







数据简介
本案例用到的原始数据是一个简单的数据集,其中包括从国外某网站捞取的每日新闻排序(25条),然后以当日的股票市场涨跌作为Label。从而根据对新闻的挖掘,来判断当日股票涨跌。
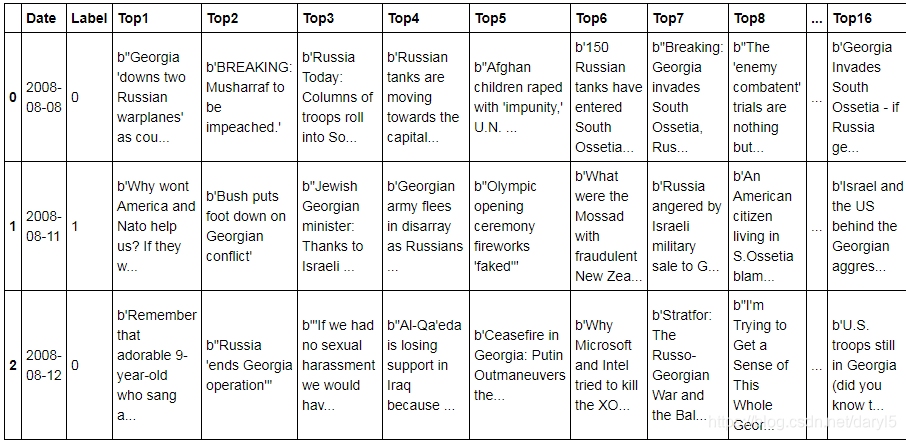
数据集大致长这样(部分截图):
Date:日期数据,本案例文本分析就不用这个数据了。
Label:当日股票市场情况,1代表上涨,0代表下跌。
Top*:共25列,表示当日的相关新闻。
下面利用TF-IDF简单的跑一下文本挖掘的基本流程,代码也都比较简单,重点是关注处理流程。
导入数据:
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import pandas as pd
import numpy as np
from sklearn.svm import SVC
from sklearn.metrics import roc_auc_score
from datetime import date
#读入数据
data=pd.read_csv(r'E:\python\news stock\input\Combined_News_DJIA.csv')
#观察数据
data.head()
数据预处理:
#接下来我们把headlines先合并起来。因为我们需要考虑所有的news的。
data['combined_news']=data.filter(regex=('Top.*')).apply(lambda x:''.join(str(x.values)),axis=1)
#分割测试/训练集,保留部分数据测试用
train 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









