






DeepSeek R1 在 2025 年初引发的震撼,让我们过去对于 LLM 关于推理和决策的预测时间点提早了大半年。如何让 LLM 具备更好的推理能力已经是 LLM 最热的研究方向之一。那么伴随着 LLM 的推理,RAG 需要做哪些调整? 这正是我们在当前写下本文的主要动机。
中文的推理对应两个不同的英文词汇,一个是 Inference,对应的概念是 Training(训练),另一个是 Reasoning,指对已知信息的演绎和综合,推导出新的知识和结论的过程。我们今天所说的推理,毫无疑问是指后者,因为它是真正让 LLM 及其配套解锁更大价值的源动力。推理并不是 R1 才引入的,LLM 本身的推理,在 2024 年的 Agent 上已经得到广泛使用。流行的 Agent 框架中,普遍涵盖四大模块 Plan、Memory、Action、Tool,以及几个设计模式,其中最知名和容易实现的就是所谓 ReAct。那么这类基于过去的 LLM 形成的推理,跟 R1 所带来的推理,在能力上有什么区别呢? 答案就在 R1 引入的思考链或者推理链。简单总结一下,推理的实现有如下技术流派:
-
利用提示词,实现 Agent 框架,例如基本的 ReAct。LLM 其实是具备推理能力的,哪怕没有 R1,但 LLM 需要跟随用户的指令。ReAct 的含义就是直接利用 LLM 进行 Reasoning + Action,其中 Reasoning 阶段利用 LLM 生成分析步骤,解释任务上下文或状态,给下一步行动提供逻辑依据。 Action 则依据 Reasoning 结果生成工具调用请求,像查搜索引擎、调用 API、数据库检索等,把推理变成行动。Reasoning and Action 每一步都是基于前一步的观察结果来决定的,这是一个逐步的、迭代的过程。当用户输入任务后,上下文和样本输入到 LLM 中,LLM 会调用目标工具,产生想法、行动和观察。ReAct 的每一步都依赖于前一步的输出,这意味着如果前一步出现问题,后续步骤可能会受到影响。ReAct 的执行过程是线性的,每一步都紧密依赖于前一步的结果。 Function Call 被用来解决和 ReAct 类似的问题,只是它要求 LLM 在训练的时候包含 Function Call 相关内容,对模型有一定要求。ReAct 其实是一种方法,由于在很多 Agent 框架中,对于 RAG 的强调不足,因此并没有发挥出 ReAct 的威力,导致 Agent 在实际中并没有带来更多的价值,而只是停留在基本的任务规划,这并没有充分发挥 LLM 的价值。因此,在 2024 年 Claude 的博文中【1】,Agent 实际上更多场景反而不如人工界定的工作流有价值。
-
改进模型本身,这就是 R1 的路线。R1 已经证明了通过强化学习训练鼓励模型合成 CoT 推理轨迹并从中学习所带来的价值。CoT 可以显著提高 LLM 的计算能力,而计算能力是推理的基础。CoT通过将一个复杂问题分解为多个中间步骤,增加了模型进行计算和信息处理的步骤数。可以理解为,CoT 增加了模型进行串行计算的机会,从而提高了整体的计算能力。更长的 CoT 链条允许模型在每一个步骤进行更加惊喜的推理,逐步逼近正确答案。
-
对模型结构本身进行扩展,例如 RAG,添加记忆模块,并借助于 Agent 机制。这个流派,跟路线一非常接近,区别主要在于是否把 RAG 放到了一个很重要的地步。RAG 代表着数据基座,只有基于数据来制定思考和推理计划,才能更加有针对性地进行提问和回答,避免路线一单纯依赖 LLM 和简单工具无法解锁高级场景的地步。 根据参考文献【2】的描述,推理本质上是一种在求解空间中进行搜索的过程。在 RAG 层面体现推理的一个重要手段是结合启发式搜索和增量微调。 例如 ReAct,由 LLM 把问题分解为系列逻辑子问题。但这种分解具备局限性,基于ReAct 模式容易陷入局部最优导致推理能力较弱,这是因为 ReAct 每一步的选择都依赖于局部信息,一旦选择了错误的搜索路径,后续步骤很难调整。因此一种思路是引入蒙特卡洛树搜索 MCTS 作为启发式搜索,通过奖励模型或者奖励函数评估搜索路径的质量,解决陷入局部最优的问题,例如参考文献【3】和参考文献【4】,都试图结合 RAG 和 MCTS 提供类似 o1 的推理能力,所不同之处在于,前者借助于奖励函数,而后者则借助于奖励模型,因此引入了对模型的增量微调。MCTS 的计算量巨大,它通过平衡探索和利用,在不确定的搜索链路上寻找最优路径,并且它还需要确定的奖励函数或者奖励模型,因此,在工程实现上,比较难以提供一个通用的解决方案,在一些垂直场景中,RAG + MCTS 的组合开始会有一些案例出现,例如已经出现通过准备足够的自然语言和 SQL 的映射作为 RAG 知识库,并设计定制的奖励规则,从而结合 MCTS 提供不需要微调 LLM 的 Text2SQL 方案。
RAGFlow 的最新版本,只关于路线三,且只关注如何提供通用方案,如何在基本 RAG 基础之上,进一步解锁推理功能,让 RAG 可以在用户自有数据上,提供自己的 R1 或者 o1。因此,采用启发式搜索和增量微调,以强化学习为基座的系列手段,并不在当前 RAGFlow 的能力规划——不过这仅仅代表在 2025 年春季的演进路线。在对基于此考虑的各路工业和学术的路线做一个总结和整理之前,我们先回答一个问题:是否基本的 RAG 直接接入了 R1 或者 o1,就可以具备推理能力了?——当然不是这么简单,固然基于内部数据提供的素材,利用 R1 或者 o1 可以直接生成推理链,进而产生更好的答案,但有一个问题不容忽视,就是这个答案的思考过程并非 R1 或者 o1 基于 RAG 返回数据,而仍然是来自模型本身的思考 —— 打一个比方,这就是用户提问,搜索素材,然后思考。那么根据这些素材思考的过程是否充分,就是个很大的疑问,因为推理模型只能根据这些素材进行思考。

下边进行总结和整理。
首先一个工作来自于参考文献【5】O1 Embedder,它试图通过训练得到一个具备推理能力的 Embedding 模型,确保同时生成高质量思考内容和精准检索的能力。具体做法,是通过准备包含查询、用 LLM 生成的思考内容、以及相关的文档组成的数据集来训练 Embedding 模型,该模型,给定文本,可以返回 Embedding,也可能返回思考内容。 因此这不是一个普通的 Embedding 模型,而是一个既包含 Embedding,也包含 Decoder 结构的文本生成组件。必须承认这种探索是有意义的,但推理能力本身如果脱离了 LLM ,可以说是放弃了整片森林。
下一个工作叫 Search o1(参考文献【6】),这个名字一听,就是专门在 RAG 基础之上提供推理能力的。Search o1 的工作流程包含 2 条主线: 一条是推理链,另一条叫 Reason-in-Documents, 两者是协同工作的。其中推理链是推理模型生成的,具体步骤如下:
-
初始化推理链:通过对问题理解和分解,来提供问题的背景和推理的总体要求,来提出具体需要解决的问题。
-
逐步生成推理步骤:
-
分解问题:把复杂问题分解为多个小问题或者推理步骤。
-
逻辑推理:基于已知信息(模型的内部知识和已经检索到的知识)逐步生成推理步骤。
-
生成推理序列:每一步推理都生成一个逻辑上连贯的句子或者段落,逐步推进问题的解决。
-
-
检测知识缺口:在推理过程中,模型可能会遇到知识不足的情况,例如:不确定某个概念的定义,不清楚某个过程的具体细节,需要最新的信息来推理等。此时,模型会生成一个检索查询。
-
根据 3 生成的检索查询,来触发外部检索。
-
根据外部知识检索的结果进行凝练,把知识注入到推理链,继续推理。
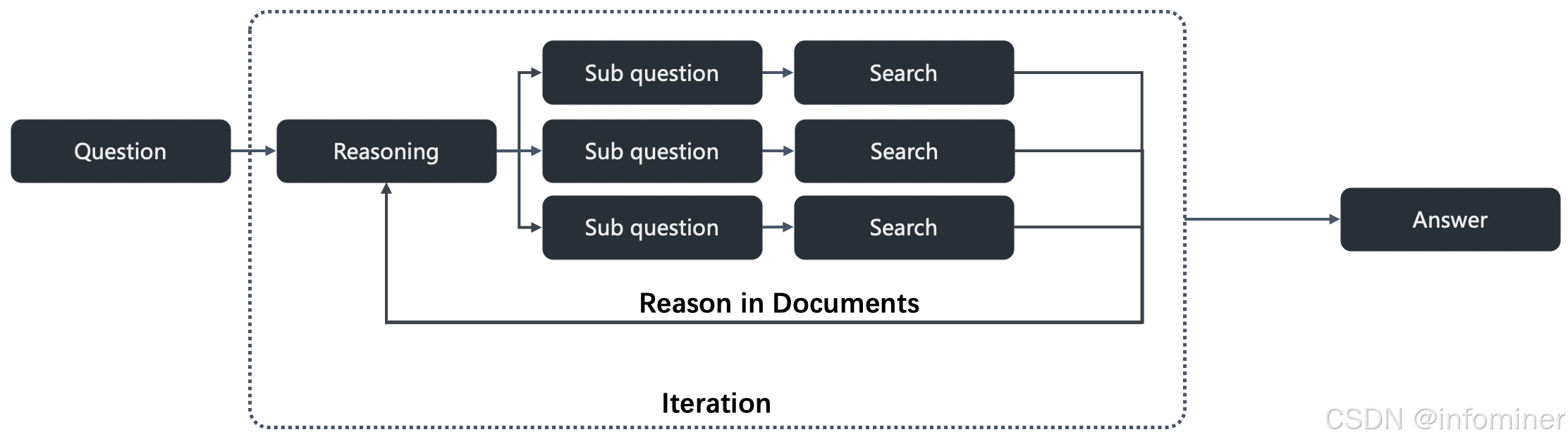
Reason-in-Documents ,主要目的是解决在 RAG 推理中直接使用检索到的文档可能导致的问题,例如冗余信息过多,干扰推理连贯性,它独立于主推理链运行,对检索到的文档进行深度分析和精炼,提取和当前推理步骤相关的有用信息。Search o1 的工作很完整,可以说是个纯工程性的学术工作。它的工作流程如下图所示,相比 RAG 直接套 R1 的做法,Search o1 最大的不同就在于它引入了迭代,通过迭代推理来反复修正得到高质量的问题,才能找到高质量的答案。但这里边有2个问题:
-
如何决定当前的思考是高质量的。
-
如何决定当前的迭代是可以终止的。
这2个问题很难解决,或者说,其实没有解决。但这不代表这种工程式的工作不 work。
下边一个工作是来自微软的 PIKE-RAG (参考文献【7】),它同样依赖 LLM 对用户的问题进行思考和任务分解,产生成多个子问题。所不同的是,它依赖 GraphRAG 来精炼,具体做法是在知识图谱上对多个子问题进行搜索,然后依据多个子问题的答案汇总得到多跳回答的结果。PIKE-RAG 特点是知识感知的任务分解,也就是任务分解过程会考虑知识库的内容,确保分解的问题能有效引导检索和推理过程。如果知识库中存在特定知识结构,任务分解会生成跟这些结构匹配的原子问题。具体的,PIKE-RAG 通过迭代的方式构建推理链,每次迭代中,系统会根据当前的子问题检索知识片段,并根据检索到的知识更新推理链。每次迭代,系统会从生成的原子问题中选择最相关的一个,并检索对应的知识片段,这些片段被逐步积累,形成推理链。当系统认为已经积累了足够的知识片段,或者进一步分解不再需要时,推理链构造会终止。PIKE-RAG 跟 Search o1 十分接近,都是工程性工作的代表。
下边来看一个叫做 Agentic Reasoning 的框架(参考文献【8】),论文标题,就可以看出,是利用 Agent 框架来实现 Deep Research。Agentic Reasoning 的核心思想是让 LLM 在推理过程中像人类一样动态调用外部工具获取信息、执行计算和规划思路。具体来说,推理模型在处理问题时,会根据当前的推理上下文,判断是否需要调用外部工具,生成相应请求。Agentic Reasoning框架包含 3 个内置 Agent:
-
思维导图 Agent:推理模型在生成推理链的时候,思维导图 Agent 会将推理链中的实体和逻辑关系提取出来,构建一个动态更新的知识图谱。当推理模型需要澄清逻辑关系或查询特定信息时,思维导图 Agent 通过知识图谱检索相关信息,帮助模型推理。
-
Web Search Agent:推理模型在推理过程中,如果需要来自 Web Search 的信息,会生成一个查询请求,Web Search Agent 收到该请求后,会调用 Web Search API 检索内容,结果被整合到推理链中。
-
Coding Agent:它主要用来生成代码。推理模型如果需要执行计算任务,Coding Agent 会根据提示词生成 Python 代码,并执行代码,将结果以自然语言形式返回并整合到推理链中。
因此,可以看到 Agentic Reasoning 跟 Search o1基本也是同类,只是增加了 Coding Agent 可以执行一些计算任务的思考。
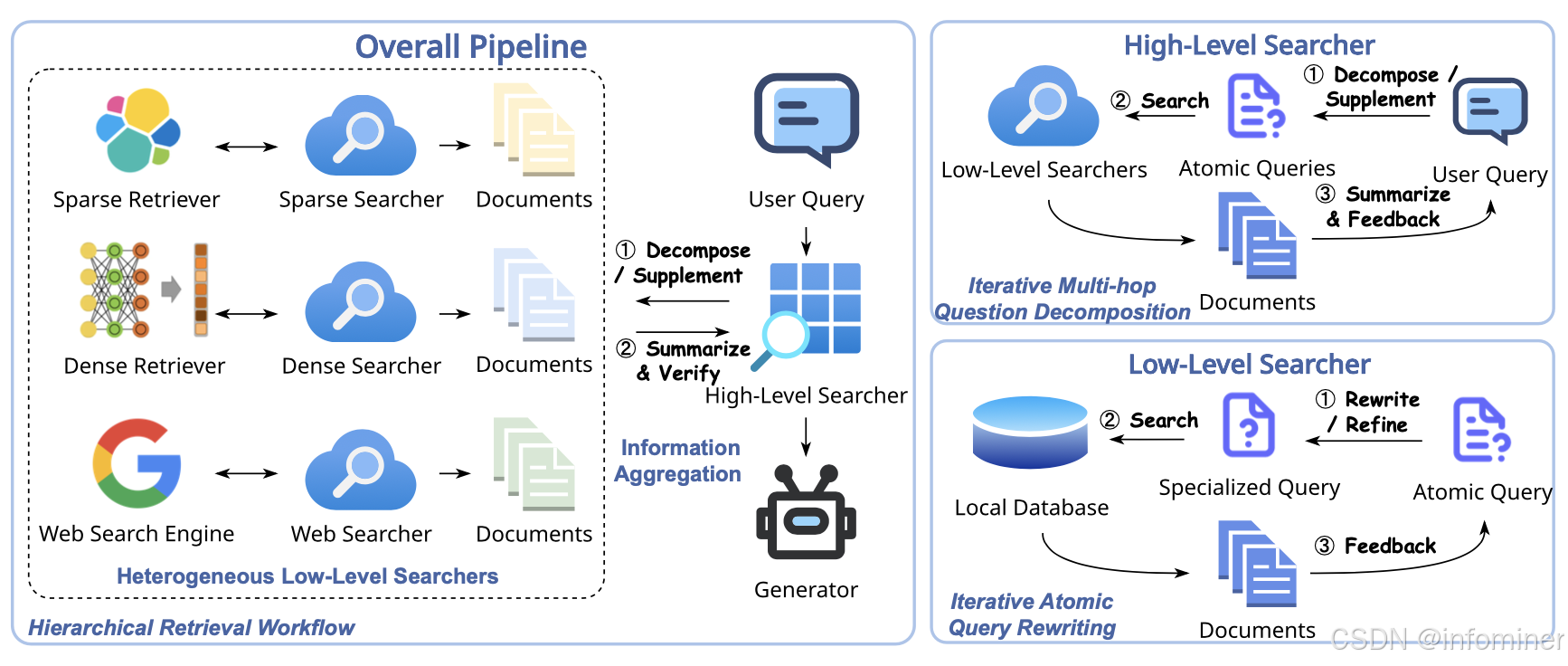
最新一个工作 LevelRAG (参考文献【9】),跟以上几个工作也基本类似,只是称呼不同:执行思考和问题分解的被称作 High-Level Searcher,执行具体搜索的被称作 Low-Level Searcher。放上论文的配图,看起来很好理解,就不多介绍了。
来自浙大和阿里通义的 OmniThink(参考文献【10】),同样是一个 Deep Research 类的工作,不过它并非基于推理的问答系统,而是基于推理的报告生成:旨在通过模拟人的思考过程,以 RAG 为基座生成高质量的长文本内容。它的工作过程分成3个阶段:
-
通过迭代的扩展和反思,构建信息树和概念池。前者是一个层次化的知识表示,用来组织和存储与写作主题相关的所有搜索到的信息。后者是一个动态更新的知识集合,用来存储 OmniThink 对写作主题当前的理解。它包含的内容是从信息树当中提取的核心观点,以及通过思考过程得到的见解。
-
基于概念池生成文章大纲。
-
根据大纲生成文章内容,并通过语义相似性检索相关信息,最终得到完整文章。
从输入主题开始,OmniThink 通过Web搜索引擎(如Bing或Google)检索与主题相关的初始信息。这些信息用来构建信息树的根节点,形成初始的概念池。所谓概念池是对主题的逐步理解,用来指导后续的扩展和反思过程。接下来,OmniThink 分析信息树的所有叶子节点,判断它们是否需要进一步扩展。对于需要扩展的叶子节点,OmniThink基于当前的概念池生成子节点,每个子节点代表当前节点的一个具体方面或者子主题,然后为每个子节点检索相关信息,并将其添加到信息树的相应位置。反思阶段会对新检索到的所有叶子节点的信息进行分析、过滤和综合,提取核心观点,这些核心观点倍整合到当前的概念池中,用来指导下一步的扩展过程。 以上是一个迭代的过程,直到满足以下条件之一:获取的信息足够丰富,可以用于文章生成;达到预设的最大检索深度。
至此可以看出,从 Search o1 开始的这些工作都是纯工程实现,没有引入任何算法和模型上的工作。它们的核心都是以 LLM 和迭代为基座,不断生成合适的问题或主题。它们都面临一些问题:推理链的质量如何评估;迭代式反思如何终止。
RAG-Gym(参考文献【11】),看名字就跟强化学习有着莫大的关系,它的核心思想是把问答任务建模为一个嵌套的 MDP 马尔可夫决策过程,外层 MDP 控制和检索环境的交互,内层 MDP 控制 LLM 的 Token 生成,外层 MDP 的奖励模型基于最终预测的正确性。RAG-Gym 是真正基于强化学习的 Agent ,采用监督微调等方式来训练 Agent,奖励模型训练的目的是让 Agent 知道哪些查询和推理是高质量的,从而能够引导 Agent 做出更好的决策。训练数据的收集,是通过收集智能体的决策轨迹,然后标注其中的高质量数据得到的。因此,RAG-Gym 是一种可以解决以上问题的工作:通过强化学习来评估质量,并终止迭代。同类的工作还有 DeepRAG (参考文献【12】),它也把基于 RAG 的推理建模为 MDP 马尔可夫决策过程,通过迭代分解查询,动态决定每一步是检索外部知识还是依赖参数进行推理。DeepRAG 专门解决上述推理工作的核心痛点:
-
子任务拆分不合理:有的问题不需要额外信息,但系统仍然盲目搜索,引入干扰。
-
缺乏决策机制:在什么情况下需要检索,没有智能判断的能力。
不过 DeepRAG 并没有直接引入强化学习,而是采用模仿学习搭配微调,来帮助模型更好理解其知识边界。
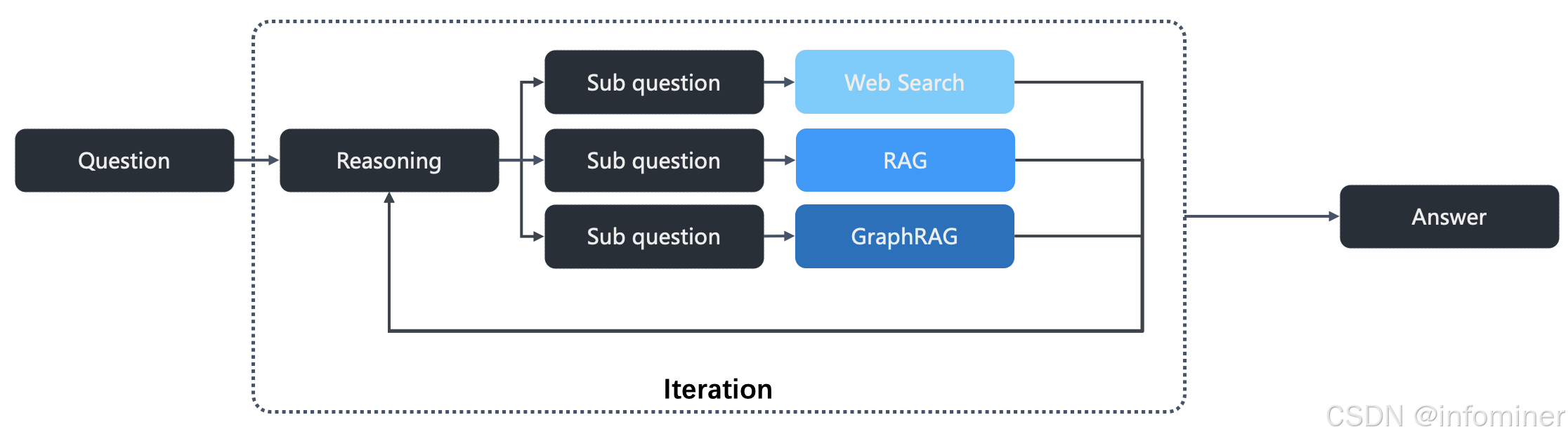
不论是 RAG-Gym 还是 DeepRAG, 都依赖 LLM 的监督微调,因此落地实现并不容易,更多代表对解决推理所面临痛点的一种探索。因此,在 RAGFlow 已经发布的 0.17 版本中,还是选择了工程更友好的方式来实现。具体做法中,RAGFlow 结合了 Search o1,PIKE RAG,Agentic Reasoning,LevelRAG 等工作的长处,是一个开源的 Deep Research 类工作的复现:
-
迭代式生成推理链。
-
每步推理链,都会产生若干子问题,这些子问题,会触发搜索请求。
-
搜索的内容,包含内部数据,也可以通过用户提供的 API Key,直接调用 Web 搜索。这在很多场景是有必要的,因为企业内部数据,往往对很多通用知识的描述是不足的,可以允许用户选择性调用 Web 搜索,来补充问题潜在的上下文常识。
-
搜索的内容,还可以包含知识图谱。事实上,GraphRAG 跟推理是非常有效的搭档以及合作伙伴:在 RAGFlow 的 GraphRAG 实现中,不仅仅构造了知识图谱,还针对原文的每个 Chunk ,通过调用 LLM 产生了该 Chunk 可能提出的问题。这些问题都被保存在 RAGFlow 的后台数据库中。在 LLM 思考和产生推理链的时候,这些问题,以及知识图谱,是重要的搜索对象,它们可以帮助 LLM 生成更加有效的提问,提供更加丰富的素材。
-
由 LLM 判断迭代是否需要终止。如果 LLM 一直没有判定,则根据阈值终止迭代。
-
最后根据完整的推理链汇总内容,得到最终结果,实现完整的 Deep Research 逻辑。
工作流程如下图所示:
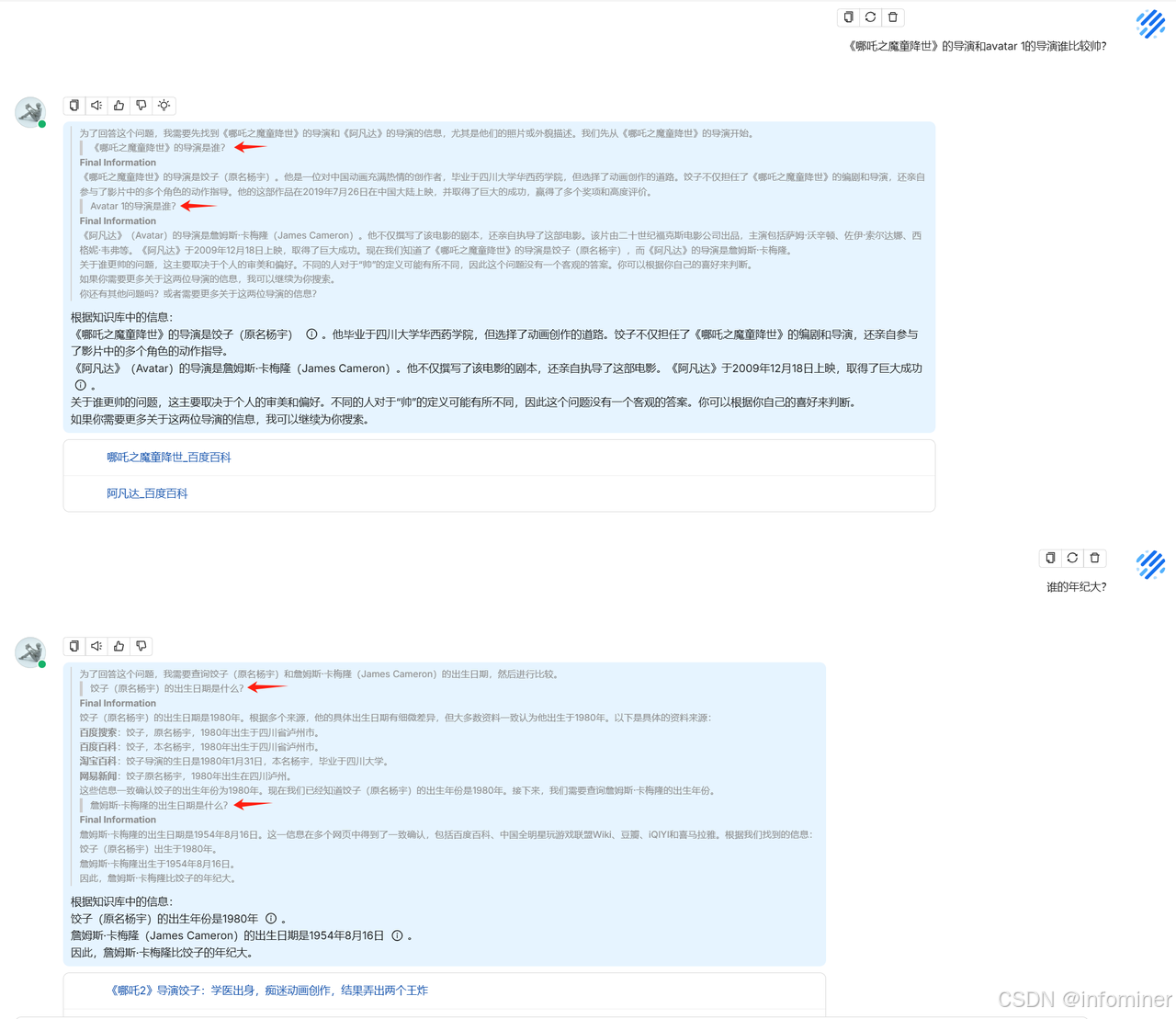
下边是采用 RAGFlow 连接 DeepSeek V3 得到的推理对话结果,看起来,跟 DeepSeek R1 结果十分类似。

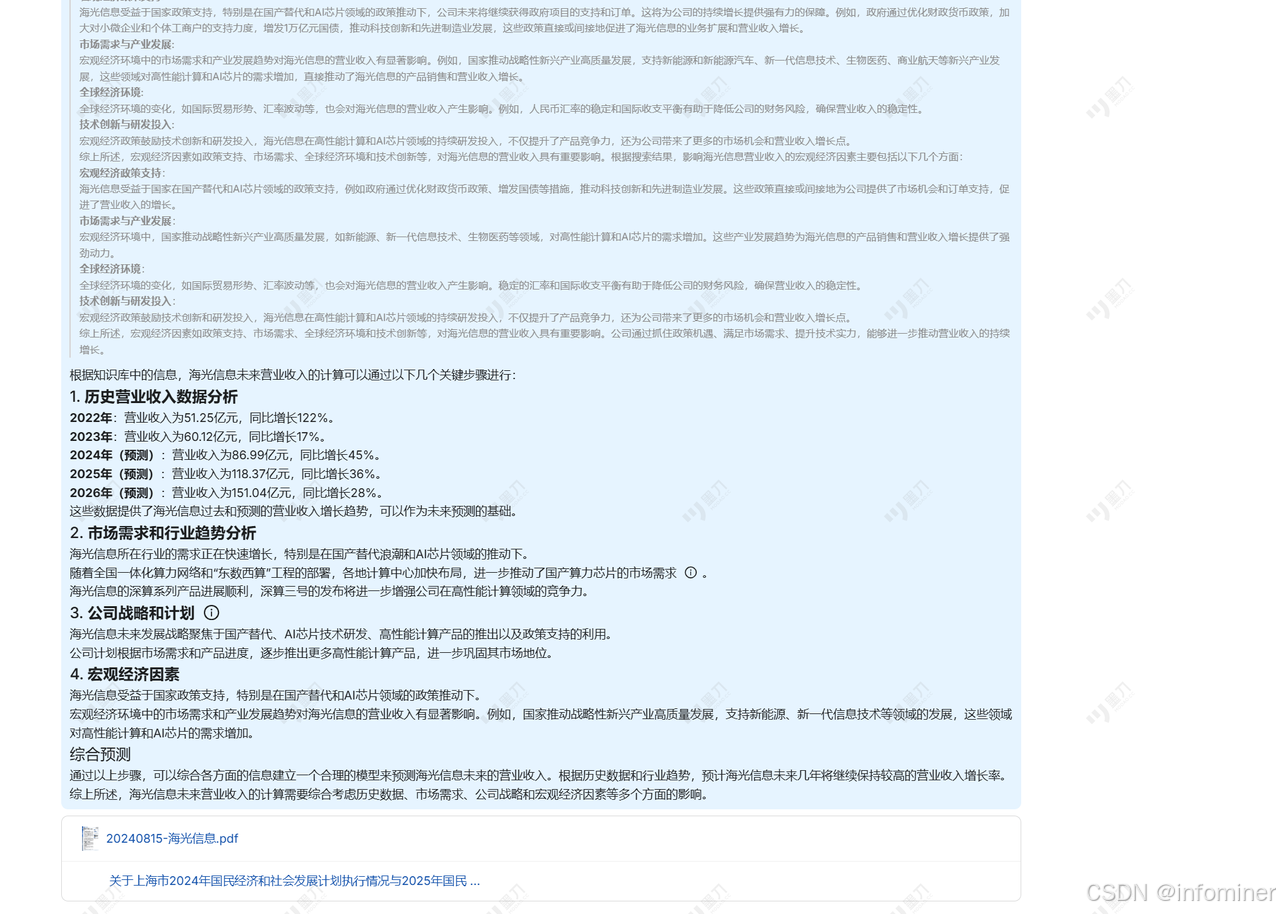
在使用推理大模型的过程中,我们目前有如下体会:
-
目前 RAGFlow 的推理型 RAG,又叫所谓 Deep Research,连接普通 LLM 例如 V3 跟连接推理 LLM 例如 R1,效果相差不大。但 R1 的思考过程很长,再引入这种迭代式思考,会变得更加长,因此其实不推荐直接采用 R1 。
-
并不是所有的 RAG 都依赖 R1。举例来说,我们看到社区有用户采用 RAGFlow 连接 R1,但他同时勾选了让 LLM 抽取关键词,甚至知识图谱,这会极大增加整个系统入库的延迟。因为 R1 会对每个入库的 Chunk 都会经过长时间思考才产生输出,而这些输出仅仅是一些关键词或者知识图谱的命名实体,它们并不需要思考来获得,因此这时用 R1 非常不合算。
-
这绝不是说 R1 没有价值,相反,当前的 R1,由于无法直接提供推理链的 API ,因此无法利用用户数据来生成专有的推理链,也无法实现一边推理思考一边检索数据的模拟人类思维的过程,这不能不说是让 R1 面向企业使用的一个痛点。 因此,当前 RAGFlow 所做的这些工作,是在 DeepSeek 开放推理链 API 之前,也能让企业利用自己的数据,受益于推理的探索。在各种场景下接普通 LLM 产生的结果,跟接推理 LLM 产生的结果,有哪些差异,也欢迎广大社区用户给到我们有益的反馈。
-
最后,我们期望 DeepSeek R1 这样的推理模型,尽快提供推理链专用 API,这样可以结合大模型强大的推理能力,针对用户数据生成更有价值的推理链,解锁更大的商业价值。
通过 RAGFlow 的 Deep Research 类工作,已经可以将 LLM 的推理能力,真正面向企业端产生一些实际的价值。例如我们可以利用它,结合健康数据,病例等给出诊断建议类报告;可以利用它,结合经营数据,运营数据,给出企业商业辅助决策;可以利用它,结合规章制度,案例给出判定决策辅助。。。 等等诸如此类。 如果说过去的 RAG ,仍然停留在知识库,问答,客服等浅层应用,那么今天的 RAG,已经开启了辅助决策的大门。在去年底 Claude 的博文中曾经断言,Agent 的价值还未充分发挥,因此实际场景中工作流采用更多。这个断言,随着推理能力的落地和进化,必定会发生变化——让 LLM 的思考,充分发挥决策,而尽力减少人工的编排和 Plan,是真正让 AI 走向普适的标志,这个标志已经出现,并且在今年会加速进化。这也是为何 RAGFlow 如此快速推出推理能力的主要原因。推理 + 搜索,这就是 AI 服务企业的核心依托,欢迎大家持续关注 RAGFlow ,永远致力于提供最好的 RAG 核心引擎,在 Github 上为我们点亮星标 https://github.com/infiniflow/ragflow
参考文献
-
https://www.anthropic.com/research/building-effective-agents
-
On the Emergence of Thinking in LLMs I: Searching for the Right Intuition https://arxiv.org/abs/2502.06773
-
MCTS-KBQA-Monte Carlo Tree Search for Knowledge Base Question Answering https://arxiv.org/abs/2502.13428
-
KBQA-o1-Agentic Knowledge Base Question Answering with Monte Carlo Tree Search https://arxiv.org/abs/2501.18922
-
O1 Embedder-Let Retrievers Think Before Action https://arxiv.org/abs/2502.07555
-
Search-o1-Agentic Search-Enhanced Large Reasoning Models https://arxiv.org/abs/2501.05366
-
PIKE-RAG-sPecIalized KnowledgE and Rationale Augmented Generation https://arxiv.org/abs/2501.11551
-
Agentic Reasoning-Reasoning LLMs with Tools for the Deep Research https://arxiv.org/abs/2502.04644
-
LevelRAG-Enhancing Retrieval-Augmented Generation with Multi-hop Logic Planning over Rewriting Augmented Searchers https://arxiv.org/abs/2502.18139
-
OmniThink-Expanding Knowledge Boundaries in Machine Writing through Thinking https://arxiv.org/abs/2501.09751
-
RAG-Gym-Optimizing Reasoning and Search Agents with Process Supervision https://arxiv.org/abs/2502.13957
-
DeepRAG-Thinking to Retrieval Step by Step for Large Language Models https://arxiv.org/abs/2502.01142

















 1968
1968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









