





elk kibana
在我当前的项目之一中,我们使用Cassandra和Spark Streaming进行了一些接近实时的分析。 Datastax的好伙伴已经建立了Cassandra和Spark的商业包装(Datastax Enterprise,又名DSE),使您可以轻松地建立和运行此堆栈。 Datastax产品不包括的一件事是一种汇总所有这些组件中的日志的方法。 整个集群中有很多进程在运行,每个进程都会生成日志文件。 另外,spark为每个应用程序和驱动程序创建日志目录,每个目录都有自己的日志。 在大量日志文件和事实之间,工作在所有节点上都不同,这取决于数据的划分方式,这可能会成为一个巨大的浪费时间,您需要四处寻找和关注您所关心的日志消息。
输入ELK堆栈。 ELK由三种产品组成:
- Elasticsearch –分布式索引和搜索平台。 它在精美的分布式,高度可用的全文本和半结构化文本搜索系统之上提供了REST接口。 它在内部将Lucene用于反向索引和搜索。
- Logstash –日志聚合器和处理器。 这可以从许多不同来源获取日志提要,对其进行过滤和变异,然后将它们输出到其他地方(在这种情况下为Elasticsearch)。 Logstash是需要了解您的日志消息中具有任何结构的部分,以便可以提取该结构并将该半结构化数据发送到elasticsearch。
- Kibana –基于Web的交互式可视化和查询工具。 您可以浏览原始数据,并将其转换为精美的汇总图表并构建仪表板。
所有这三个都是由Elastic开发的开源Apache 2许可项目, Elastic是由创建Elasticsearch和Lucene的人创建的公司。 他们拥有所有的培训,专业服务和生产支持订阅,并且产品名称稳定,您不确定是否需要……。
那么,从高角度看呢? Spark和Cassandra运行在同一盒子上。 这是设计使然,因此您的Spark作业可以使用RDD,这些RDD使用了解Cassandra环形拓扑的分区方案。 这样可以最大程度地减少在线数据混洗,从而提高性能。 此图从较高的层次显示了每个进程在此分布式环境中的位置:
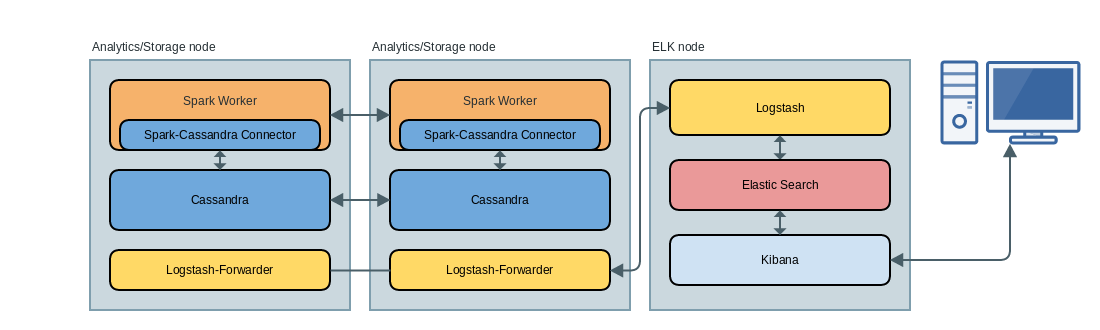
这仅描绘了两个“分析”节点和一个ELK节点,但是显然每个都有更多。 每个分析节点将产生大量日志。 Spark将日志写入:
- / var / log / spark / worker
- / var / lib / spark / worker / worker-0 / app- {somelongtimestamp} / {taskslot#}
- / var / lib / spark / worker / worker-0 / driver- {somelongtimestamp}
为了收集所有这些日志并转发,在每个称为Logstash-Forwarder的节点上都有一个代理进程,该进程正在监视用户指定的文件夹中是否有新的日志文件,并将它们通过TCP传送到ELK节点上运行的实际Logstash服务器进程中。 Logstash接收这些传入的提要,对其进行解析并将其发送给elasticsearch。 Kibana响应我的交互式查询,并将所有搜索工作委托给elasticsearch。 Kibana不会在内部存储任何结果,也不会拥有自己的索引或任何东西。
其他人已经做得很好, 解释了如何设置ELK以及如何使用Kibana ,因此在此我将不再赘述。 我将仅强调其中的一些差异,并共享为处理Cassandra和Spark(至少在DSE 4.7中打包)的开箱即用日志文件格式而创建的Logstash配置文件。
我从回购中安装了elasticsearch,该回购已经创建了systemd条目以将其作为服务运行。 按照上面的ELK设置链接,我为logstash和kibana创建了systemd条目。 我还为在每个分析节点上运行的logstash-forwarder创建了一个systemd单位文件 。
需要为logstash-forwarder配置spark和cassandra将放置日志文件的所有位置。 它支持glob语法,包括诸如“ whatever / ** / *。log”之类的递归文件夹搜索,但是我最终没有使用它,因为由于在spark驱动程序日志文件夹下创建了一个奇怪的子文件夹,它正在复制某些条目称为cassandra_logging_unconfigured。 我的转发器配置为工作程序,应用程序和驱动程序选择了所有输出日志,并为每个日志文件创建了不同的类型 : spark-worker用于通用/ var / log spark输出, spark-app用于app- *日志文件夹,驱动程序的spark-driver (大多数有趣的日志记录都发生在这里)。 我的logstash-forwarder.conf在要点中。
对于logstash,我将一些文件设置为管道以处理传入的日志提要:
- 00_input.conf –设置伐木工人(转发器使用的协议)端口并配置证书
- 01_cassandra_filter.conf –解析DSE为cassandra提供的注销格式。 我不确定香草开源卡桑德拉是否通过默认使用相同的名称。 有时有两种格式之间,有时会有一个额外的价值-可能来自NDC的等效logback。
- 02_spark_filter.conf –解析DSE传递给spark的logback格式。 我看到这里也有两种格式。 有时带有行号,有时没有。
- 07_last_filter.conf –这是一个多行过滤器,可识别Java 堆栈跟踪并使它们与原始消息保持一致
- 10_output.conf –将所有内容发送到elasticsearch
我的所有配置文件都可以通过本要点上方的链接获得。 如果您需要使用ELK监视cassandra和spark日志,则可以在上面的链接指南和此处的配置之间进行操作!
快速提示:在配置和正常工作时,可能需要终止当前索引的数据并重新发送所有数据(以便可以重新解析和重新索引)。 .logstash-forwarder在启动转发器的工作目录中保留一个名为.logstash-forwarder的元数据文件。 如果您想杀死所有索引数据并重新发送所有内容,请按照下列步骤操作:
- 杀死logstash-forwarder:
sudo systemctl stop logstash-forwarder - 删除logstash-forwarder元数据,以便下次从头开始:
sudo rm /var/lib/logstash-forwarder/.logstash-forwarder - 如果您需要更改任何logstash配置文件,请执行此操作,然后重新启动logstash:
sudo systemctl restart logstash - 删除您现有的弹性搜索索引(请小心!):
curl -XDELETE 'http://:9200/logstash-*' - 再次
sudo systemctl start logstash-forwarder:sudo systemctl start logstash-forwarder
另请注意,默认情况下,logstash-forwarder仅会提取少于24小时的文件。 因此,如果要配置ELK并在停滞的数据上使用筛选器,请确保最近至少触摸了一些文件,以便将其选中。 在/ var / log / logstash-forwarder中检出日志文件,以查看它是否正在跳过特定条目。 您还可以使用-verbose运行logstash-forwarder以查看其他调试信息。
快速提示:使用非常有用的http://grokdebug.herokuapp.com/测试您的增长正则表达式模式,以确保它们匹配并提取您想要的字段。
elk kibana















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









