






AI 原生数据库 Infinity 自 2023 年 12 月 21 日正式开源后,又经历了 4 个月的迭代开发,于 4 月 30 日发布了第一个release v0.1.0,更新如下:
- 完整的列存引擎,支持数据实时插入和删除,更加强大的元数据和日志回放管理,提供更多的数据类型支持,以及 Zonemap,Bloomfilter 索引用于提供基于列存的快速过滤。
- 全新的全文搜索实现,使得 Infinity 可以支持 RAG 场景所必须的多路召回:同时提供精确查询和语义查询。
- 完整的次级索引功能,主要针对各种数值类型字段提供高性能的点查询和范围过滤功能。
- 全新的索引维护框架,目前 Infinity 的主要索引都支持并行构建和增量构建,包括向量索引,全文索引,次级索引在内的所有索引都支持异步和实时构建。
- 更多的结构化查询算子和更丰富的 API。在原生 Python API之外, Infinity 进一步提供了 HTTP API ,方便采用任何开发语言的客户端访问。
Infinity v0.1.0 初步实现了“AI 原生数据库”理念的数据库版本,可以提供如下3类查询之间的任意组合:
- 结构化数据查询
- 向量搜索
- 全文搜索
它源自于我们对 RAG 场景的全新定义,服务未来的 LLM 面向 B 端的标准架构范式:
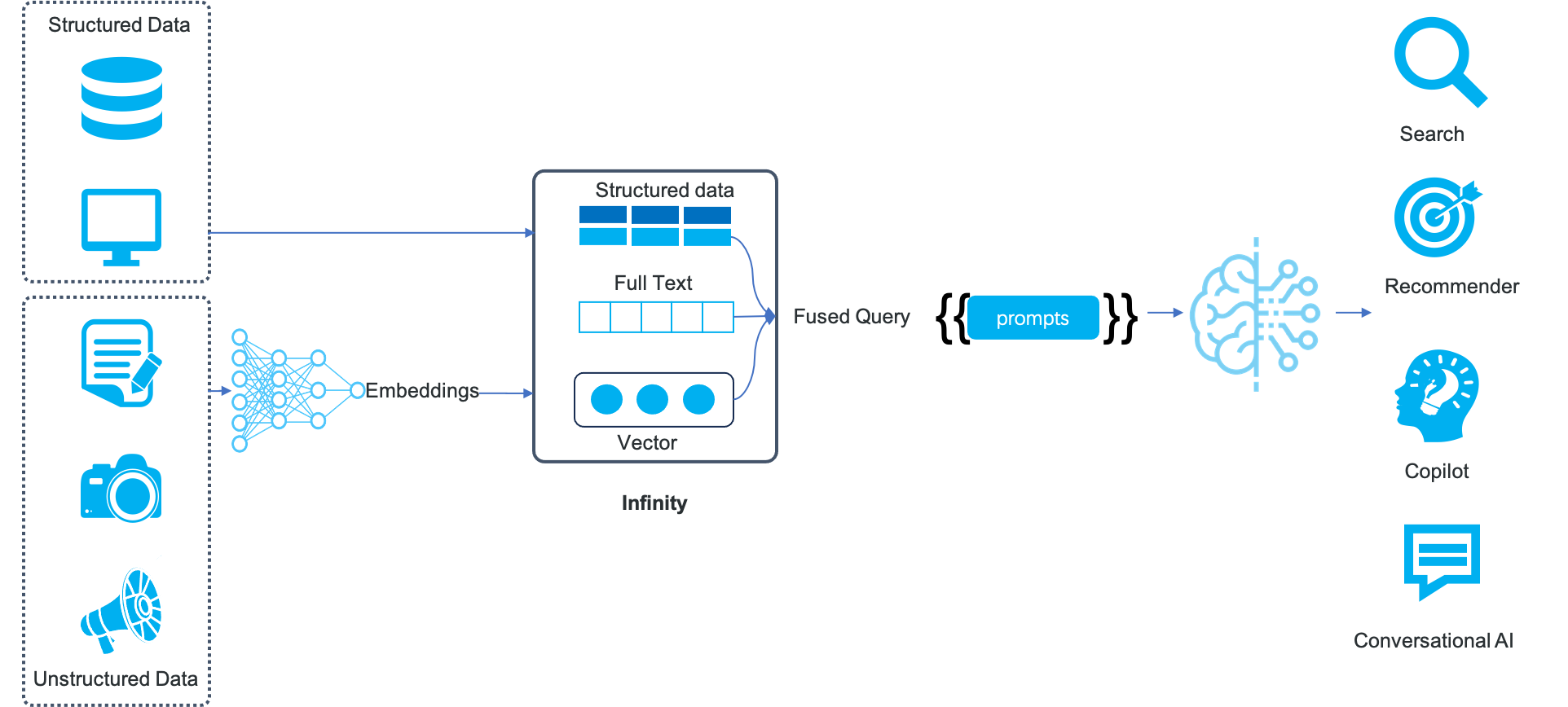
因此,Infinity 是一个完整的数据库实现,而非一个“向量数据库”。它提供了基于列存的完整数据库存储引擎,保证数据的 ACID ,并针对不同类型字段选择性建立相应的索引,具体来说:针对数值类字段建立次级索引;针对Embedding 类型字段建立向量索引;针对文本类型字段建立全文索引。
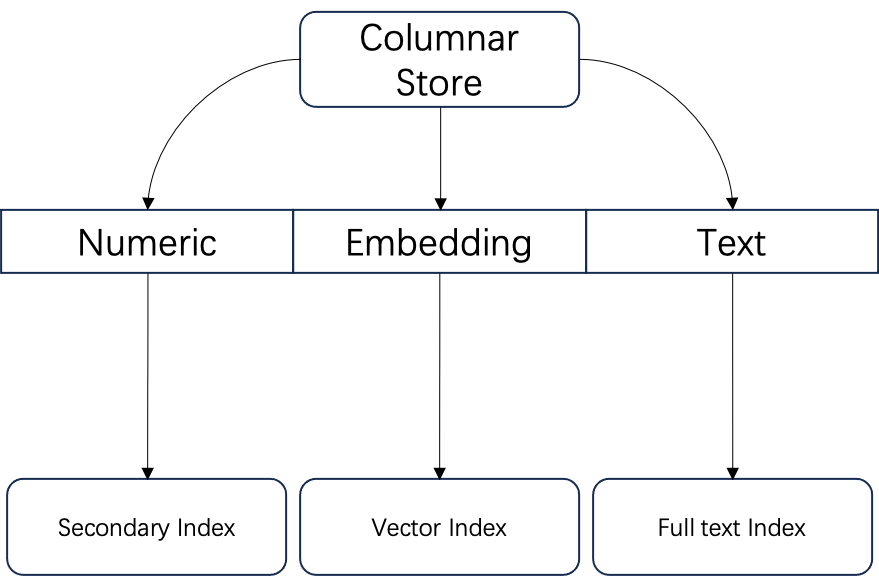
下边进一步来描述三类索引的设计细节:
次级索引主要提供针对数值列的高性能过滤。次级索引的设计在传统数据库中并非很容易做到,这是因为:OLTP 数据库的次级索引通常基于普通的 Key Value 存储,这可以提供较高性能的点过滤功能(就是说过滤的范围并不大),但是对于较大范围的过滤,通常很难实现足够高的性能,因为维护一个可遍历或者迭代的结构对于 Key Value 类存储引擎来说从来不是一个轻松的任务,尤其是当下 Key Value 存储基本统一为以 LSM Tree 为基础的数据结构,这让大范围过滤的性能下降更加明显。而另一方面, OLAP 数据库通常不提供次级索引 ,仅仅提供 ZoneMap 或者 BloomFilter 这样的辅助结构。这是因为 OLAP 数据库通常服务离线场景,追求高吞吐写入和查询,需要经常性的扫描大范围列数据给出过滤后聚合的结果,因此这种情况下维护次级索引是一个不必要的任务。Infinity 作为一款面向在线应用的数据库,它跟以上两类的 OLTP 和 OLAP 都不同,它面临的是在写少读多场景下,既能提供高并发的点过滤,又能提供高并发的大范围过滤能力的在线场景。因此在实现上,Infinity 采用了一种全新的不同结构:首先把需要建立次级索引的列按照该列数值排序,并附带行号,作为新的一列数据保存,同时在内存中采用了一种称为 PGM 的索引结构。PGM,全称是 Piecewise Geometric Model 索引,它是一种 Learned Index,也可以看作是 AI4DB 的一个典型应用,它采用基于机器学习的数据结构,针对排序后的结果建立内存中摘要信息,它在内存中的数据极少,大约只有原始数据的 1/100 大小。在查询时,PGM 会提供高性能的范围过滤查询,不过它不能保证精确查询结果,只能给出一个大致的范围,因此还需要去原始的数据扫描才可以得到最精确的值。结合了 PGM 和排序数据结构的次级索引,不论在点过滤还是范围过滤上都可以提供高并发能力。

向量索引是 Infinity 的核心功能之一,因为向量搜索是 RAG 必备能力。在当前版本的 Infinity 中,提供了 2 类向量索引,一类是基于倒排索引结构的 IVF 实现,它的特点主要在于内存消耗少,但性能略低。另一类是基于 HNSW 的图索引,在具体实现上, Infinity 并没有采用已有的开源 HNSW 图索引实现,而是采用了进一步优化,具体来说,就是引入了量化技术,对每个需要建立索引的向量进行局部自适应量化,量化的上下界是动态计算的。并且引入了两级量化,其中第一级量化用于快速近似搜索,而第二级量化用于在需要时提高搜索精度。第二级量化处理第一级量化后的残差向量。除此之外,Infinity 采用了大量的 SIMD 指令用来加速计算,得益于这些设计,Infinity 的向量搜索性能相比同类产品性能超出许多。
全文索引是一个相对成熟的结构,同类产品如 Lucene(Elasticsearch), Tantivy 等均提供了完整且高性能的全文索引实现。Infinity 没有采用这些已有的实现,主要原因还是希望能让全文索引更好的被整合到数据库中,这主要体现在如下几点:
- 全文索引一般包含倒排索引和前向索引,这使得采用全文索引的数据库,都必须以全文索引库为核心基础来构建数据库,例如 Elasticsearch, 它的数据插入,实质上是完全写入到 Lucene 索引当中。而前向索引的能力,跟数据库的部分功能是重叠的,因此简单地整合,必然导致数据冗余。这也是基于 Lucene 的 Elasticsearch 并不能很方便提供普通结构化数据查询能力的原因之一。
- 提供全文搜索的主要目的是提供向量之外的 RAG 所必备的精确召回能力,它需要跟向量搜索共同完成融合排序,因此需要在统一的数据库存储引擎和执行引擎框架之下提供可方便定制搜索逻辑和排序功能的全文索引框架,而不是反过来。
Infinity 实现了完整的全文索引功能,具体来讲包括如下方面:
- 提供实时索引和离线构建两种索引构建模式。
- 采用可配置的索引压缩格式,当前采用 SIMD-Bitpacking 作为默认的索引压缩格式,既保证一定压缩率,还提供高性能的解压速度。
- 采用 FST (Finite State Transducer) 数据结构作为索引的词典,既保证高性能,还提供有序遍历的前缀匹配能力。
- 实现了 Block-Max Maxscore 排序算法,因此在默认情况下, Infinity 全文索引针对查询关键词之间提供基于 OR 的语义查询,这既有效保证了召回,也保证了查询性能。
下边是Infinity v0.1.0 的 benchmark 表现(i5-12500H 16C 16GB, Ubuntu 22.04):
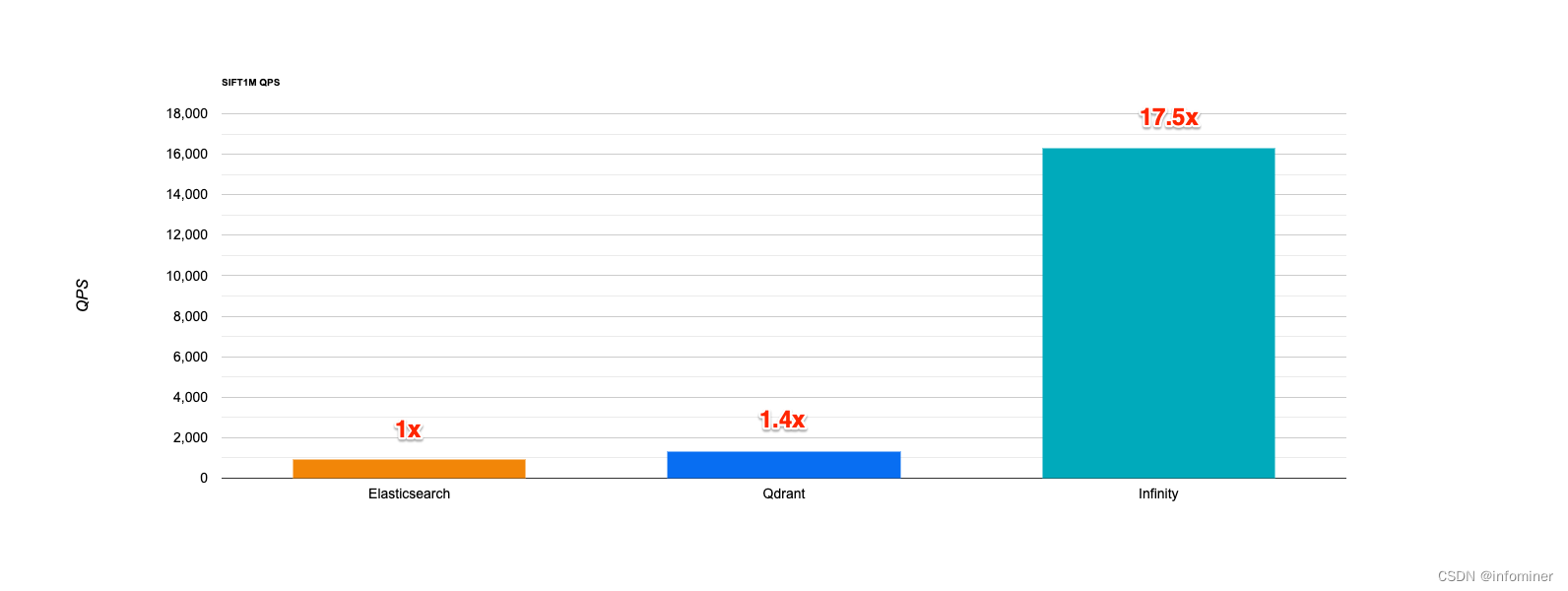
首先是向量搜索,下图是在 SIFT 1M 数据集上,Infinity(v0.1.0) 相比 Elasticsearch (v8.13.0) 和 Qdrant(v1.8.2) 的性能对比:
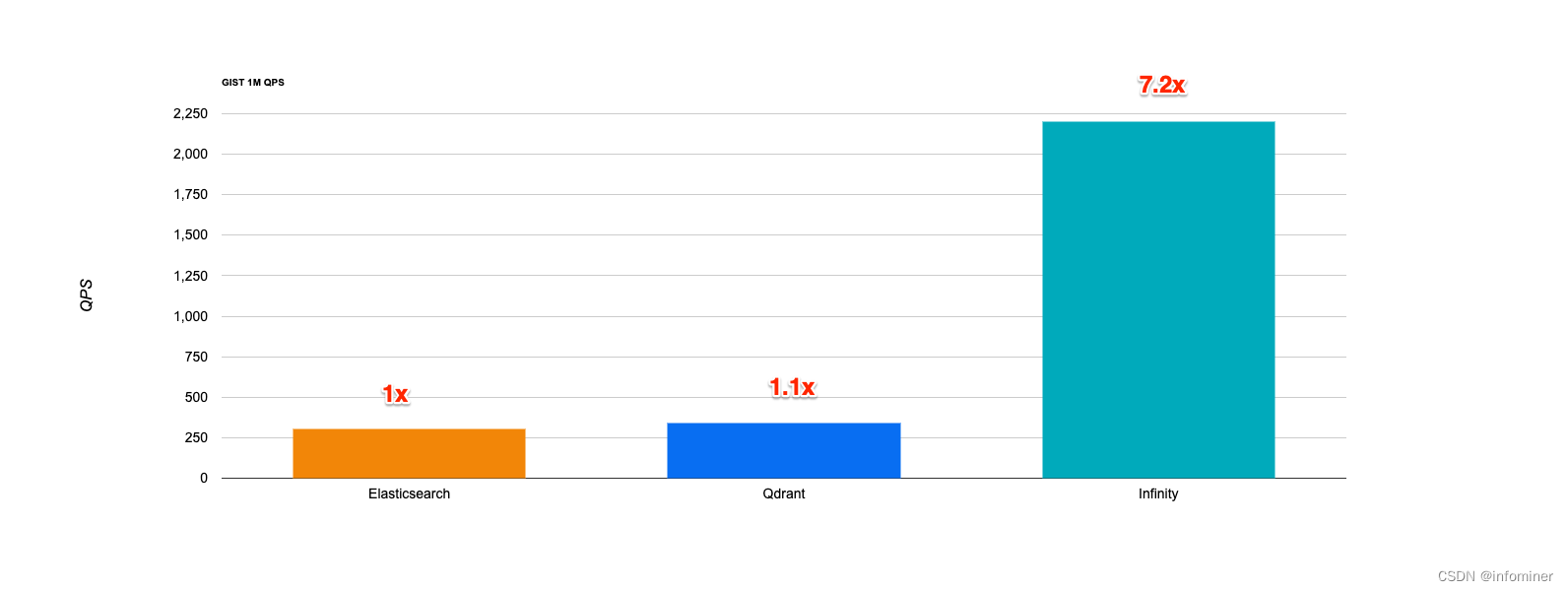
下图是在 GIST 1M 数据集上,Infinity 相比其他在向量搜索上的性能对比:
下图是在DBPedia 4.6M 数据集上, Infinity 和 Elasticsearch 在全文搜索上的性能对比:
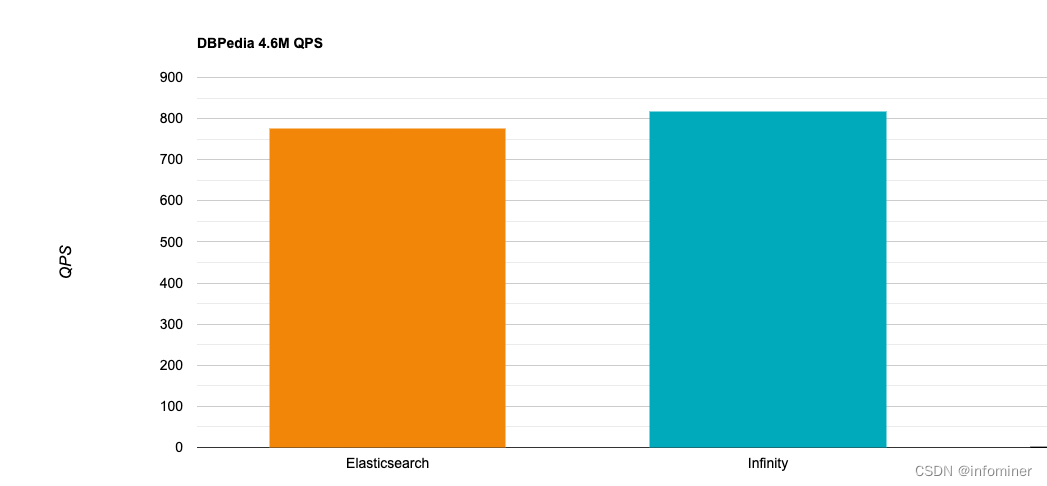
下图是在EnWiki 33M 数据集上, Infinity 和 Elasticsearch 在全文搜索上的性能对比:
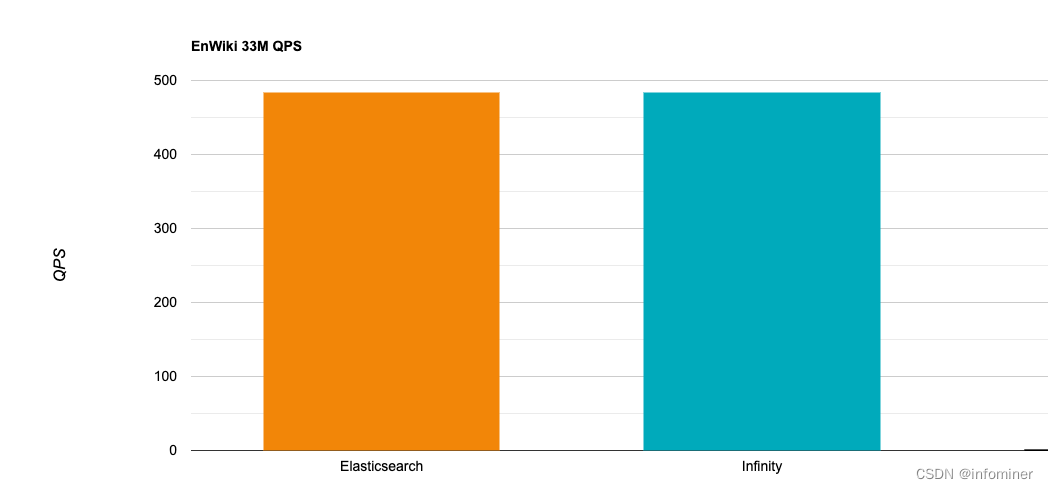
进一步的 benchmark 数据可参见文档 (https://github.com/infiniflow/infinity/blob/main/docs/references/benchmark.md)
因此,在当下,Infinity 可以说已经初步具备了 AI 原生数据库的基础能力,并且提供了最快的多路召回性能。接下来的版本,Infinity 会从多方面来不断迭代:
- 更快的性能
- 更多的为高级 RAG 提供服务的能力
- 分布式能力
欢迎关注 Infinity ,项目地址:https://github.com/infiniflow/infinity

















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









