





阿里 深度学习 开源框架
深度学习越来越受到关注。 它主要侧重于机器学习的一个部分:人工神经网络。 本文解释了深度学习为何会改变分析的局面 ,何时使用它,以及Visual Analytics如何使业务分析人员利用(公民)数据科学家建立的分析模型。
什么是深度学习和人工神经网络?
深度学习(Deep Learning)是人工神经网络的现代流行语,它是机器学习中用于建立分析模型的众多概念之一。 神经网络的工作方式与我们从人脑中了解到的类似:您将非线性相互作用作为输入并将其传递给输出。 神经网络在输入和输出之间的计算节点中利用持续学习和不断增长的知识。 在大多数情况下,神经网络是一种监督算法,该算法使用历史数据集学习参数以预测未来事件的输出,例如用于交叉销售或欺诈检测。 无监督神经网络可用于查找新的模式和异常。 在某些情况下,将有监督和无监督算法结合起来是有意义的。
神经网络在研究中已经使用了数十年,其中包括各种复杂的概念,例如递归神经网络(RNN),卷积神经网络(CNN)和自动编码器。 但是,如今强大而又灵活的计算基础架构与其他技术(例如具有数千个内核的图形处理单元(GPU))相结合,可以在更深层次的层上进行更强大的计算。 因此,术语“深度学习”。
TensorFlow Playground的以下图片显示了一个易于使用的环境,其中包括各种测试数据集,配置选项和可视化,以学习和理解深度学习和神经网络:
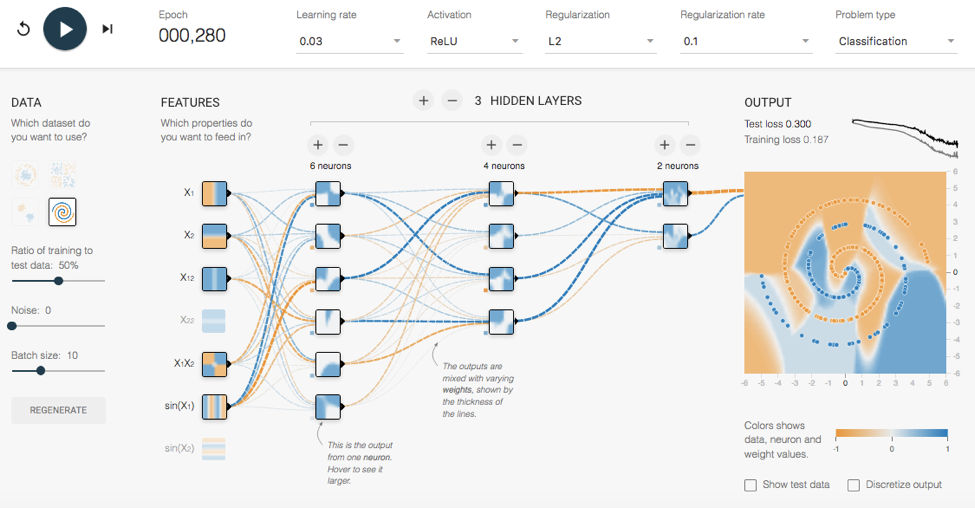
如果您想了解有关深度学习和神经网络的详细信息,我建议以下来源:
- “ 深度学习框架剖析 ” –有关神经网络的基本概念和组成部分的文章
- TensorFlow Playground无需任何编码即可亲自动手操作神经网络,也可在Github上使用以构建自己的定制离线游乐场
- 在YouTube上播放的“ 深度学习简化 ”视频系列,其中对基本概念,替代算法和一些框架(如H2O.ai或Tensorflow)进行了简短的简单说明
尽管深度学习越来越受青睐,但这并不是每种情况的灵丹妙药。
什么时候(不)使用深度学习?
深度学习提供了几年前“批量生产”中无法实现的许多新可能性,例如,与没有深度学习相比,图像分类,对象识别,语音翻译或自然语言处理(NLP)的方式要复杂得多。 关键优势是自动化功能工程,与其他大多数机器学习替代方法相比,这会花费大量时间和精力。
您还可以利用深度学习来做出更好的决策,增加收入或降低存在(“已解决”)问题的风险,而无需使用其他机器学习算法。 示例包括风险计算,欺诈检测,交叉销售和预测性维护。
但是,请注意,深度学习有一些重要的缺点:
- 非常昂贵,即速度慢且计算量大; 训练深度学习模型通常需要几天或几周的时间,与大多数其他算法相比,执行还需要更多时间。
- 难以解释:分析模型的结果缺乏可理解性; 通常是法律或合规性的关键要求
- 倾向于过度拟合,因此需要正规化
深度学习是解决复杂问题的理想选择。 在中等问题上,它也可以胜过其他算法。 深度学习不应用于简单的问题。 逻辑回归或决策树等其他算法可以更轻松,更快地解决这些问题。
开源深度学习框架
神经网络通常是使用各种开源实现之一来采用的。 各种成熟的深度学习框架可用于不同的编程语言。
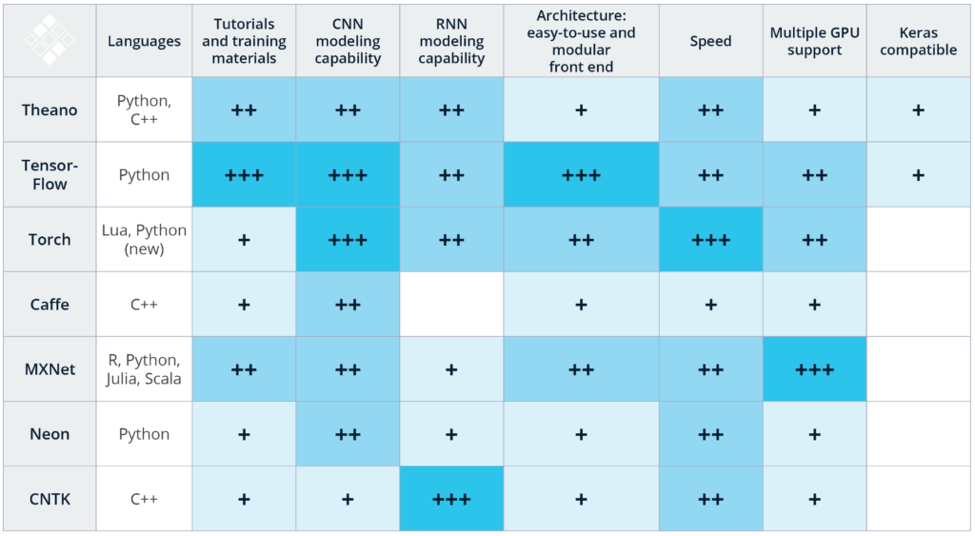
这些框架的共同点是,它们是为数据科学家(即具有编程,统计,数学和机器学习经验的角色)构建的。 请注意,编写源代码并不是一项艰巨的任务。 通常,只需要几行代码即可构建分析模型。 这与其他开发任务(如构建Web应用程序)完全不同,在Web应用程序中,您编写了数百或数千行代码。 在深度学习(通常是数据科学)中,最重要的是了解代码背后的概念,以建立良好的分析模型。
一些不错的开源工具(例如KNIME或RapidMiner)允许可视化编码来加快开发速度,还鼓励公民数据科学家(即,经验较少的人)学习概念并建立深层网络。 这些工具使用自己的深度学习实现或其他开放源代码库(例如H2O.ai或DeepLearning4j)作为引擎盖下的嵌入式框架。
如果您不想构建自己的模型或不希望将现有的预训练模型用于常见的深度学习任务,则还可以查看大型云提供商的产品,例如,用于文本到语音翻译的AWS Polly , Google用于图像内容分析的视觉API ,或用于构建聊天机器人的Microsoft Bot Framework 。 这些技术巨头在分析文本,语音,图片和视频方面拥有多年的经验,并在作为云服务的复杂分析模型中提供了丰富的经验; 现收现付。 您还可以使用自己的数据来改进这些现有模型,例如,使用特定行业或场景的照片来训练和改进通用图片识别模型。
深度学习与可视化分析相结合
无论您是想以自己喜欢的编程语言还是使用可视化编码工具“仅”使用框架:您都需要能够基于内置的神经网络做出决策。 这是视觉分析发挥作用的地方。 简而言之,可视化分析允许任何角色在分析复杂数据集时都可以做出数据驱动的决策,而不是倾听直觉。 请参阅“ 使用Visual Analytics做出更好的决策-在线指南 ”以更详细地了解关键优势。
业务分析师对深度学习一无所知,而只是利用集成的分析模型来回答其业务问题。 当业务分析师更改某些参数,功能或数据集时,将在后台应用分析模型。 但是,(公民)数据科学家也应该使用视觉分析来构建神经网络。 请参阅“ 如何避免在分析中使用反模式:机器学习的三个关键 ”,以更详细地了解技术人员和非技术人员应如何使用可视化分析来构建神经网络,从而帮助解决业务问题。 如“ 机器学习项目中的数据预处理与数据整理 ”中所述,甚至数据准备的某些部分也最好在可视化分析工具中完成。
从技术角度来看,深度学习框架(以及类似的其他任何机器学习框架)也可以通过不同的方式集成到可视化分析工具中。 以下列表包括每个替代方案的TIBCO Spotfire示例:
- 嵌入式分析:直接在分析工具(自我实现或“ OEM”)中实施; 可以由业务分析师使用,而无需任何有关机器学习的知识(Spotfire:通过对输入和输出数据进行一些简单的基本配置以及集群大小进行集群)
- 本机集成 :直接访问外部深度学习集群的连接器。 (Spotfire:TERR使用R的机器学习库,KNIME连接器直接与外部工具集成)
- 框架API :通过Wrapper API以不同的编程语言进行访问。 例如,您可以通过R集成MXNet或通过Python集成TensorFlow到可视化分析工具中。 此选项始终可以使用,如果没有本机集成或连接器可用,则该选项适用。 (Spotfire:通过Spotfire的TERR集成来使用任何R库的MXNet R接口)
- 通过分析服务器作为服务集成 :通过分析工具的服务器端组件间接连接外部深度学习集群; 分析工具可以以类似的方式访问不同的框架(Spotfire:用于SAS或Matlab等外部分析工具的Statistics Server)
- 云服务 :访问经过预训练的模型,用于常见的深度学习特定任务,例如图像识别,语音识别或文本处理。 不适合企业的非常具体的个人业务问题。 (Spotfire:通过Spotfire的TERR / R接口通过REST服务从AWS,Azure,IBM,Google调用公共深度学习服务,例如图像识别,语音翻译或Chat Bot)
所有选项的共同点是,您需要添加一些超参数的配置,即“高级”参数,例如问题类型,功能选择或正则化级别。 根据集成选项的不同,这可能是技术性很低的级别,也可能是简化且使用业务分析师理解的术语的灵活性较差。
深度学习示例:TIBCO Spotfire的自动编码器模板
让我们以一类特定的神经网络为例:自动编码器以查找异常。 自动编码器是一种无监督的神经网络,用于通过限制神经网络中的隐藏层数来复制输入数据集。 在预测时产生重建误差。 重建误差越高,该数据点异常的可能性就越高。
自动编码器的用例包括打击金融犯罪,监视设备传感器,医疗保健索赔欺诈或检测制造缺陷。 TIBCO社区免费提供通用的TIBCO Spotfire模板 。 您可以简单地添加数据集并利用自动编码器利用模板来查找异常-无需任何复杂的配置甚至编码。 该模板在后台使用H2O.ai的深度学习实现及其R API。 它在运行Spotfire的计算机上的本地实例中运行。 您也可以看一下R代码,但这完全不需要使用模板,因此是可选的。
真实示例:异常检测以进行预测性维护
让我们将Autoencoder用作实际示例。 在电信公司,您必须不断分析基础架构以发现网络中的问题。 最好在故障发生之前,这样您就可以在客户发现问题之前进行修复。 看下面的图片,它显示了电信网络的历史数据:
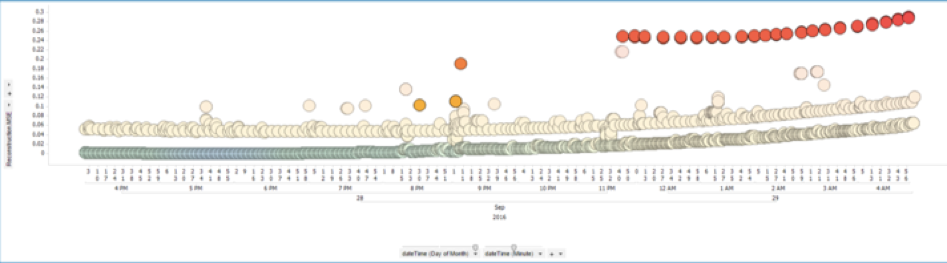
橙色点是尖峰,出现是基础设施中技术问题的第一个迹象。 红点表示不断出现故障,机械师不得不更换部分网络,因为它不再起作用。
自动编码器可用于在实际发生网络问题之前对其进行检测。 TIBCO Spotfire在后台使用H2O的自动编码器来查找异常。 如前所述,源代码相对稀缺。 这是使用H2O的深度学习R API构建分析模型并检测异常(通过找出自动编码器的重构错误)的片段:
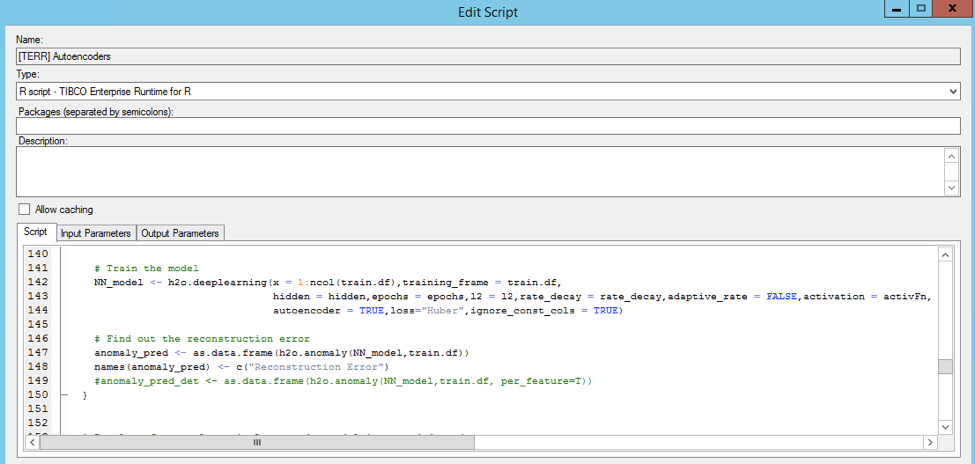
由数据科学家构建的此分析模型已集成到TIBCO Spotfire中。 业务分析师能够直观地分析历史数据和自动编码器的见解。 这种结合使数据科学家和业务分析师可以流畅地合作。 实施预测性维护并通过降低风险和成本创造巨大的业务价值从未如此简单。
通过流分析将分析模型应用于实时处理
本文重点介绍使用数据科学框架和可视化分析构建深度学习模型。 项目成功的关键是将构建分析模型实时应用于新事件,以增加业务价值,例如增加收入,降低成本或降低风险。
“ 如何将机器学习应用于事件处理 ”更详细地描述了如何将分析模型应用于实时处理。 或者观看利用TIBCO StreamBase实时应用某些H2O模型的相应视频记录。 最后,我建议您学习各种流分析框架以应用分析模型 。
让我们回到Autoencoder用例,以在电信公司中实现预测性维护。 在TIBCO StreamBase中,您可以通过StreamBase的H2O连接器轻松应用构建的H2O自动编码器模型,而无需进行任何重新开发。 您只需附加H2O框架生成的Java代码,其中包含分析模型并编译为性能非常好的JVM字节码:
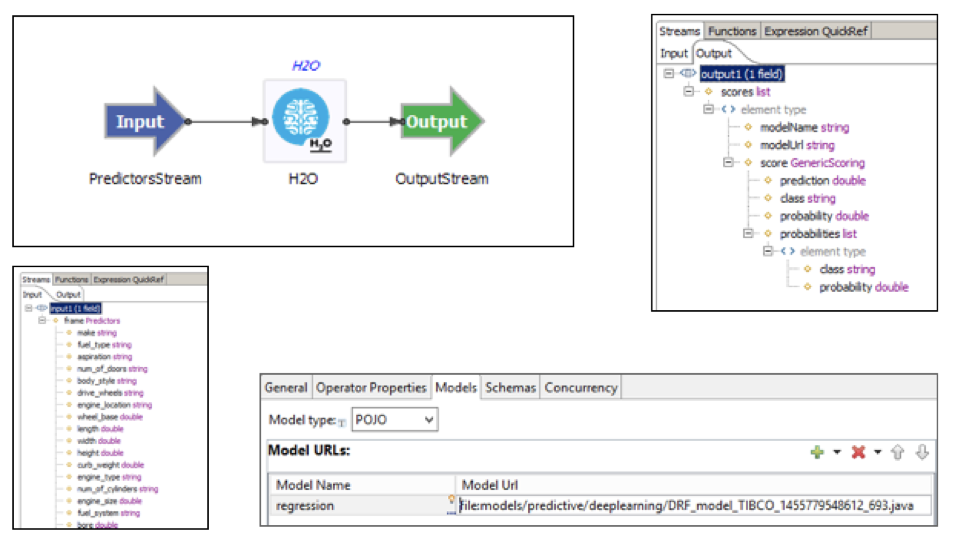
获得的最重要的教训:构建分析模型之前,请考虑执行要求。 关于延迟,您需要什么性能? 您每分钟,每秒或毫秒需要处理多少个事件? 您是否需要将分析模型分发到具有多个节点的集群? 您需要多久改进和重新部署分析模型一次? 您需要在项目开始时回答这些问题,以避免双重努力和分析模型的重新开发!
另一个重要的事实是,分析模型并不总是需要非常快速或频繁地评分(例如,如果您想对传感器分析用例中的每个事件评分)。 在上面的电信基础架构示例中,这些峰值和故障可能在随后的几天甚至几周内发生。 因此,在许多用例中,每小时一次甚至每天一次对分析模型进行评分是很好的。
深度学习+视觉分析+流分析=下一代大数据成功案例
深度学习允许以更有效的方式解决许多众所周知的问题,例如交叉销售,欺诈检测或预测性维护。 此外,可以解决更多的情况下,这是不可能的前解决,如准确,高效的对象检测或者语音到文本的转换。
视觉分析是深度学习项目取得成功的关键组成部分。 它简化了(公民)数据科学家的深度神经网络的开发,并使业务分析师能够利用这些分析模型来找到新的见解和模式。
如今,(公民)数据科学家使用R或Python等编程语言,Theano,TensorFlow,MXNet或H2O的Deep Water等深度学习框架以及TIBCO Spotfire等视觉分析工具来构建深度神经网络。 分析模型被嵌入到视图中,以供业务分析师在不了解技术细节的情况下利用它。
将来,视觉分析工具可能会像现在已经嵌入神经网络功能一样嵌入神经网络功能,例如它们已经嵌入其他机器学习功能,例如聚类或逻辑回归。 这将使业务分析师无需数据科学家的帮助即可利用深度学习,并且适合于更简单的用例。
但是,请不要忘记构建分析模型以找到见解只是项目的第一部分。 之后将其实时部署与第二步一样重要。 查找见解的工具与将见解应用于新事件之间的良好集成可以大大缩短数据科学项目的上市时间和模型质量。 开发生命周期是一个连续的闭环。 分析模型需要进行验证,并按特定顺序进行重建。
翻译自: https://www.javacodegeeks.com/2017/04/visual-analytics-open-source-deep-learning-frameworks.html
阿里 深度学习 开源框架















 2303
2303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









