







Java 这门语言与生俱来的显著特性就是“一次编译,到处运行”,这种功能得益于 JVM 平台的支持,Java 程序通常通过将其打包为 JAR 或 WAR 包,并依赖 JVM 和 Servlet 容器来运行。其底层运行时 JVM 采用 JIT(即时编译)模式来执行程序代码,JVM 会在运行时进行编译优化和动态执行代码,这通常会导致较高的内存占用。这样的好处是采用 JIT 可以热更新和热部署程序,并且 JVM 可以在运行期间对程序进行动态分析,来实时优化程序以达到最好的性能状态。
Cloud Native 面临的问题
随着云计算的发展,服务端程序的运行和部署方式发生了巨大变化,特别是在云原生(Cloud Native)场景下,服务器程序被打包成一个个容器运行。在这种环境下,传统方式容器化的 Java 程序面临着打包后的镜像文件过大的问题。镜像文件中需要包含 JRE 和各种第三方库,导致镜像体积庞大,占用更多的磁盘空间。
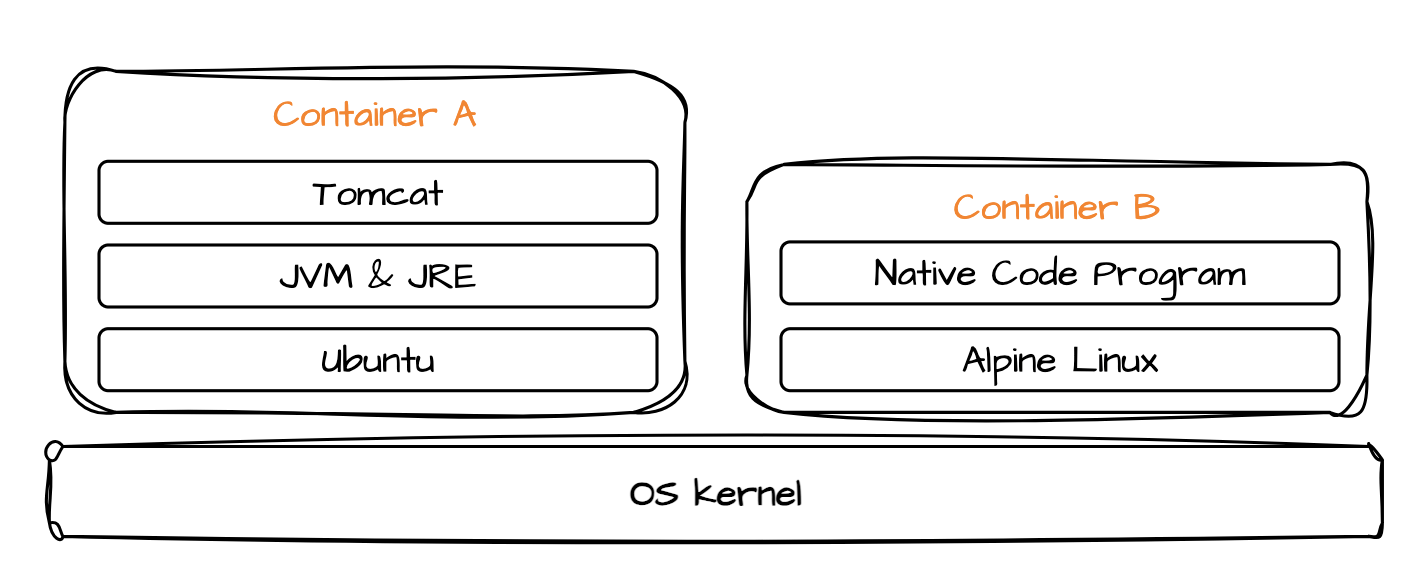
目前云计算的计费方式也发生了改变,采用按需分配的实时计费方式,根据程序的内存占用和运行时间计费。这与传统 IDC 自托管式机房中长时间运行服务器程序形成鲜明对比,按需分配的计费方式显然更具性价比,因此优化 Java 程序在容器环境中的运行方式变得尤为重要。
Serverless 面临的问题
传统的 JVM 工作原理要求程序员先将编写的 Java 程序打包为 JAR 或 WAR 包,这是普通 Java 开发者所能接触到的程序编译和构建阶段。然而当程序运行起来之后,底层的 JVM 会进行许多复杂的操作,包括内存管理、垃圾回收、即时编译等。需要先启动 JRE 中的 JVM 来加载 Tomcat 服务器所需的字节码,再加载 WAR 包中的字节码文件到 Servlet 容器中运行服务,这个过程非常耗时。
下图为整个传统 Java 程序从源代码到程序运行各个阶段的工作流程:
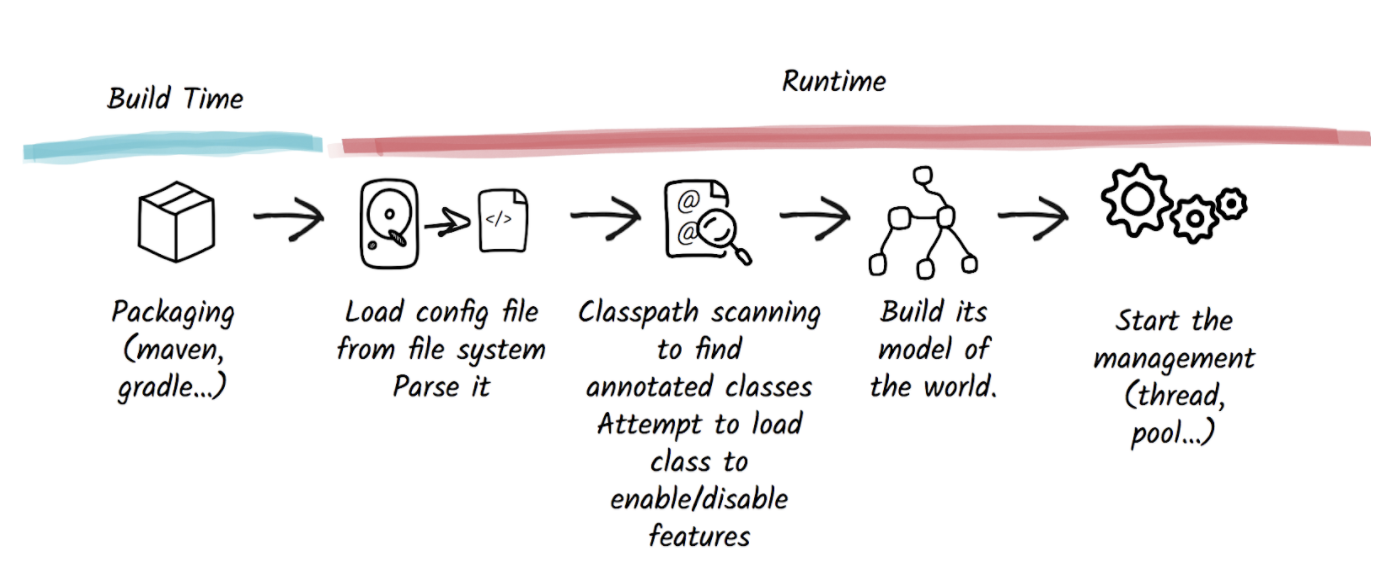
下图为传统的 Java 运行时执行程序的生命周期,首先应用的开发者将 *.java 源代码编译为 bytecode 和 jar 依赖包通过 maven 构建打包为一个单独的 jar 包。当执行 java -jar xxx.jar 命令时,首先要启动 JRE 中的 JVM 程序,因为 JVM 本身也是一款单独程序对应着 $JAVA_HOME\bin 目录中的 java ,当 JVM 启动之后会在系统中创建一个进程,将要运行的 jar 程序包和 JRE 标准库中 class 文件加载入 JVM 内存中,并且找到 main 方法开始解释执行。当程序运行一段时间之后 JVM 充分获取了 Java 程序的一些执行数据信息,开始对程序进行 JIT 及时编译优化程序,当程序被 JIT 优化之后的程序才能达到和 C/C++ 这种直接编译为 Native Code 程序的性能。
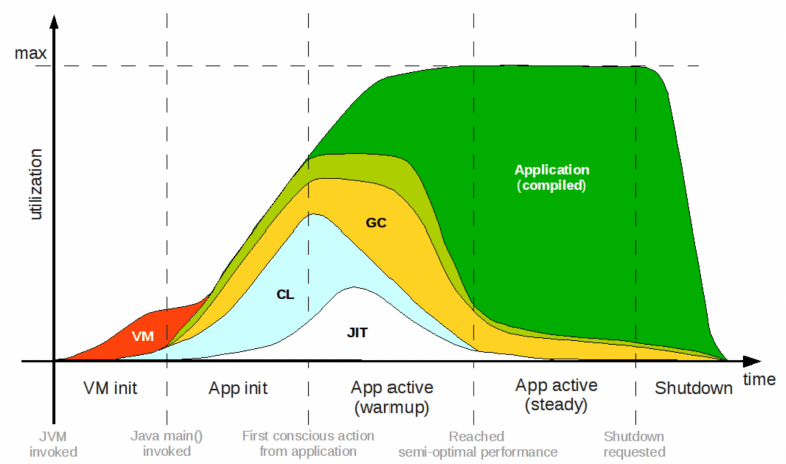
在云计算推崇的 Serverless 架构场景下,Java 的 JIT 模式并不适合,Serverless 应用程序需要能够快速启动以响应事件驱动的请求,并且在空闲时自动关机销毁,释放在服务请求期间所使用的内存。然而,这种需求与传统的 Java 程序运行模式背道而驰,使得 Java 在 Serverless 场景中显得不适用,这就是被业界称为的 冷启动 问题。
为了解决这一痛点,Oracle Labs 推出一款新的 JDK 产品 GraalVM JDK ,相比传统的 JDK 该产品内置 Java 静态编译工具和一款新的虚拟机,和传统的 JVM 不一样 GraalVM 是支持多语言进行混合编程的虚拟机,这也是它一大亮点。GraalVM 中的静态编译工具不仅是支持将 Java 编译为二进制可执行文件,还支持 JavaScript 和 Python 等其他语言的编译优化功能,本文只关注于 GraalVM 对 Java 程序进行 AOT(Ahead-Of-Time)编译的解决方案。
使用 GraalVM 对 Java 程序进行 AOT 编译的解决方案,可以显著缩短启动时间并降低内存占用,使 Java 程序更适合在 Serverless 环境中运行,通过 AOT 编译,编译器生成一个 Native Code 二进制文件,即对应平台架构的机器代码程序。这种方式无需像 JIT 那样依赖于 JVM 运行,在内存和磁盘占用上有显著改善。下图为 AOT 编译工作流程,在编译阶段会程序进行静态分析,通过它内置工具分析 Java 源代码中依赖关系,将其所有依赖和代码执行逻辑都进行提前编译为机器代码,缺点也很明显可能会失去在 JIT 模式下的动态反射功能。
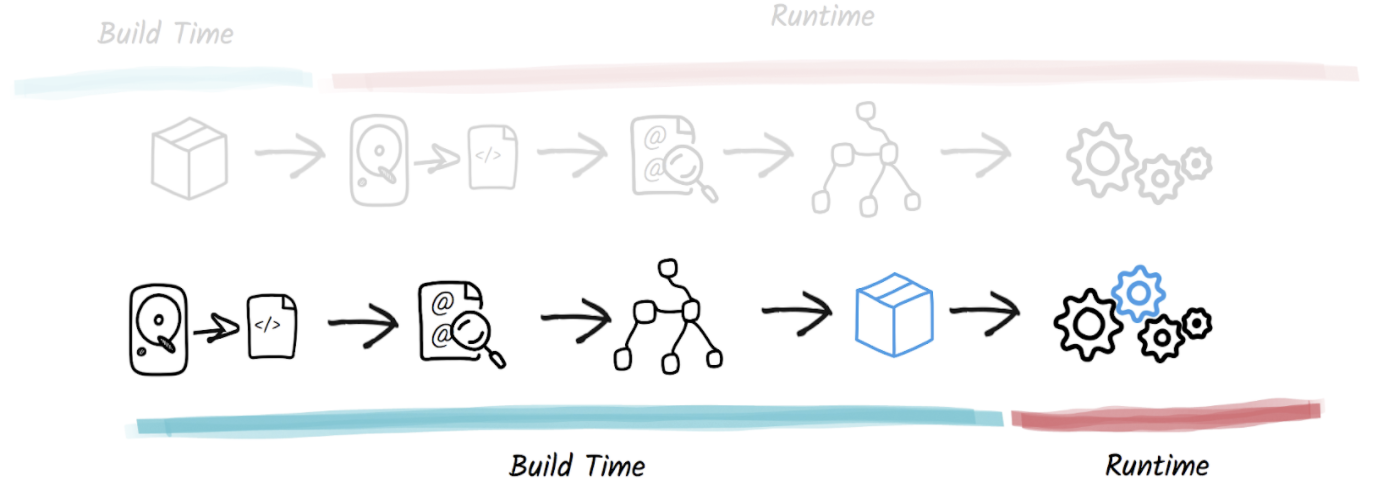
如上图,在 AOT 模式下将在运行时的过程放到在程序构建阶段,构建阶段会对 Java 程序执行静态代码分析和依赖可达性分析,将其所有的依赖软件包都编译生产所属平台对应的可执行二进制文件。
AOT 编译优化
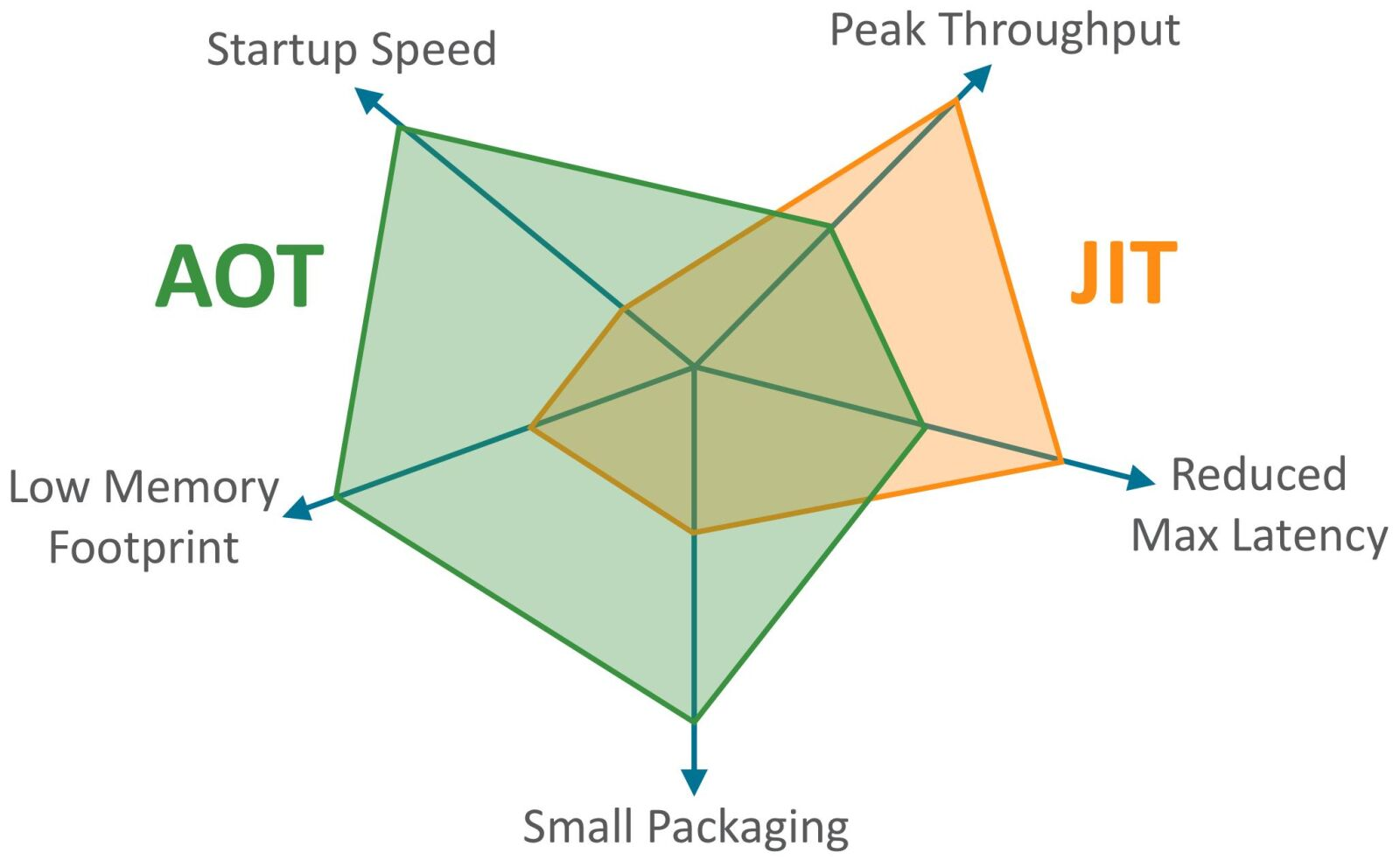
对程序进行 AOT 编译特别适合云应用程序,被 AOT 编译优化之后的程序启动速度足够快,从而缩短启动时间并更直接地水平扩展云服务,内存占用相比 JVM 模式下要少很多,这对于在云中运行的容器初始化的微服务尤其有益。AOT 前提是完全封闭的运行空间,因为它消除了各种代码注入的可能性,例如 2021 年震惊网络的 Log4j 漏洞就是由于利用了 Java 中的动态类加载机制而发生的,在 AOT 编译之后程序就不会发生类似于漏洞。
下面这张蜘蛛图详细展示了不同程序运行方式的区别:
介于 Java 程序部署平台和主流的容器技术都是基于 Linux 系统,所以这里以 Ubuntu 发行版本作为基础 AOT 编译和运行打包环境。要对 Java 程序进行 AOT 编译的话首先要安装 GraalVM JDK 的发行版本,这个可以去它的官方网站 graalvm.org 上下载和安装,安装步骤和传统基于 OpenJDK 的发行版本步骤一致。
在 Linux 中要是使用 GraalVM 提供的 AOT 静态编译功能,首先需要在操作系统中安装一些 C/C++ 编译器的工具链,在 Ubuntu 和其他基于 Debian 的系统中执行下面命令:
sudo apt-get install build-essential libz-dev zlib1g-dev
其中的 build-essential 是一个用于 C 语言的开发包,包含了 gcc make gdb 和 libc 函数库等很多工具,这些工具和库对于编译 C 和 C++ 程序是必不可少的。libz-dev 和 zlib1g-dev 是用于压缩和解压缩的开发库,这两个软件包提供了开发 zlib 库的头文件和开发工具,允许您在编写 C/C++ 程序时链接和使用 zlib 压缩库,GraalVM 的 AOT 编译依赖于这些工具来构建本地映像。
默认情况下,GraalVM 的 AOT 编译在链接时通常使用系统的标准 glibc 库,但在小型嵌入式设备或对内存要求极低的环境中,glibc 并未针对这些场景做出特别优化。相比之下目前有另外一种专有的 musl 标准库实现,musl 被开发出来就是专注在内存受限的设备上表现优异,使用 musl 生产的二进制文件通常比使用 glibc 生产的文件体积更小,所以更推荐直接使用 musl 替代 glibc 去做编译链接优化。
在 GraalVM 的 AOT 编译工具中提供自定义选项,允许开发者去自定义使用 musl 去做生成二进制文件优化。部分 Linux 发行版本系统可能没有内置 musl 库需要提前安装,通过源代码安装的方式可以去 musl.libc.org 官方网站下载源代码包编译安装。但这种方式的需要自己手动配置和编译步骤比较繁琐,建议使用下面这种方式,通过别人已经编译好的 x64 位的 x86_64-linux-musl-native 程序,下载压缩包到指定位置就可以使用。
基于 musl 编译的前置条件是依赖于 musl 工具链,但在 GraalVM JDK 中并未提供相关的工具链的支持,需要提前下载 x86_64-linux-musl-native 和 zlib 文件,创建一个用于存放 musl 工具链的目录,将其解压到这个目录中,并且将 x86_64-linux-musl-gcc 和 zlib 进行整合编译安装,步骤如下:
# 创建一个工具存储目录
mkdir /usr/local/graal-aot-tools
# 进入到这个目录
cd /usr/local/graal-aot-tools
# 下载 x86_64-linux-musl 工具链
wget http://more.musl.cc/10/x86_64-linux-musl/x86_64-linux-musl-native.tgz
# 解压下载到的 musl 工具链包
tar -zxvf x86_64-linux-musl-native.tgz
# 复制文件到工作根目录
cp -r x86_64-linux-musl-native/* .
# 下载 zlib 依赖
wget https://zlib.net/current/zlib.tar.gz
# 解压 zlib 依赖源码包
tar -zxvf zlib.tar.gz
通过一条特定 TOOLCHAIN_DIR 环境变量来指定 musl 工具链安装路径,graalvm 的 aot 编译器会通过此变量来找到 x86_64-linux-musl 的位置:
export TOOLCHAIN_DIR="/usr/local/graal-aot-tools"
export PATH="$TOOLCHAIN_DIR/bin:$PATH"
export CC="$TOOLCHAIN_DIR/bin/gcc"
最后把 zlib 和 TOOLCHAIN_DIR 整合进行编译安装,进入 zlib 源代码安装目录中执行:
./configure --prefix=$TOOLCHAIN_DIR --static
make
make install
配置完成之后可以通过 x86_64-linux-musl-gcc 命令检查 musl 工具链是否安装成功。如果使用的是 maven 来构建自动化项目,可以使用 pom 文件中配置 AOT 相关构建参数,来自动化来构建二进制文件:
<!-- GraalVM Native Plugin -->
<plugin>
<groupId>org.graalvm.buildtools</groupId>
<artifactId>native-maven-plugin</artifactId>
<version>${native.maven.plugin.version}</version>
<extensions>true</extensions>
<executions>
<execution>
<id>build-native</id>
<goals>
<goal>build</goal>
</goals>
<phase>package</phase>
</execution>
</executions>
<configuration>
<!-- 全局配置 -->
<skip>false</skip>
<imageName>${bin.file.name}</imageName>
<mainClass>${app.main.class}</mainClass>
<buildArgs>
<!-- 全局的构建参数 -->
<buildArg>--gc=G1</buildArg>
<!-- 依赖全部静态链接打包到二进制文件中 -->
<buildArg>--static</buildArg>
<buildArg>--libc=musl</buildArg>
<!-- 禁止回退优化代码生成,最小的二进制兼容文件 -->
<buildArg>--no-fallback</buildArg>
<!-- 支持的最低CPU架构 -->
<buildArg>-march=compatibility</buildArg>
</buildArgs>
</configuration>
</plugin>
在项目的根目录中执行 mvn native:build 命令就可以调用位于 $JAVA_HOME/bin/native-image 工具执行静态分析并且生成二进制可执行文件。AOT 编译对计算机硬件资源的要求非常高,取决于项目的大小,大型项目编译时需要占用很多 GB 的内存和大量的 CPU 使用率,不过这会使用高性能的 CI/CD 服务器来完成自动化构建工作。
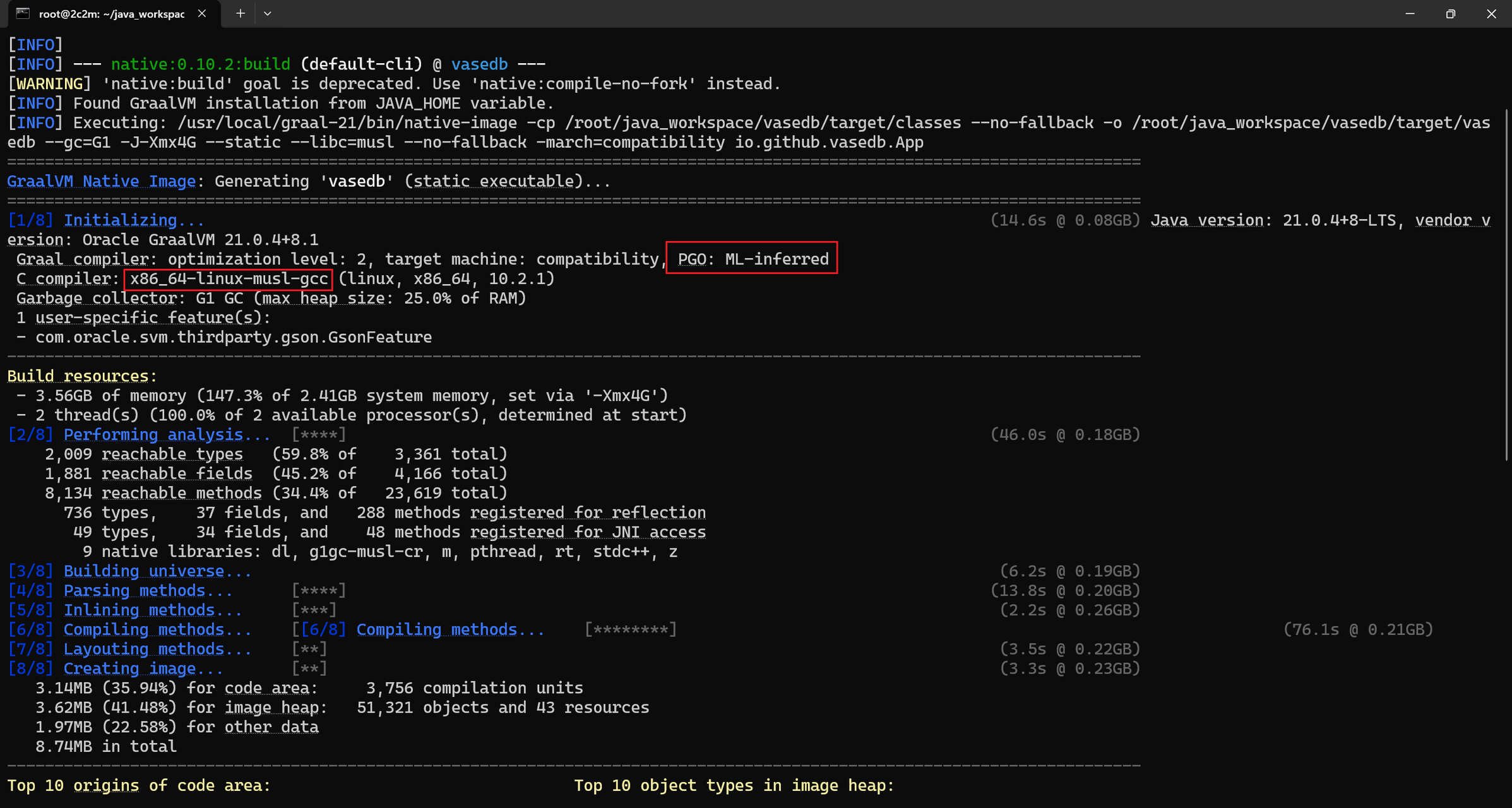
通过 x86_64-linux-musl-gcc 和 musl 做链接编译生成的二进制可执行文件,完全使用的是静态链接的方式,从而提高了可移植性。在不同的 x86_64 的 Linux 系统上运行这些静态链接的二进制文件时,不需要任何额外的库,这对于部署和分发二进制文件非常有用。
从编译日志输出可以看到,AOT 编译器启用了 PGO: ML-inferred 优化,这个默认在其他平台是不会启动的,只要在 Linux 平台下使用 x86_64-linux-musl-gcc 才会开启的,

由于使用的完全静态链接的二进制文件,所以可以使用 upx 针对这个二进制文件进行压缩,压缩之后的二进制文件可以小到 3 MB 大小。
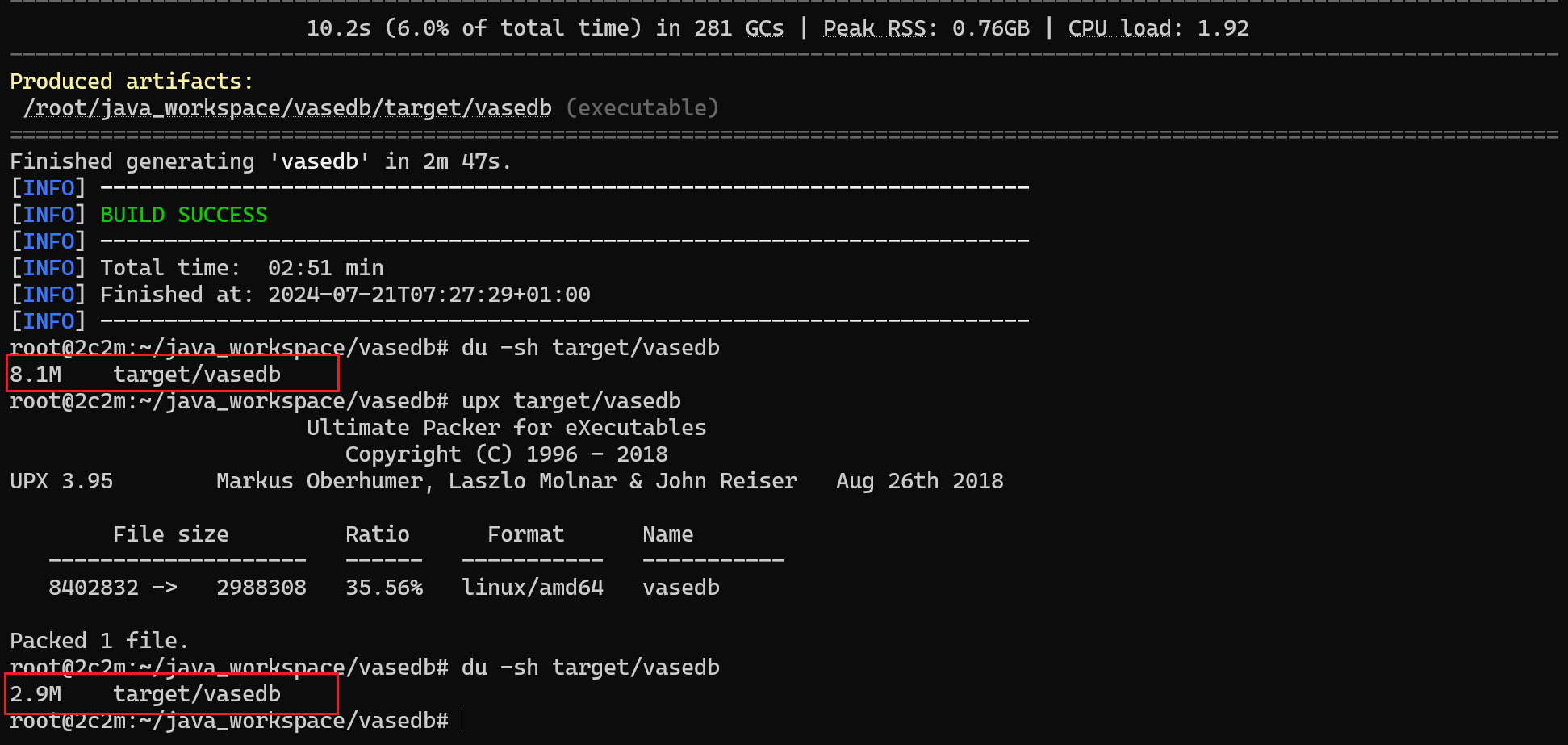
这对于将其打包为 docker 容器镜像文件非常有利,意味着不需要任何其他基础镜像,直接打包可执行二进制文件放到容器中执行,基于 scratch 基础镜像打包之后镜像大小和二进制文件大小一致。
# 使用一个轻量的基础镜像
FROM scratch
# 复制静态链接的二进制文件到根目录
COPY target/vasedb /
# 设定工作目录,这是可选的
WORKDIR /
# 默认的启动命令
CMD ["/vasedb"]
采用 AOT 和 JIT 模式通过这些数据,形成鲜明的对比,优势也展示出来了,以往采用 JIT 模式运行的 Java 被容器化之后镜像大小往往都是上百 MB 大小的。

个人认为有 Serverless 更激进优化方案,在 AOT 编译之后程序会内嵌入一个微型的 SubstrateVM 运行时,这个运行时负责 Java 程序在运行阶段一些多线程和内存分配、垃圾回收功能,默认 AOT 编译使用的 serial 垃圾回收器是一种单线程垃圾回收器,适用于单线程应用或有少量线程的应用,另外一个可选的垃圾回收器是 G1 垃圾回收器,G1 用于多核处理器和大内存机器的高性能垃圾回收器。
但是在 Serverless 应用场景中往往应用程序运行时间很短,在程序在运行一段时间之后就主动销毁了,这有点类似于在 AOT 编译阶段的编译程序本身步骤,当编译器编译完程序就销毁了,是一种一次性应用程序。熟悉 JVM 多个垃圾回收器实现应该知道其中有一个叫 Epsilon 垃圾回收器,该垃圾回收器不会执行任何垃圾回收操作,它只进行内存分配而不释放内存。
所以我个人认为在某些特定的 Serverless 应用场景中完全可以使用 Epsilon 内存分配器的方案,因为部分场景程序运行时长还没有等到 GC 回收器触发的时间点就被底层基础设施销毁了,程序运行所分配的内存会被 OS 主动回收,而不需要执行垃圾回收器进行回收,去掉 SubstrateVM 中的垃圾回收器部分,打包应用程序体积会更小。















 1610
1610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









