





分析堆栈溢出原因
如何在Stack Overflow中表达问题以便获得更好的答案
Stack Overflow提供了一个很好的界面,用于访问其所有数据并在问题/答案数据库中运行任何可能的查询。 我们开始使用该数据库来更好地了解有关调试的最常见问题(我们将在Takipi尝试解决的问题 )。 在通过数千个问题学习调试的同时,我们还注意到了一个额外的好处:我们开始更好地了解是什么导致了Stack Overflow社区。 
本文是研究10,000多个Stack Overflow问题的结果。 它总结了如何用短语表达问题并得到更好更快的答案。 当我们开始根据查询的答案运行脚本时,我们不确定会得出可靠的结论。 但是,在研究了数百个问题之后,我们已经开始认识到我们在不同的编程语言和主题之间反复看到的某些独特模式。
您可以在本文结尾处找到有关我们如何执行测试的详细说明,但让我们首先了解最好的部分-结果。 我们为“好”问题设定的主要标准是(从具有较高声誉和投票的用户那里)获得高质量的答案,相对较快地获得答案以及投票和意见的数量。
简短一点
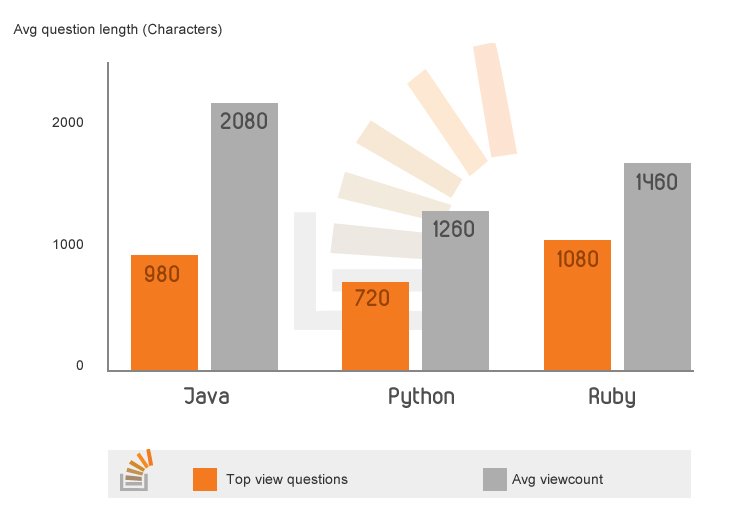
我们在运行的所有不同查询和脚本中看到的最强模式可能是:问题越短,您越有可能获得快速而有用的答案。 “好”问题的平均长度约为1200个字符(约3-4个简短段落),而标准问题的平均长度则为1800个字符。 长度的最强影响是观看次数和票数,其中最常见问题的平均长度约为标准问题的50%。
也没有太短的问题-真正简短的问题(大约200-300个字符)可获得最佳结果。
我们发现标题的长度无关紧要。 虽然我们看到了问题的总长度的影响,但标题的长度似乎对问题的质量影响很小。 前题的平均标题长度比标准标题的平均长度短约5%(47个字符对50个字符)。
排名第一的影响者-提问者的声誉
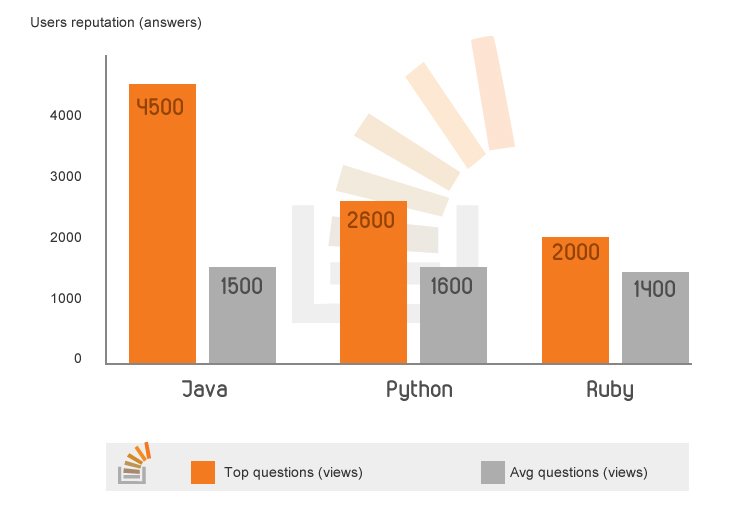
询问者的声誉对答案的数量和质量以及回复速度有很大的影响。 信誉较高的用户似乎也倾向于更频繁地答复信誉较高的用户。 虽然我们看到简短的问题获得更好和更快的答案的可能性要高出50-100%,但信誉极高的用户提出的问题的答案是低端用户提出的更好的答案的可能性是三倍声誉。 当然,您可能会得出这样的结论:信誉较高的用户会提出更好的问题。 的确是事实,但是我们看到了信誉低下的用户所提出的一些非常相似的问题,并且答案质量上的区别很明显。
一些示例:最佳答案的前100个Java问题的平均提问者声誉(给出答案+投票的用户的较高声誉)为4500点。 标准Java问题的平均提问者声誉为1500。
在15分钟内回答的Ruby问题的平均提问者信誉为2400。在24小时后回答的Ruby问题的平均提问者信誉为1300。
100个观看次数最多的Java问题的平均提问者声誉为3150,而标准问题的平均声誉为1100。
我应该使用代码片段吗?
在问题中嵌入代码段是我们测试的少数几个参数之一,这些参数在不同语言之间给出了非常清晰的结果,但在不同条件下却给出了相反的结果。 似乎包括代码片段在内的问题似乎可以获得更好的答案-票数更高且信誉较高的用户的答案。 例如,具有很高声誉的用户回答的Python相关问题中有87%包含代码段。 平均Python问题中有64%包含代码段。 与Ruby相关的问题显示出相似的结果-最高的问题中有91%包含代码片段,而平均比例为79%。
关于投票,意见和直到第一个答案的时间,趋势是相反的-例如,58%的最受欢迎的Python问题包括代码段。 平均观看次数为72%的问题包含代码段。 似乎与问题的长度有关—代码段导致问题较长,而结果却较低。
使用更少的标签
差异不大,但似乎在我们测试的不同标准下,结果排名最高的标签少于平均值。 获得高质量答案,更快答复和更多投票的问题平均具有3个标签(不同语言似乎相同)。 标准问题有大约3.5 – 3.7个标签。
什么时候是发布问题的最佳时间?
从我们的数据来看,一天中的时间似乎并不影响结果。 堆栈溢出“高峰时间”通常在世界标准时间上午11点至下午5点之间。 在该时间范围内,大约有50%的问题被提出。 在这些时间里提出的问题更有可能更快地得到答案(大约5-10%),但答案的质量并不高。 发布问题的时间不会影响其他条件,例如投票,观看次数或答案数量。
措词科学 艺术
在标题中使用语言/主题的名称
我们使用的主要脚本之一是为了统计和分析标题而构建的。 我们根据编程术语(例如“字符串”,“数组”,“函数”),语言/主题(例如Ruby,MySQL,C#),否定/肯定词(例如“不能”,“最差”, “最佳”,“失败”)等等。 最明显的结论-如果您想获得更快更好的答案,请使用标题中要求的主题。 对Python方面的内容有疑问吗? 只需将Python添加到标题即可。
例如:在15分钟内回答的与Ruby有关的问题中,有36%的标题中包含“ Ruby”一词。 24小时后回答的问题中,只有15%的标题带有“ Ruby”一词。 观看次数最高的Java问题中有58%包含“ Java”一词。 39%的标准Java问题都包含“ Java”一词。
标题中使用两种语言呢? 例如,“为什么Java中的字符串比较(CompareTo)比C#中的更快?”。 似乎在标题中使用两种不同的语言/主题可能会减少答案的数量和质量,因为精通这两种语言的用户较少。 但是,这类问题的表现非常好,并且更有可能取得良好的结果。
标题是否是问题都没关系
这是一个使我感到惊讶的统计数据。 将标题作为问题短语不会影响答案的速度或质量。
例如–“将相同的方法添加到多个类”与“如何将相同的方法添加到多个类?” 将获得相同的结果。 我们在研究中注意到的唯一区别是,标题为问题的短语更有可能获得更快的答案(大约10%)。
有什么不适合您的吗? 你不能解决问题吗? 社区在这里为您提供帮助
标题表明出现问题或正在询问错误,通常会得到更好,更快的响应。
例如:
Rspec存根不起作用
为什么捆绑程序无法访问http://rubygems.org?
无法在Python中导入我自己的模块
似乎使用表示失败的词(“无法”,“无法”,“失败”,“错误”,“无法正常工作”等)可以带来更好的答案。 例如,最常见的Ruby问题中有22%的标题中包含否定短语,而标准问题的平均水平为14%。
但是,似乎表明某事不起作用或询问错误并不能吸引具有较高声誉的用户。 这些问题获得了更快的结果,更多的答案和更高的观看次数,但得到信誉低于平均水平的用户的回答。
我应该使用X还是Y?
比较不同的技术或方法是获得高质量答案的好方法。 这种类型的问题在我们形成的每个“最重要的问题”列表中都起着重要的作用。
这里有一些例子:
如果PyPy快6.3倍,为什么我不应该在CPython上使用PyPy?
为什么密码比字符串更喜欢char []?
为什么Java中的字符串比较(CompareTo)比C#中的更快?
让我们变得有趣
这很明显,但是许多排名靠前的问题都指出了神秘的行为或出乎意料的结果。
以下是一些热门问题的示例:
为什么处理排序数组要比未排序数组快? (6960票)
为什么将0.1f更改为0会使性能降低10倍? (774票)
为什么parseInt(1/0,19)返回18? (632票)
我们如何进行测试?
我们决定专注于面向语言的问题,以避免一般性问题(例如“我如何成为一名更好的程序员”或“使用哪个工作面试问题”)或与幽默相关的问题,这些问题通常会获得很高的分数,但不会并不代表开发人员面临的典型问题。 我们专注于6种编程语言-Java,Ruby,Python,C ++,Javascript和C#。 我们分析的前三种语言是Java,Ruby和Python,这三种语言的结果非常相似,因此我们决定暂时不分析其他三种语言。
我们决定只关注自2011年以来提出的问题。
我们运行了八个不同的查询,并根据以下问题对问题进行了排序:投票,答案数,收藏夹数,直到第一个答案的时间,问题的发布时间,信誉较高的用户回答的问题,信誉较高的用户提出的问题声誉,查看次数。 然后,我们将每个部分中前300个问题与300个问题进行了比较,这些问题在我们关注的参数上获得了平均分数。 这显然不是一门精确的科学,也没有一个“科学配方”来获得很好的答案。 但是,上面提到的所有模式都在我们质疑的不同参数和不同语言之间重复了自己。
这是我们使用的一些查询:玩得开心,如果发现其他有趣的结果,请告诉我们。
感谢CodersClan的 Dror Cohen的帮助,并感谢John Woo证明了他120k + SO信誉点的合理性,并帮助我们编写了查询。
样本查询
- 具有较高声誉和Python标签的用户提出的问题
;WITH recordsList AS ( SELECT 'http://stackoverflow.com/users/' + CAST(p.OwnerUserId AS VARCHAR(10)) AS OwnerLink, 'http://stackoverflow.com/questions/' + CAST(p.ID AS VARCHAR(10)) AS QuestionLink, p.Score, p.ViewCount, p.FavoriteCount, p.Title, LEN(p.Title) AS TitleLength, LEN(p.Body) AS BodyLength, p.Tags, p.CreationDate, u.Reputation, ROW_NUMBER() OVER (PARTITION BY p.OwnerUserId ORDER BY p.Score DESC) UserAnswerSequence, CASE WHEN CHARINDEX('<code>', p.Body) > 0 THEN 'True' ELSE 'False' END ContainsCodeBlock FROM Posts AS p INNER JOIN Users As u ON p.OwnerUserId = u.Id INNER JOIN PostTags AS pt ON pt.PostId = p.Id WHERE p.PostTypeId = 1 -- <<== Questions AND p.CommunityOwnedDate IS NULL -- <<== not WIKI AND pt.TagId = 16 -- <<== PYTHON ) SELECT TOP 5000 OwnerLink, QuestionLink, Score, ViewCount, FavoriteCount, Title, TitleLength, BodyLength, Tags, CreationDate, ContainsCodeBlock FROM recordsList WHERE UserAnswerSequence <= 50 ORDER BY Reputation DESC, Score DESC - 具有较高声誉和Java标签的用户的答案
;WITH recordsList AS ( SELECT 'http://stackoverflow.com/users/' + CAST(p.OwnerUserId AS VARCHAR(10)) AS OwnerLink, 'http://stackoverflow.com/questions/' + CAST(p.ID AS VARCHAR(10)) AS QuestionLink, p.Score, p.ViewCount, p.FavoriteCount, p.Title, LEN(p.Title) AS TitleLength, LEN(p.Body) AS BodyLength, p.Tags, p.CreationDate, u.Reputation, ROW_NUMBER() OVER (PARTITION BY pa.OwnerUserId ORDER BY pa.Score DESC, p.Score DESC) UserAnswerSequence, CASE WHEN pa.CommunityOwnedDate IS NOT NULL THEN 'TRUE' ELSE 'FALSE' END IsAnswerWiki FROM Posts AS p INNER JOIN Posts As pa ON pa.PostTypeId = 2 -- <<== Answer AND p.Id = pa.ParentID AND p.OwnerUserId <> pa.OwnerUserId -- <<== not come on the same poster AND p.AcceptedAnswerId = pa.Id INNER JOIN Users As u ON pa.OwnerUserId = u.Id INNER JOIN PostTags AS pt ON pt.PostId = p.Id WHERE p.PostTypeId = 1 -- <<== Questions AND p.CommunityOwnedDate IS NULL -- <<== not WIKI AND pt.TagId = 17 -- <<== JAVA AND p.OwnerUserId IS NOT NULL -- <<== user is not deleted AND pa.OwnerUserId IS NOT NULL -- <<== user is not deleted ) SELECT TOP 5000 OwnerLink, QuestionLink, Score, ViewCount, FavoriteCount, Title, TitleLength, BodyLength, Tags, CreationDate, IsAnswerWiki FROM recordsList WHERE UserAnswerSequence <= 50 ORDER BY Reputation DESC, Score DESC - 按问题发布的小时数对其进行分组(0-23),并显示回答问题所需的时间。
;WITH hourgenerator -- <<== generates 0-23 (24Hour) AS ( SELECT 0 AS hourPosted UNION ALL SELECT hourPosted + 1 FROM hourgenerator WHERE hourPosted < 23 ), questionsPerHour AS ( SELECT CAST(p.CreationDate as DATE) AS [Date], DATEPART(Hour, p.CreationDate) AS hourPosted, COUNT(*) NumberOfQuestions, AVG(DATEDIFF(second, p.CreationDate, pa.CreationDate)) AvgTimeAnswered FROM Posts AS p INNER JOIN Posts As pa ON pa.PostTypeId = 2 -- <<== Answer AND p.Id = pa.ParentID AND p.OwnerUserId <> pa.OwnerUserId -- <<== not come on the same poster AND p.AcceptedAnswerId = pa.Id WHERE p.PostTypeId = 1 -- <<== Questions AND p.CommunityOwnedDate IS NULL -- <<== not WIKI AND DATEDIFF(second, p.CreationDate, pa.CreationDate) >= 0 AND p.OwnerUserId IS NOT NULL -- <<== user is not deleted AND pa.OwnerUserId IS NOT NULL -- <<== user is not deleted AND p.CreationDate >= CAST('2013-11-14' AS DATE) AND p.CreationDate < DATEADD (dd, 1 ,CAST('2013-11-14' AS DATE)) GROUP By CAST(p.CreationDate as DATE), DATEPART(Hour, p.CreationDate) ) SELECT COALESCE(qph.[Date], CAST('2013-11-14' AS DATE)) AS [Date], hg.hourPosted, COALESCE(qph.NumberOfQuestions, 0) AS NumberOfQuestions, COALESCE(qph.AvgTimeAnswered, 0) AS AvgTimeAnswered FROM hourgenerator AS hg LEFT JOIN questionsPerHour AS qph ON hg.hourPosted = qph.hourPosted ORDER BY hg.hourPosted
分析堆栈溢出原因















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









