







单链表、循环链表和双向链表的比较
| 查找表头结点(首元结点) | 查找表尾结点 | 查找p的前驱结点 | |
|---|---|---|---|
| 带头结点的单链表L | L->next时间复杂度 O ( 1 ) O(1) O(1) | 从L->next依次向后遍历时间复杂度 O ( n ) O(n) O(n) | 通过p->next无法找到其前驱 |
| 带头结点的单循环链表(仅设头指针L) | L->next时间复杂度 O ( 1 ) O(1) O(1) | 从L->next依次向后遍历时间复杂度 O ( n ) O(n) O(n) | 通过p->next可以找到其前驱时间复杂度 O ( n ) O(n) O(n) |
| 带头结点的单循环链表(仅设尾指针R) | R->next时间复杂度 O ( 1 ) O(1) O(1) | R 时间复杂度 O ( n ) O(n) O(n) | 通过p->next可以找到其前驱时间复杂度 O ( n ) O(n) O(n) |
| 带头结点的双向循环链表L | L->next时间复杂度 O ( 1 ) O(1) O(1) | L->prior时间复杂度 O ( 1 ) O(1) O(1) | p->prior时间复杂度 O ( 1 ) O(1) O(1) |
顺序表和链表的比较
- 链式存储结构的优点:
- 结点空间可以动态申请和释放;
- 数据元素的逻辑次序靠结点的指针域来指示,插入和删除时不需要移动数据元素。
- 链式存储结构的缺点:
- 存储密度小,每个结点的指针域需要额外的占用存储空间。当每个结点的数据域所占的字节不多时,指针域所占存储空间的比重显得很大。(空间利用率低) 。
- 链式存储结构是非随机存储结构。对任一结点的操作都要从头指针依指针链查找到该结点,增加了算法的复杂度
存储密度: 指结点数据本身所占的存储量和整个结点结构中所占存储量之比,即,
存
储
密
度
=
结
点
数
据
占
用
存
储
空
间
结
点
占
用
的
总
空
间
存储密度= \frac {结点数据占用存储空间}{结点占用的总空间}
存储密度=结点占用的总空间结点数据占用存储空间
在单链表中,如果数据域占8个字节,指针域(里面放的是下一个结点的地址)占4个字节,如下图,
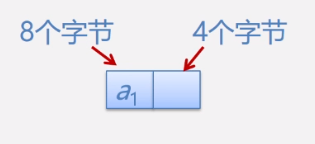
则其存储密度为,
8
12
=
67
\frac{8}{12}=67
128=67%。
| 顺序表 | 链表 | ||
| 空间 | 存储空间 | 预先分配,会导致空间闲置或溢出现象 | 动态分配,不会出现空间闲置或溢出现象 |
| 存储密度 | 不用为表示结点的逻辑关系而增加额外的存储开销,存储密度为1 | 需要借助指针来体现元素间的逻辑关系,存储密度小于1 | |
| 时间 | 存取元素 | 随机存取,按位置访问元素。时间复杂度为O(1)。 | 顺序存取,按位置访问元素。时间复杂度为O(n)。 |
| 插入、删除 | 平均移动约表中一半元素,时间复杂度为O(n) | 不需要移动元素,确定插入、删除位置后,时间复杂度为O(1) | |
| 适用情况 | 1.表长变化不大,且能事先确定变化的范围。 2.很少进行插入或删除操作,经常按元素位置序号访问数据元素 | 1.长度变化大。 2.频繁进行插入或删除操作 | |















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









