





php与nosql
几周前,我遇到了肖恩·泰勒 ( Sean Taylor)的一条推文,询问一条具有数年记录价值的天气数据集,而令我惊讶的是,得知R已经有了这样的东西– weatherData软件包。
优胜者是: @UTVilla ! 图书馆(weatherData)df <-getWeatherForYear(“ SFO”,2013)ggplot(df,aes(x = Date,y = Mean_TemperatureF))+ geom_line()
—肖恩·泰勒(@seanjtaylor) 2015年1月22日
weatherData在wunderground API周围提供了薄薄的贴面,这正是我一直想要的,用于比较伦敦NoSQL的聚会与当天的天气情况。
第一步是下载适当的天气记录并将其保存到CSV文件,这样我就不必继续调用API。
我以为我也可以下载所有可用的录音,并编写以下代码来实现:
library(weatherData)
# London City Airport
getDetailedWeatherForYear = function(year) {
getWeatherForDate("LCY",
start_date= paste(sep="", year, "-01-01"),
end_date = paste(sep="", year, "-12-31"),
opt_detailed = FALSE,
opt_all_columns = TRUE)
}
df = rbind(getDetailedWeatherForYear(2011),
getDetailedWeatherForYear(2012),
getDetailedWeatherForYear(2013),
getDetailedWeatherForYear(2014),
getWeatherForDate("LCY", start_date="2015-01-01",
end_date = "2015-01-25",
opt_detailed = FALSE,
opt_all_columns = TRUE))然后,我将其保存到CSV文件中:
write.csv(df, 'weather/temp_data.csv', row.names = FALSE)"Date","GMT","Max_TemperatureC","Mean_TemperatureC","Min_TemperatureC","Dew_PointC","MeanDew_PointC","Min_DewpointC","Max_Humidity","Mean_Humidity","Min_Humidity","Max_Sea_Level_PressurehPa","Mean_Sea_Level_PressurehPa","Min_Sea_Level_PressurehPa","Max_VisibilityKm","Mean_VisibilityKm","Min_VisibilitykM","Max_Wind_SpeedKm_h","Mean_Wind_SpeedKm_h","Max_Gust_SpeedKm_h","Precipitationmm","CloudCover","Events","WindDirDegrees"
2011-01-01,"2011-1-1",7,6,4,5,3,1,93,85,76,1027,1025,1023,10,9,3,14,10,NA,0,7,"Rain",312
2011-01-02,"2011-1-2",4,3,2,1,0,-1,87,81,75,1029,1028,1027,10,10,10,11,8,NA,0,7,"",321
2011-01-03,"2011-1-3",4,2,1,0,-2,-5,87,74,56,1028,1024,1019,10,10,10,8,5,NA,0,6,"Rain-Snow",249
2011-01-04,"2011-1-4",6,3,1,3,1,-1,93,83,65,1019,1013,1008,10,10,10,21,6,NA,0,5,"Rain",224
2011-01-05,"2011-1-5",8,7,5,6,3,0,93,80,61,1008,1000,994,10,9,4,26,16,45,0,4,"Rain",200
2011-01-06,"2011-1-6",7,4,3,6,3,1,93,90,87,1002,996,993,10,9,5,13,6,NA,0,5,"Rain",281
2011-01-07,"2011-1-7",11,6,2,9,5,2,100,91,82,1003,999,996,10,7,2,24,11,NA,0,5,"Rain-Snow",124
2011-01-08,"2011-1-8",11,7,4,8,4,-1,87,77,65,1004,997,987,10,10,5,39,23,50,0,5,"Rain",230
2011-01-09,"2011-1-9",7,4,3,1,0,-1,87,74,57,1018,1012,1004,10,10,10,24,16,NA,0,NA,"",242如果我们想在以后阅读,可以使用以下代码:
weather = read.csv("weather/temp_data.csv")
weather$Date = as.POSIXct(weather$Date)
> weather %>% sample_n(10) %>% select(Date, Min_TemperatureC, Mean_TemperatureC, Max_TemperatureC)
Date Min_TemperatureC Mean_TemperatureC Max_TemperatureC
1471 2015-01-10 5 9 14
802 2013-03-12 -2 1 4
1274 2014-06-27 14 18 22
848 2013-04-27 5 8 10
832 2013-04-11 6 8 10
717 2012-12-17 6 7 9
1463 2015-01-02 6 9 13
1090 2013-12-25 4 6 7
560 2012-07-13 15 18 20
1230 2014-05-14 9 14 19下一步是将天气数据与我已经拥有的聚会出席数据一起使用。
为了简单起见,我将它们保存在CSV文件中,因为我们也可以读取它们:
timestampToDate <- function(x) as.POSIXct(x / 1000, origin="1970-01-01", tz = "GMT")
events = read.csv("events.csv")
events$eventTime = timestampToDate(events$eventTime)
> events %>% sample_n(10) %>% select(event.name, rsvps, eventTime)
event.name rsvps eventTime
36 London Office Hours - Old Street 10 2012-01-18 17:00:00
137 Enterprise Search London 34 2011-05-23 18:15:00
256 MarkLogic User Group London: Jim Fuller 40 2014-04-29 18:30:00
117 Neural Networks and Data Science 171 2013-03-28 18:30:00
210 London Office Hours - Old Street 3 2011-09-15 17:00:00
443 July social! 12 2014-07-14 19:00:00
322 Intro to Graphs 39 2014-09-03 18:30:00
203 Vendor focus: Amazon CloudSearch 24 2013-05-16 17:30:00
17 Neo4J Tales from the Trenches: A Recommendation Engine Case Study 12 2012-04-25 18:30:00
55 London Office Hours 10 2013-09-18 17:00:00现在我们已经准备好两个数据集,我们可以绘制一个简单的图表,将平均出勤率和温度按月分组:
byMonth = events %>%
mutate(month = factor(format(eventTime, "%B"), levels=month.name)) %>%
group_by(month) %>%
summarise(events = n(),
count = sum(rsvps)) %>%
mutate(ave = count / events) %>%
arrange(desc(ave))
averageTemperatureByMonth = weather %>%
mutate(month = factor(format(Date, "%B"), levels=month.name)) %>%
group_by(month) %>%
summarise(aveTemperature = mean(Mean_TemperatureC))
g1 = ggplot(aes(x = month, y = aveTemperature, group=1), data = averageTemperatureByMonth) +
geom_line( ) +
ggtitle("Temperature by month")
g2 = ggplot(aes(x = month, y = count, group=1), data = byMonth) +
geom_bar(stat="identity", fill="dark blue") +
ggtitle("Attendance by month")
library(gridExtra)
grid.arrange(g1,g2, ncol = 1) 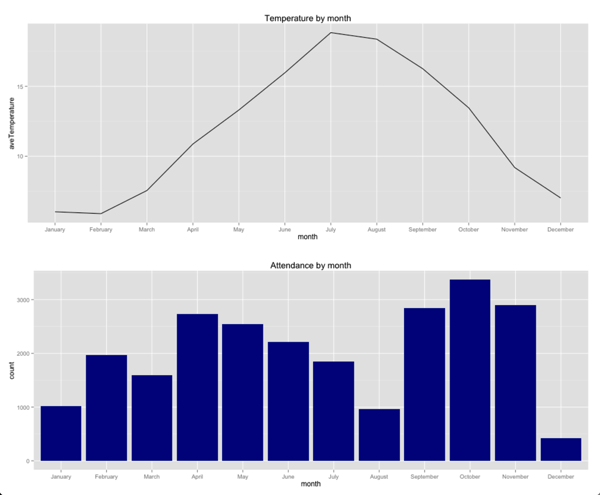
我们可以看到温度和出勤率之间存在大致的反相关关系,尤其是在4月和8月之间–随着温度的升高,总出勤率下降。
但是,如果我们在更细粒度的级别(例如特定日期)进行比较,该怎么办? 为此,我们可以在事件数据框中添加“天”列,然后将其与天气数据合并:
byDay = events %>%
mutate(day = as.Date(as.POSIXct(eventTime))) %>%
group_by(day) %>%
summarise(events = n(),
count = sum(rsvps)) %>%
mutate(ave = count / events) %>%
arrange(desc(ave))
weather = weather %>% mutate(day = Date)
merged = merge(weather, byDay, by = "day")现在我们可以绘制出各天的出勤率与平均温度的关系图:
ggplot(aes(x =count, y = Mean_TemperatureC,group = day), data = merged) +
geom_point() 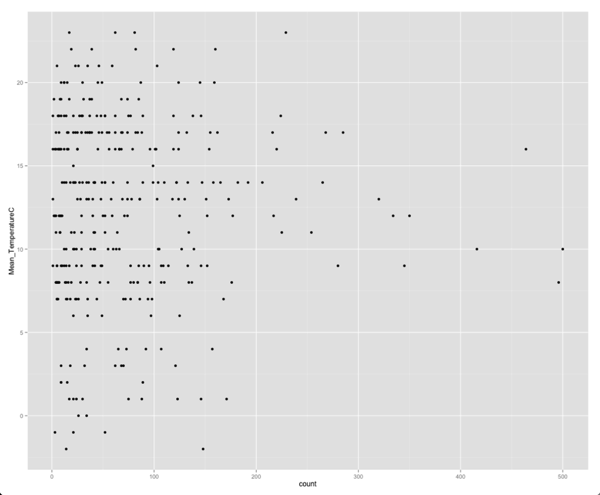
有趣的是,现在温度和出勤率之间似乎没有任何关联。 我们可以通过运行相关性来证实我们的怀疑:
> cor(merged$count, merged$Mean_TemperatureC)
[1] 0.008516294值之间甚至没有1%的相关性! 我们可以确认不相关的一种方法是将平均温度与平均出勤率而不是总出勤率作图:
g1 = ggplot(aes(x = month, y = aveTemperature, group=1), data = averageTemperatureByMonth) +
geom_line( ) +
ggtitle("Temperature by month")
g2 = ggplot(aes(x = month, y = ave, group=1), data = byMonth) +
geom_bar(stat="identity", fill="dark blue") +
ggtitle("Attendance by month")
grid.arrange(g1,g2, ncol = 1) 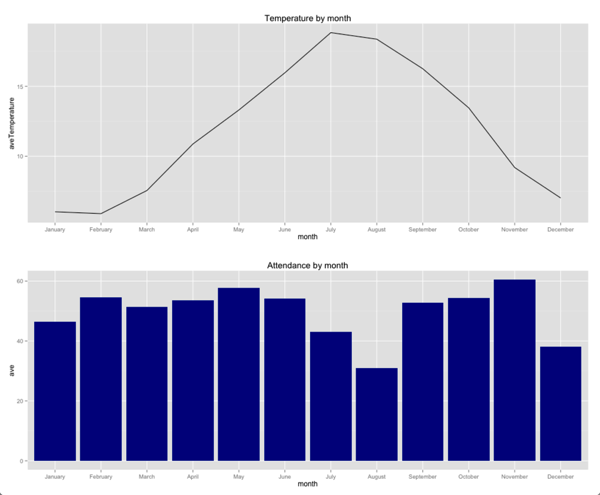
现在,我们可以看到温度和月份之间的关系并不大,实际上,有9个月的平均出勤率非常相似。 只有在7月,12月,尤其是8月,会有明显的下降。
这可能表明,除了温度以外,还有其他变量会影响这几个月的出勤率。 我的假设是,在学校放假的几周内出勤率会下降–主要发生在7月/ 8月,12月和3月/ 4月(有趣的是没有出现下降!)
需要考虑的另一件有趣的事情是出席率下降的原因是否不是由于缺乏与会者的意愿,而是因为实际上没有任何活动要参加。 让我们根据温度绘制每个月托管的事件数:
g1 = ggplot(aes(x = month, y = aveTemperature, group=1), data = averageTemperatureByMonth) +
geom_line( ) +
ggtitle("Temperature by month")
g2 = ggplot(aes(x = month, y = events, group=1), data = byMonth) +
geom_bar(stat="identity", fill="dark blue") +
ggtitle("Events by month")
grid.arrange(g1,g2, ncol = 1) 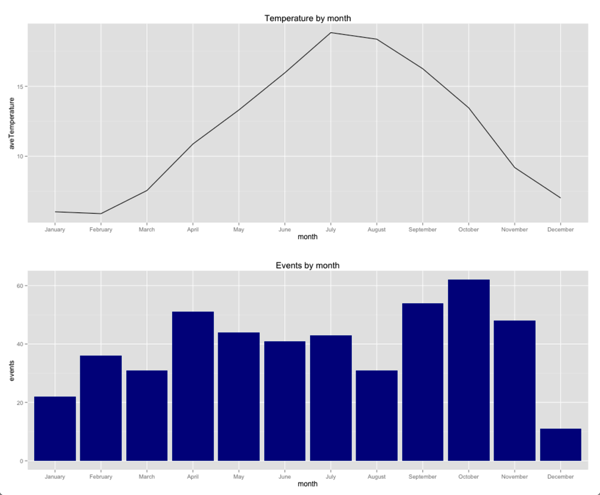
在这里,我们注意到12月的活动大幅减少–组织者举办的活动减少了,从我们之前的研究中我们知道,参加这些活动的人数平均有所减少。 秋季举办许多活动,Spring举办的活动较少,特别是在一月,三月和八月的活动较少。
同样,温度与特定日期举办的事件数量之间没有特定的关联:
ggplot(aes(x = events, y = Mean_TemperatureC,group = day), data = merged) +
geom_point() 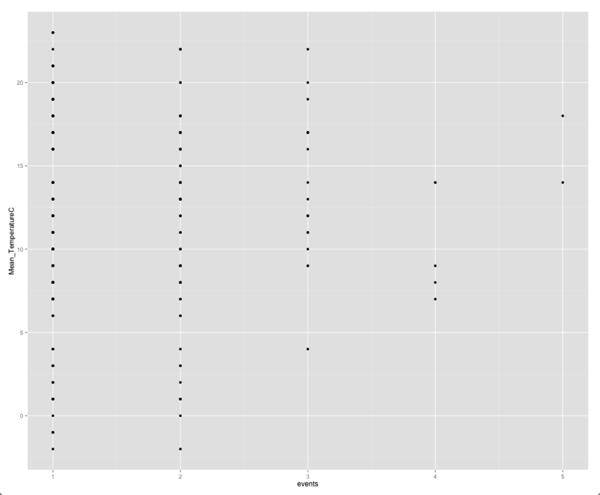
查看该图没有明显的相关性,尽管我发现很难解释这样的图:在这些图上,我们将所有值都集中在一个轴上的极少点(通常是因子变量)周围,而在另一个轴上分散(连续变量)。 让我们通过计算这两个变量之间的相关性来证实我们的怀疑:
> cor(merged$events, merged$Mean_TemperatureC)
[1] 0.0251698然后回到我的出勤预测模型的绘图板!
如果您有任何建议要更有效地进行此分析,或者我有任何错误,请在评论中让我知道,我仍在学习如何调查实际告诉我们的数据。
翻译自: https://www.javacodegeeks.com/2015/02/r-weather-vs-attendance-nosql-meetups.html
php与nosql















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









