是为什么当您使用n = 40和n = 50执行该方法时,会有如此大的时间差异的原因,因为2 ^ 40和2 ^ 50之间存在巨大差异。
通过仅对n的任何值跟踪其执行堆栈,也很容易看出该算法的行为原理。 让我们对n = 6进行简短处理。 下图显示了拨打电话的顺序。
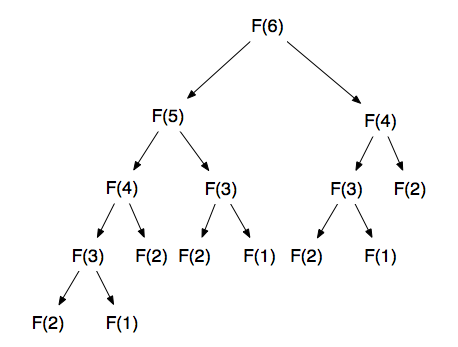
查看代码,我们可以清楚地看到,要计算6的值,首先要计算5和4的值。但是,类似地,要计算5的值,我们需要4和3的值并计算值对于4,我们需要3和2的值。一旦到达2,就可以结束递归,因为我们知道结果(为1)。
这是此方法的问题,请注意我们调用fibonacci(4)的次数以及调用fibonacci(3)的次数。 这是我们正在做的完全重复的工作。 如果永远不变,为什么要一遍又一遍地计算相同的结果? 一旦我们第一次计算了fibonacci(3)或fibonacci(4),我们就可以保存该结果并在需要时重复使用。
这正是我智能递归的意思。 您可以使用自然而简单的递归解决方案,但是您需要在重复工作的地方找出这些情况并避免它们。 对于n = 6并不是什么大不了的事,但是随着n的增长,重复工作的数量也会成倍增长,直到它使应用程序变得无用为止。
那么,我们如何去改进它呢? 我们只需要存储以前计算的值,就可以使用我们想要的任何结构。 在这种情况下,我将仅使用地图:
public static long fibonacci(int n) {
if (n < 3) return 1;
//Map to store the previous results
Map<Integer,Long> computedValues = new HashMap<Integer, Long>();
//The two edge cases
computedValues.put(1, 1L);
computedValues.put(2, 1L);
return fibonacci(n,computedValues);
}
private static long fibonacci(int n, Map<Integer, Long> computedValues) {
if (computedValues.containsKey(n)) return computedValues.get(n);
computedValues.put(n-1, fibonacci(n-1,computedValues));
computedValues.put(n-2, fibonacci(n-2,computedValues));
long newValue = computedValues.get(n-1) + computedValues.get(n-2);
computedValues.put(n, newValue);
return newValue;
}这个版本显然比第一个衬里的要长一些,但是仍然很容易理解。 现在,我们有2种方法,主要的公共方法(仅客户机使用n参数调用)和私有的方法进行递归调用。 第一种方法是初始化第二种方法所需的所有必要信息的有用位置。 在使用递归算法时,这是一种非常常见的模式。
在这种情况下,我们使用Map来保存已经计算的结果。 我们使用第一种方法中的2个基本案例初始化此映射,然后使用该映射调用第二种方法。 现在,我们不再总是计算该值,而是先检查它是否已经在地图上。 如果是,则只返回该值,否则我们计算并存储n-1和n-2的斐波那契数。 在返回它们的和之前,我们确保存储n的最终值。
请注意,我们仍然遵循与第一种方法相同的结构。 也就是说,我们从n开始,并根据需要计算较小的结果,以解决原始问题。 这就是为什么这种方法称为自上而下的原因。 稍后,我们将看到一种自下而上的方法,并将两者进行比较。 遵循自顶向下方法并保存先前计算的结果的这种技术也称为备忘录 。
这个版本好多少了? 好吧,虽然第一个版本花了将近一分钟的时间来计算n = 50的值,并且永不结束于更高的值,但是第二个记忆版本却给出了最多7000个n的即时答案。这是一个巨大的进步,但是,通常,我们可以做得更好。
这个新的记忆版本的问题在于,即使我们保存结果以供以后重用,我们仍然需要在第一次使用递归的情况下一直走到基本情况(当我们没有计算任何值时)但是我们还没有任何存储)。 因此,假设我们以n = 10000调用该方法。因为我们没有该结果,所以我们以9999、9998、9997 ...…2递归调用该方法。 从递归开始返回之后,所需的所有n-2值将已经存在,因此该部分相当快。
与任何递归算法一样,每个递归调用都占用堆栈上的一些空间。 而且,如果我们有足够的这些递归调用,堆栈最终将抛出StackOverflowException爆炸。 当我们使用超过10000的值时,这正是我们第二种方法所发生的情况。
那么,有什么选择呢? 我之前提到过,记忆版本遵循自上而下的方法。 显而易见的事情是以自下而上的方式朝相反的方向前进。 从n的小值开始并建立结果,直至达到我们的目标。 我们仍将保存已经计算出的值,以在以后的阶段中使用它们,并避免重复工作。 该解决方案看起来像:
public static long fibonacciDP(int n) {
long[] results = new long[n+1];
results[1] = 1;
results[2] = 1;
for (int i = 3; i <= n; i++) {
results[i] = results[i-1] + results[i-2];
}
return results[n];
}这实际上比我们的记忆版本更简单。 我们只是创建一个数组来保存结果,使用2个基本案例对其进行初始化,然后从3开始迭代直到n 。 在每一步中,我们使用2个先前计算的值来计算当前值。 最后,我们返回n的正确值。
在复杂性和计算数量方面,此版本与第二个版本完全相同。 此处的区别在于最后一个版本是迭代的,因此不会占用堆栈上的空间作为递归版本。 现在,我们可以计算出n = 500000或更多的斐波那契数列,并且响应时间几乎是瞬时的。
但是我们还没有完全结束,还有很多事情可以改进。 即使从指数时间复杂度到线性时间复杂度,我们也增加了所需的空间量。 在该算法的最后2个版本中,存储先前解所需的空间与n成正比。 如果我们创建一个长度为n的数组,这在我们的最后一个方法中可能很清楚。 n越大,我们需要的空间就越大。
但是实际上您可以看到,我们需要的唯一两个值是最后两个值( n-1和n-2 )。 因此,我们实际上不需要跟踪所有先前的解决方案,只需跟踪最后两个即可。 我们可以修改最后一个方法来做到这一点:
public static long fibonacciDP(int n) {
long n1 = 1;
long n2 = 1;
long current = 2;
for (int i = 3; i <= n; i++) {
current = n1 + n2;
n2 = n1;
n1 = current;
}
return current;
}在这里,我们仅用3个变量替换了长度为n的数组:当前值和2个先前值。 因此,后一种方法具有线性的时间复杂度和恒定的空间复杂度,因为我们需要声明的变量数量与n的大小无关。
这与我们通过动态编程所能获得的一样好。 实际上有一个对数复杂度算法,但是我在这里不讨论。
因此,从这些示例中我们可以看到,动态编程并没有什么神秘的或固有的困难。 它只需要您分析您的初始解决方案,确定重复工作的地点,并通过存储已经计算的结果来避免这种情况。 通过这种非常简单的优化,您可以从大多数实际输入值无法使用的指数解变为多项式解。 具体来说,您想寻找动态编程可能解决的两个独特问题: 重叠子问题和最佳子结构 。
重叠的子问题是指像斐波那契序列的问题,我们在这里看到,这里的主要问题(计算n个斐波那契),可以通过具有更小的子问题的解决方案, 而这些小的子问题的解决方案来解决,需要的性质一次又一次。 在那些情况下,有必要存储结果并在以后重新使用它们。
但是,如果子问题是完全独立的,而我们只需要一次结果,那么保存它们就没有任何意义。 可以划分为子问题但这些子问题不重叠的问题的一个示例是二元搜索 。 一旦我们丢弃了我们不关心的那一半,就再也不会访问它了。
最优子结构密切相关,这基本上意味着可以从子问题的最优解中高效构造出最优解。 在fibonacci示例中,此属性不是很明显,因为任何给定的n只有1个解。 但这在涉及某种优化的未来示例中将更加明显。
我将在这篇文章的结尾给出一些提示,这些提示将在尝试确定是否针对给定问题使用动态编程时使用:
- 问题可以分为相同的子问题吗?
- 我可以通过重复定义定义上一个除法吗? 也就是说,将F(n)定义为F(n-1)的函数
- 我需要多次还是仅一次将结果运用于子问题?
- 使用自上而下或自下而上的方法是否更有意义?
- 如果使用记忆式递归方法,是否需要担心堆栈?
- 我是否需要保留所有以前的结果,还是可以优化空间并仅保留其中一些?
在接下来的文章中,我将介绍一些经典且非常有趣的问题,这些问题可以使用动态编程有效地解决。
干杯!
翻译自: https://www.javacodegeeks.com/2014/02/dynamic-programming-introduction.html















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









