






前言
大语言模型(LLM)因“涌现能力”(emergent abilities)而拥有了超出人类预期的技能,但也因此让人类十分忌惮:操纵、欺骗人类,自主实施网络攻击,自动化生物研究…
然而,也有专家认为,这种过度的担忧会损害开源和创新,不利于人工智能(AI)行业的健康发展。当前,有关“AI 灭绝伦”的争论愈演愈烈。
那么,“涌现能力”真的是导致 AI 大模型威胁人类生存的罪魁祸首吗?一项最新研究否定了这一观点。
来自达姆施塔特工业大学和巴斯大学的研究团队发现,GPT 等 LLM 尚无法独立地学习或获得新技能,这意味着它们不会对人类构成生存威胁。
他们表示,“涌现能力” 背后的真相或许比科幻电影更富有戏剧性,许多所谓的“涌现能力”,其实都是 AI 大模型在面对不熟悉的任务时,依赖于已有的数据和经验做出的“即兴表演”。
相关研究论文以 “Are Emergent Abilities in Large Language Models just In-Context Learning?” 为题,已发表在 AI 顶会国际计算语言学年会(ACL)上。

他们通过一系列实验验证了 AI 大模型在不同上下文条件下的表现,结果发现:在零样本(zero-shot)的情况下,许多大模型根本无法展现所谓的“涌现能力”,反而表现得相当一般。
他们表示,这一发现有助于理解 LLM 的实际能力和局限性,并为未来的模型优化提供新的方向。
智能涌现:只是“即兴表演”?
AI 大模型的“涌现能力”来自哪里?它是否真如听起来那样神秘,甚至令人担忧?
为了破解这一谜题,研究团队选择了 GPT、T5、Falcon 和 LLaMA 系列模型作为研究对象,通过实验分析了非指令微调模型(如 GPT)和指令微调模型(如 Flan-T5-large)在 22 个任务(17 个已知的涌现任务和 7 个基线任务)和不同条件下的表现。
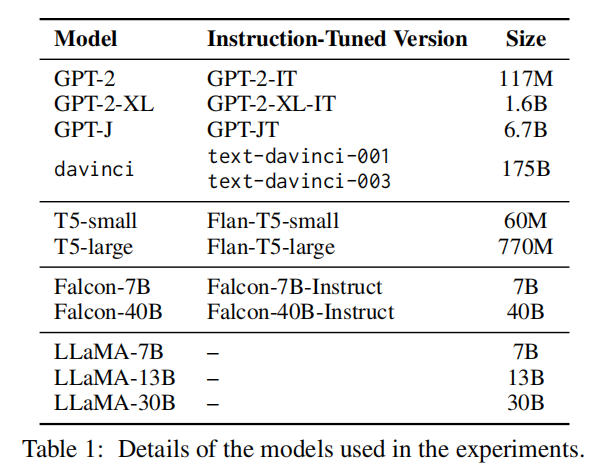
图|模型列表。
为了全面评估模型能力,他们将 Exact Match Accuracy、BERTScore Accuracy 和 String Edit Distance 作为评估指标。同时,为了提高实验的准确性,他们还进行了偏见控制,通过调整提示和输出格式,确保非指令微调模型的公平性,并通过手动评估验证模型输出的准确性。
在实验中,研究人员采用 zero-shot 和少样本(few-shot)两种设置,重点分析了 GPT 的表现能力。
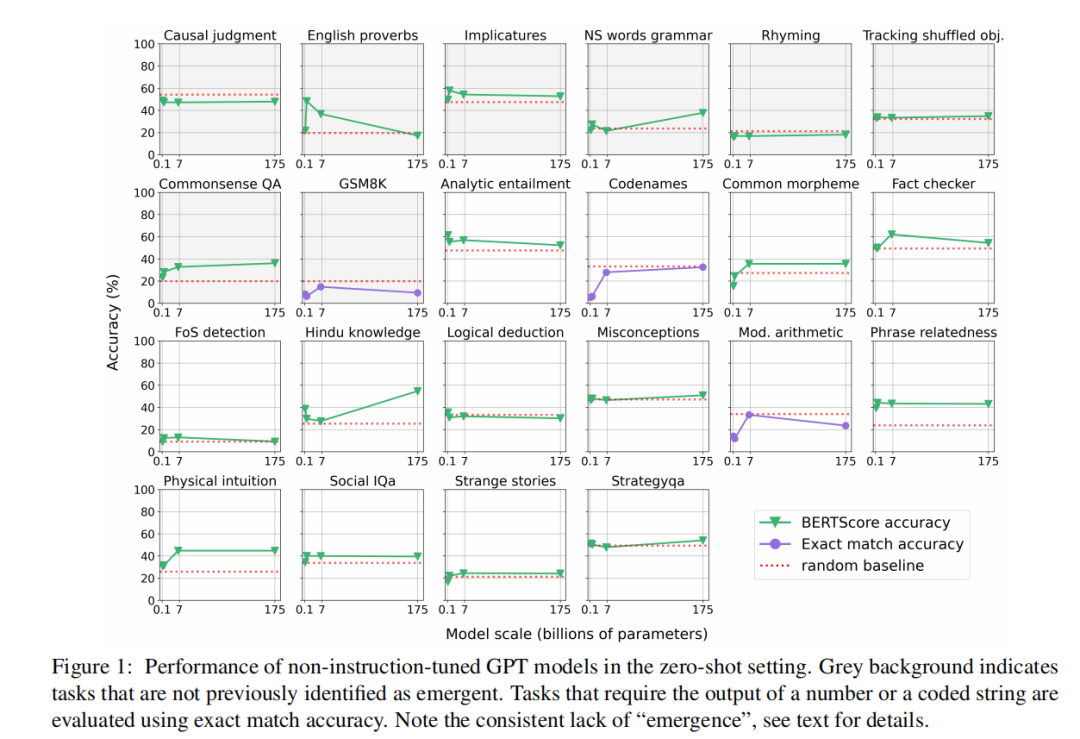
图|非指令微调 GPT 模型在零样本下的表现。
令人惊讶的是,尽管 GPT 在之前的研究中被认为具有涌现能力,但在 zero-shot 的情况下,这种能力表现得非常有限。
具体而言,只有两个任务在不依赖上下文学习(ICL)的情况下展示了涌现能力,这两个任务主要依赖形式语言能力或信息检索,而非复杂的推理能力。由此可以得出,在没有上下文学习的条件下,GPT 模型的涌现能力受到了极大的限制。
然而,涌现能力的来源仅仅如此吗?研究团队又将目光转向了指令微调模型,提出了一个大胆的假设:指令微调并非简单的任务适应,而是通过隐式上下文学习,激发了模型的潜在能力。
通过对比 GPT-J(非指令微调)与 Flan-T5-large(指令微调)的任务解决能力,他们发现,尽管两者在参数规模、模型架构和预训练数据上存在显著差异,但在某些任务上的表现却出奇地一致。
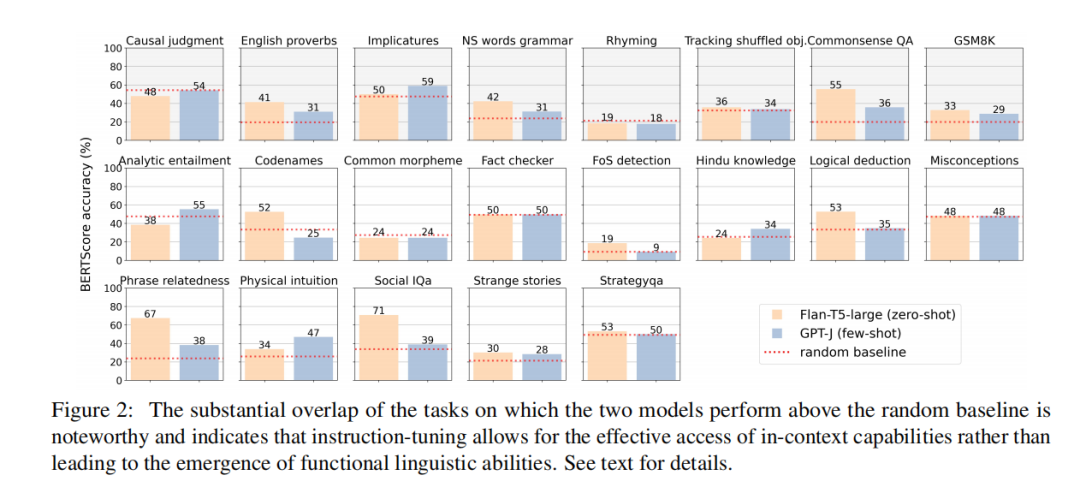
图|两个模型的表现在高于随机基线部分有很大的重叠,这表明指令微调可以有效地获取上下文中的能力,而非导致功能性语言能力的涌现。
这一现象表明,指令微调模型可能并不是在展示一种全新的推理能力,而是通过隐式上下文学习,巧妙地利用了已有的上下文学习能力。
进一步的实验表明,无论是模型规模的增加,还是训练数据的丰富,指令微调模型在 zero-shot 的情况下,仍然能够与非指令微调模型表现出相似的任务解决能力。这一发现再次强调了指令微调与隐性上下文学习之间的紧密联系。
AI 威胁人类生存:真实还是夸大?
尽管 LLM 在任务表现上展现出超凡的能力,但研究结果表明,这些能力并不意味着 AI 对人类生存构成实质性的威胁。
首先,LLM 的涌现能力主要来源于上下文学习和指令微调,这些技术在模型的设计和训练中是可以被预测和控制的,并未表现出完全自主发展的趋势,也没有产生独立的意图或动机。
例如,在社交智力测试(Social IQA)中,模型能够正确回答涉及情感和社会情境的问题,例如:“卡森醒来去上学时很兴奋。他为什么要这样做?”
在这一问题中,模型通过上下文学习和指令微调,能够超越随机基线(random baseline),选择出合理的答案。这说明模型并非在自发产生某种“智能”,而是在具体输入和设计条件下展现出的一种高级模式识别能力。
其次,研究发现随着 LLM 规模的扩大,这些能力表现得更加显著,但并未脱离设计者的控制。通过对模型的微调,可以引导 LLM 更好地理解和执行复杂任务,而这种能力的增强并不意味着模型会产生自主意识,还不足以对人类产生威胁。
在实验中,LLM在特定任务上的表现大大优于随机基线,尤其是在需要推理和判断的任务中。然而,这种表现依然依赖于大量训练数据和精心设计的输入提示,而非模型自发的智能觉醒。
这一结果进一步证实 LLM 的涌现能力是在可控范围内发展的,虽然这一假设仍需进一步的实验证实,但为研究理解大模型的涌现能力提供了一个全新的视角。
研究指出,虽然未来人工智能可能会在功能性语言能力上进一步发展,但其潜在危险性依然是可控的。现有证据还不能支持“AI灭绝伦”的担忧,相反,AI 技术的发展正在逐步朝着更加安全和可控的方向前进。
不足与展望
尽管这项研究为理解 LLM 的涌现能力提供了重要的见解,但研究人员也指出了该研究的局限性。
当前的实验主要集中在特定的任务和场景下,而 LLM 在更加复杂和多样化的情境中的表现尚需进一步研究。
研究人员表示,模型的训练数据和规模仍然是影响涌现能力的关键因素,未来的研究还需进一步探索如何优化这些因素,从而提高模型的安全性和可控性。
他们计划进一步研究 LLM 在更加广泛的语言和任务环境中的表现,特别是如何通过改进上下文学习和指令微调技术来增强模型能力,且确保安全性。
此外,他们还将探讨如何在不增加模型规模的情况下,通过优化训练方法和数据选择,实现涌现能力的最大化。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









