







问题描述
将dataframe存入excel里直接df.to_excel,但当excel已存在时,需要把dataframe存入一个新的sheet页里要怎么做,我在网上搜到的方法是这样的:
import pandas as pd
from openpyxl import load_workbook
writer = pd.ExcelWriter('test.xlsx', mode='a', engine='openpyxl')
book = load_workbook('test.xlsx')
writer.book = book
data.to_excel(writer, sheet_name='sheet2')
writer.save()
当sheet2不存在时,这样是可行的,但是当sheet2本身是存在的,就会重新生成一个sheet21,这就有问题了,没有更新进去,而这里pd.ExcelWriter()方法中,mode参数可选为"w"和"a",选"w"会覆盖掉原来excel的所有内容,不可取,所以在参数这里只能选"a"
那就找一个笨办法,我们把原来的sheet读出来放到一个dataframe里,然后删除原"sheet2",重新新建一个"sheet2",于是:
import pandas as pd
from openpyxl import load_workbook
writer = pd.ExcelWriter('test.xlsx', mode='a', engine='openpyxl')
book = load_workbook('test.xlsx')
book.remove_sheet(book.get_sheet_by_name('sheet2'))
writer.book = book
data.to_excel(writer, sheet_name='sheet2')
writer.save()
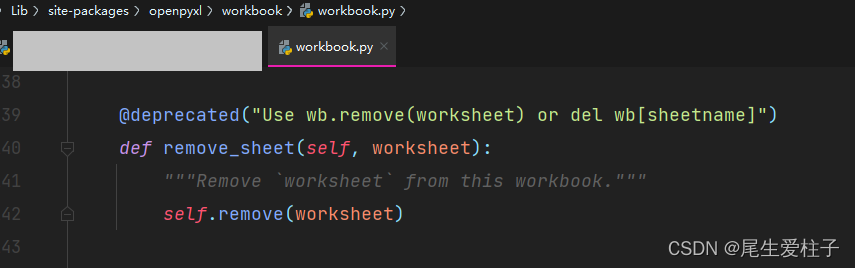
结果出现了警告:
DeprecationWarning: Call to deprecated function get_sheet_by_name (Use wb[sheetname]). book.remove_sheet(book.get_sheet_by_name(‘sheet2’))
这个警告的意思是,引用了已弃用的函数,我们可以看到原函数的标注,book.remove_sheet已弃用,直接用book.remove()即可
import pandas as pd
from openpyxl import load_workbook
writer = pd.ExcelWriter('test.xlsx', mode='a', engine='openpyxl')
book = load_workbook('test.xlsx')
if 'sheet2' in book.sheetnames: # get_sheet_names()方法也已弃用
book.remove(book['sheet2'])
writer.book = book
data.to_excel(writer, sheet_name='sheet2')
writer.save()
运行之后就可以得出增加后的excel文件
打包exe
由于需求是完成程序后打包成可执行文件,在用pyinstaller打包时出了错,报错信息是:
‘sheet2’ not in list.
意思就是没有完成删除工作簿操作,于是换了一种写法:
with pd.ExcelWriter('test.xlsx', mode='a', if_sheet_exists='replace') as writer: # doctest: +SKIP
data.to_excel(writer, sheet_name='sheet2')
writer.save()
writer.close()
测试后发现可行,按通用程度来说,还是后者。















 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









