





cassandra
DuyHai Doan是DataStax的Apache Cassandra传播者。 他在Cassandra的技术演示/会议之间花费时间,在开源项目上编码以支持社区,并帮助所有使用Cassandra的公司使他们的项目成功。 之前,他是一名自由Java / Cassandra顾问。
在此博客文章中,我们将解释为什么所有Cassandra专家和福音传教士都推广单分区操作的原因。 我们将详细介绍单分区操作在操作 , 一致性和系统稳定性方面可以提供的所有好处。
原子性和隔离
保证对分区所有列的更改( INSERT / UPDATE / DELETE )是原子的,例如,将同一行中N列的更新视为一次写入操作。
此原子性属性很重要,因为它可以确保客户端应用所有突变或不应用任何突变 。
多个分区突变目前无法提供原子性(至少直到CASSANDRA-7056 “ RAMP Transaction ”完成)。 多个分区上的原子性将需要设置协调系统(例如全局锁定)或发送额外的元数据(例如在RAMP Transaction中)。
同样,对单个分区的突变被隔离在副本上,例如,直到客户端1完成写入突变,另一个客户端2将无法读取它们。 出于与上述相同的原因,不能单独应用多个分区。
批量
我们的技术传教士过去常常抱怨记录的批次 。 批次使用不当会导致节点故障并损害系统稳定性。
当您向多个分区发送带有突变的已记录批处理时,将发生以下情况:
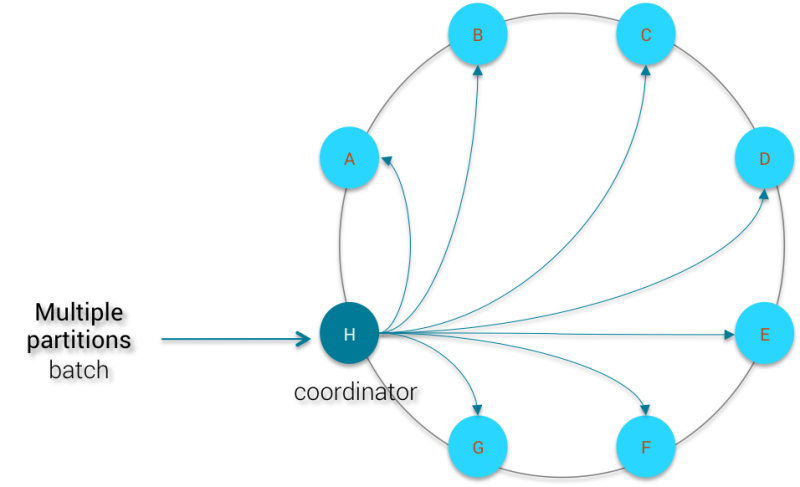
多分区批处理
由于具有高分布性, Murmur 3分区程序将在整个群集中均匀分布每个分区。 因此,在删除本地存储的日志批处理之前, 协调器节点将必须等待集群中的N个节点( 为简化起见,N =日志批处理中不同分区键的数量 )来确认突变。 在所有N个节点都发送回ack之前,无法从协调器中删除已记录的批处理。 拥有100个节点的集群,此记录的批次将极大地影响协调器的稳定性。
现在,让我们看看协调器如何处理单个分区记录的批处理 :
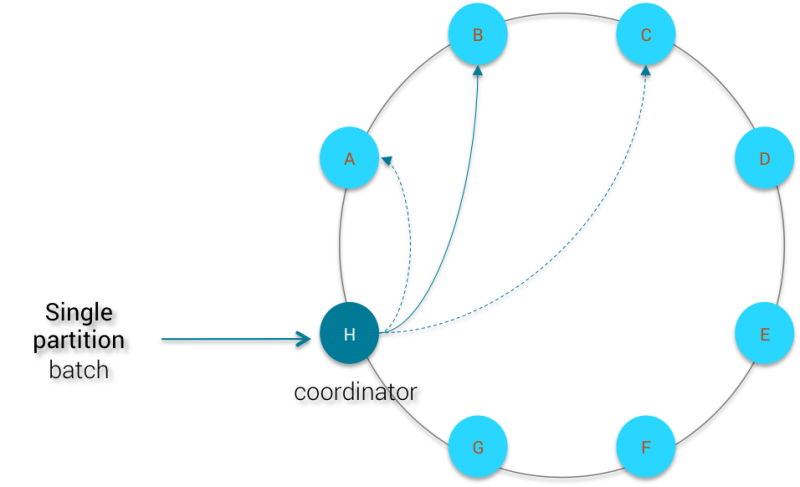
单分区批处理
突变被发送到所有副本节点,并且协调器在删除记录的批处理之前等待RF确认(RF =复制因子)。 在这种情况下,群集的大小无关紧要,因为批处理涉及的节点数受复制因子的约束。
次要指标
Cassandra中的二级索引是一个有用的功能,但由于两个主要原因,很难正确使用:
- 次要索引不能随群集大小很好地扩展。实际上,这些索引与基本数据一起分布 ,因此使用这些索引进行查询至少需要命中群集中的N / RF个节点, N是群集中的节点总数/数据中心和RF被复制factor.As一个例子,如果有一个100个节点与RF = 3簇,与二级索引查询将很可能击中34个节点 (100/3向上舍入到34)。
- 基数非常高而基数非常低。想像一下,您有一个带有“ 性别”列的表用户 。 表的主键是user_id 。 您希望能够按性别查找用户,因此很想在此列上创建二级索引。 但是,由于性别的可能值只有2个,因此在每个节点上,所有用户都只能分布在2个宽分区( MALE和FEMALE )之间。另一个示例是在用户的电子邮件上创建二级索引,以便能够找到他们通过他们的电子邮件。 问题是,对于1个用户,最多有1个不同的电子邮件(很少有2个用户具有相同的电子邮件地址)。 因此,在发出类似查询时:
SELECT * FROM users WHERE email='doanduyhai@nowhere.com';Cassandra将命中N / RF节点,最多只能检索1行,有时根本没有结果。 因此,仅查找1行所付出的成本实在让人望而却步
二级索引的唯一良好且可扩展的用例是将查询限制在单个分区上。 假设我们具有以下架构来存储传感器数据:
CREATE TABLE sensors(
sensor_id uuid,
date timestamp,
location text,
value double,
PRIMARY KEY(sensor_id, date)
);
CREATE INDEX location_idx ON sensors(location);
CREATE INDEX value_idx ON sensors(value);我们为传感器创建了以上2个索引,以按传感器位置和传感器值进行查询。 以下查询将是高性能且可扩展的,因为我们每次都会提供分区键( sensor_id ),因此Cassandra不会命中N / RF节点,而只会搜索单个节点中的数据。
//Give all values of my sensor when it is in Los Angelest
SELECT value FROM sensors WHERE sensor_id='de305d54-75b4-431b-adb2-eb6b9e546014
' AND location='Los Angeles';
//Give me the moment and the location of my sensor when it has value 4.5
SELECT date,location FROM sensors WHERE sensor_id='de305d54-75b4-431b-adb2-eb6b9e546014
' AND value=4.5;轻量级交易
在Cassandra 2.0中引入了LightWeight Transactions(LWT) ,以解决一类可能需要外部锁管理器的问题。
在后台,Cassandra正在实现Paxos协议以保证突变的线性化。 它类似于分布式“比较和交换”操作。
借助LWT ,您可以使用INSERT INTO(如果不存在)和DELETE(如果存在)来模拟完整性约束。 显然,这两个操作是单个分区。
也可以使用LightWeight Transactions使用语法UPDATE…进行条件更新:SET col 1 = xxx WHERE partition_key = yyy IF col 2 = zzz; ,唯一的约束是要检查的条件列应与要更新的列属于同一行(属于同一分区)。
同样,您可以发出包含一个LWT突变的批处理语句,前提是所有其他突变都使用与使用LWT的相同的分区键。 例
CREATE TABLE stock_order (
order_id uuid,
order_state static text, // OPEN or CLOSED
item_id int,
item_amount double,
PRIMARY KEY (order_id, item_id)
);
// Batch insert new items into the given order and close it
BEGIN LOGGED BATCH
INSERT INTO stock_order(order_id,item_id,item_amount) VALUES('de305d54-75b4-431b-adb2-eb6b9e546014
', 5, 460000.0);
INSERT INTO stock_order(order_id,item_id,item_amount) VALUES('de305d54-75b4-431b-adb2-eb6b9e546014
', 6, 50000);
INSERT INTO stock_order(order_id,item_id,item_amount) VALUES('de305d54-75b4-431b-adb2-eb6b9e546014
', 7, 1200000);
UPDATE stock_order SET order_state='CLOSED' WHERE order_id='de305d54-75b4-431b-adb2-eb6b9e546014
' IF order_state='OPEN';
END BATCH在上面的示例中,如果给定订单已被某些其他进程关闭,则条件更新( IF order_state ='OPEN' )将失败,因此将不执行任何插入操作。 这是LWT的一大特色。 它为您的操作提供了强大的线性化保证。
如果您要将这些订单更新和变异分布在不同的分区中,那么LWT将不适用,您将回到最终的一致性世界。
用户定义的聚合
最后但并非最不重要的一点是,最近发布的用户定义的聚合(UDA)功能在单个分区上效果最佳。 在不深入研究技术细节的情况下,您应该知道,Cassandra中的聚合函数在最后写赢对帐逻辑之后应用于协调器节点。
因此,在多个分区或整个表上执行聚合将需要协调器在应用UDA之前从不同节点获取所有数据(实际上是使用内部分页 )。 在这种情况下,聚合查询的延迟会绑定到最慢节点的延迟。 此外,多分区聚合需要获取更多数据,因此会大大增加查询持续时间。
出于所有这些原因,当前的建议是仅将UDA保留给单个分区,如果要在其中聚合整个表或几个分区,则依赖Apache Spark 。
有关UDA的更多详细信息,您可以阅读以下博客文章:
翻译自: https://www.javacodegeeks.com/2016/02/importance-single-partition-operations-cassandra.html
cassandra















 2733
2733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









