






前言
人工智能历经数十年的发展,大模型的出现再度引发学术界、产业界的关注,该领域表现出的巨大发展潜力吸引了国内外数百家企业投入其中,工业和信息化部数据显示截至2023年年底,我国累计发布了200多个人工智能大模型。与以往人工智能的研究不同,大模型由于其更靠近产业应用,商业化路径较短,加上厂阔的应用空间,吸引了众多类型的企业成为建设方,形成了如今“百模大战”的局面,电信运营商也早早入局,依托其产业优势,打造从硬件到软件体系化的大模型产品。
幻影视界今天分享的是人工智能AI行业研究报告:《2024年AI大模型应用发展研究报告:电信运营商与云服务商的合作探索》, 报告版权方/来源:腾讯云&中国信通院&中国通信标准化协会。

有需要完整报告的朋友,可以扫描下方二维码免费领取👇👇👇

研究报告内容摘要如下
AI大模型市场规模持续增长,国内外呈现混战格局
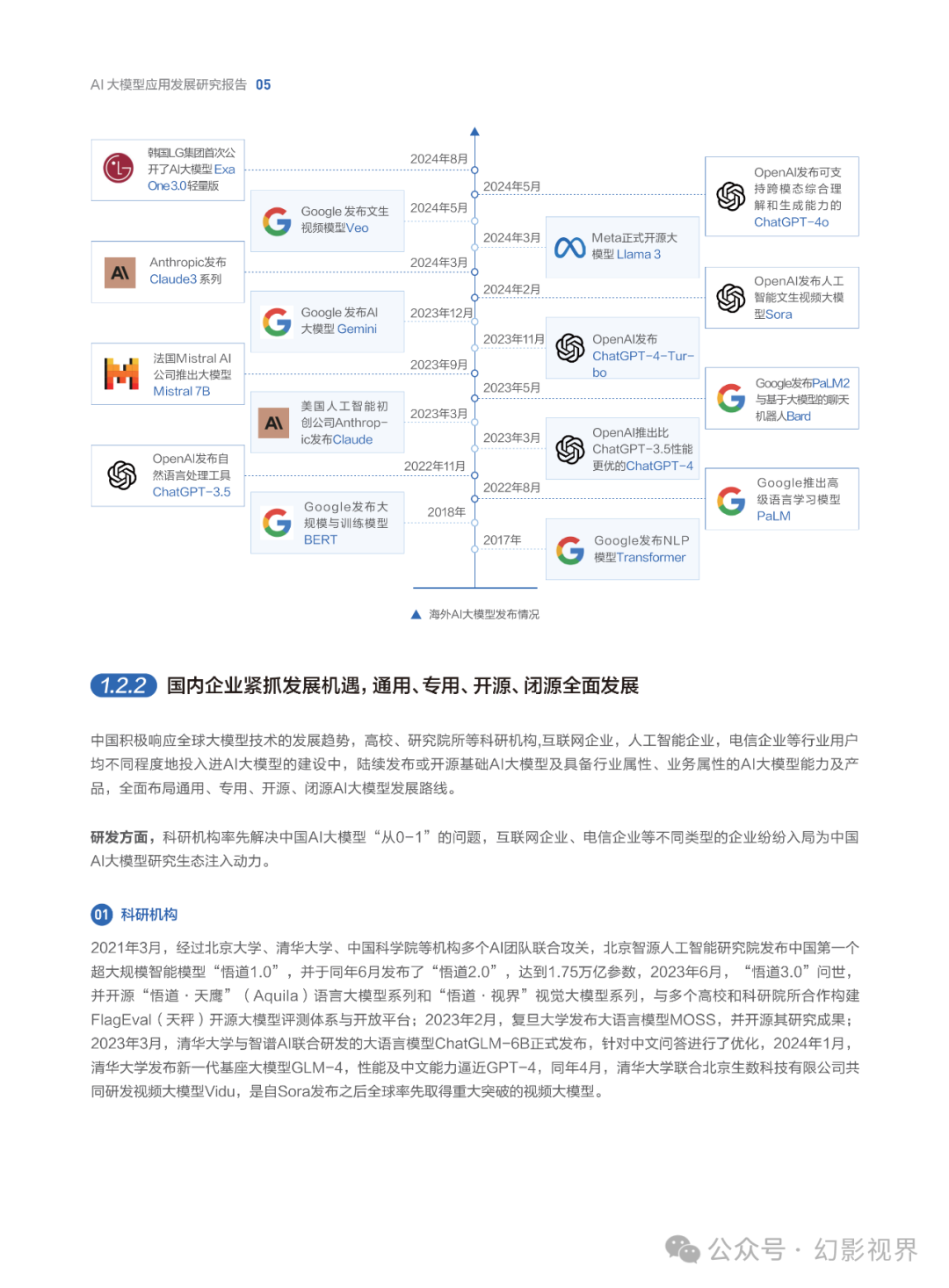
据IDC预测,全球Al计算市场规模将从2022年的195亿美元增长到2026年的346.6美元,其中生成式AI计算市场规模将从2022年的8.2亿美元增长到2026年的109.9亿美元。在全球范围内,中美两国在Al大模型的研发上发挥着引领作用。2024全球数字经济大会上发布的最新数据显示,全球AI大模型已经超1300个,中国研发的Al大模型数量仅次于美国,位列全球第二,中美发布的Al大模型数量占全球的80%。其他国家也正加速发展人工智能产业及Al大模型,形成国内外AI大模型百花齐放、竞相发展的局面。
大模型建设方持续多元化发展 ,电信运营商走出 “体系化”建设道路
在中国人工智能领域,除了互联网及云服务商之外,电信运营商正依托其丰富的算力、网络等基础设施以及多年的用户、数据基础,逐步发展互联网、云服务等业务,也在Al大模型领域持续投入,相继发布研究成果,成为Al大模型建设方的重要力量。
优势互补,电信运营商与云服务商在竞争中探索合作共赢新局面
多样产业角色入局共建AI大模型,带来的首要影响是市场竞争格局日益激烈。与众多新技术的发展路径类似,企业在扩张市场广度的同时进行市场深度的拓展,即通过技术合作、行业融合、产业协同等方式探索更多的应用领域、应用方式、社会价值。
电信运营商与云服务商均已形成各自的AI大模型研究基础与研究体系,发布具备各自企业特征的AI大模型产品,在大模型发展的下一阶段,电信运营商与云服务商正探索如何通过合作有效调动起双方优势,打造合作共赢的新局面。
集群三路线,服务商助力电信运营商进行软硬兼备的Al大模型建设储备
AI大模型的出现对算力需求带来了指数级的增长。OpenAI发布的GPT-3模型包含1750亿个参数,需要进行数千万次的计算操作来完成次推理任务。如何将训练好的模型推广与应用,并最终赋能社会生产及产生社会价值,需要在硬件建设及软件设计阶段就做好准备。
从硬件来看,算力集群能力的高低决定了AI大模型能否在合理的时间内完成训练,决定了模型投入市场的周期以及它们在实际应用中的性能表现。
从软件来看,软件建设和设计路线,决定了软件未来的应用范围和使用体验。云服务商从自身建设经验出发,结合电信运营商面临的挑战及优势能力,支持运营商打造适用于AI大模型训练的算力集群,形成助力电信运营商完成AI大模型设计、应用的软件研发合作路线。
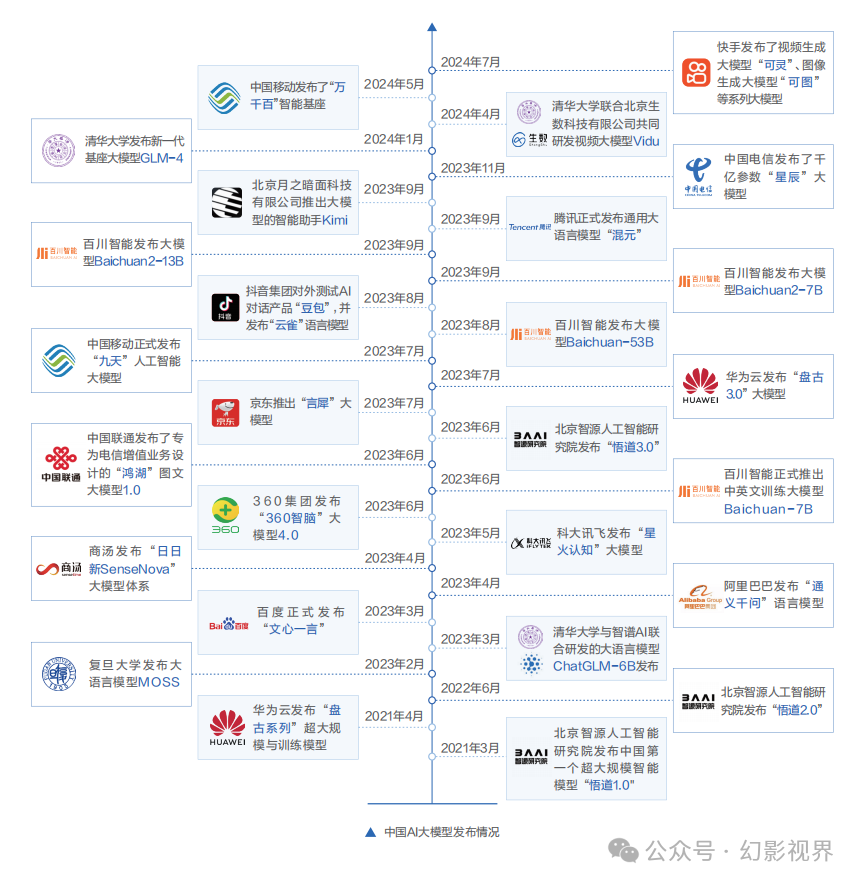
Al大模型对网络性能需求:大带宽、负载、零丢包的无损网络。
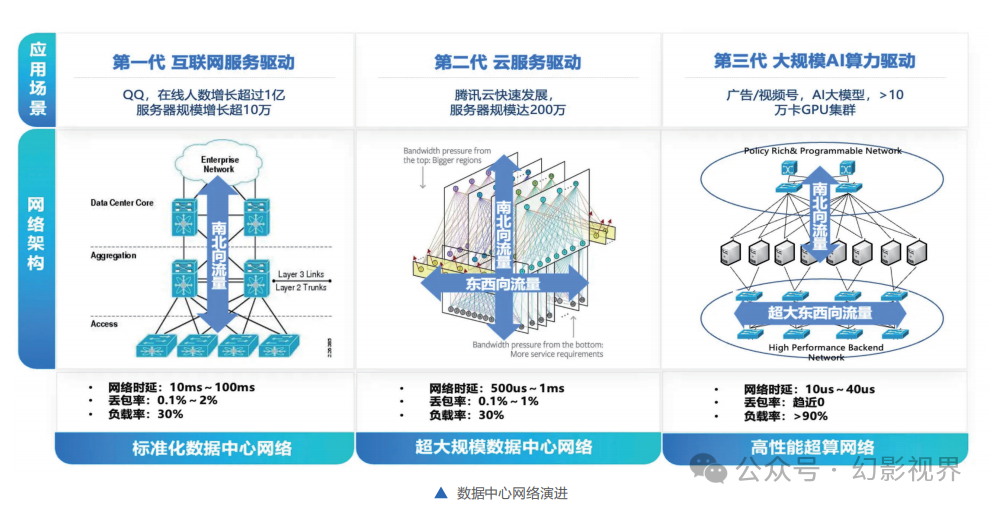
AIGC的火爆带来Al大模型参数量从亿级到万亿级的飙升。为支撑海量数据的大规模训练,大量服务器通过高速网络组成算力集群,互联互通,共同完成训练任务。大集群不等于大算力,相反,GPU集群越大,产生的额外通信损耗越多。大带宽、高利用率、信息无损,是AI大模型时代网络面临的重要挑战。
**千亿、万亿参数规模的大模型,训练过程中通信占比最大可达50%,传统低速网络的带宽远远无法支撑。**同时,传统网络协议容易导致网络拥塞、高延时和丢包,而仅0. 1%的网络丢包就可能导致30%-50%的算力损失,最终造成算力资源的严重浪费。AI大模型对网络规模、性能、可靠性、成本、运营能力要求方面提出了更高的要求。
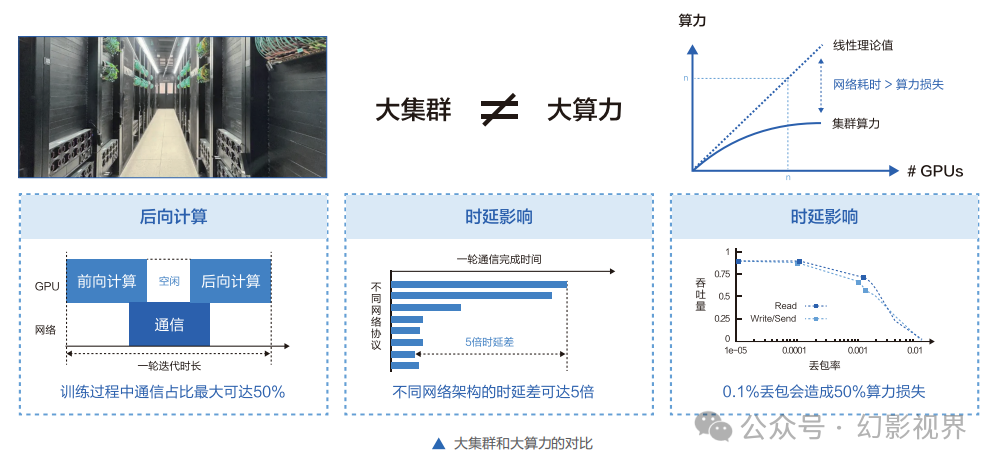
高性能智算网络底座:让大模型训练的网络通信“交通顺畅”。
当前在大模型算力集群中普遍采用IB ( InfiniBand )网络和RoCE ( RDMA over Converged Ethemet )网络两种技术路线。随着集群需求和规模的扩大,算力集群的组网能力已经从设备级往业务级的运营运维演进。InfiniBand网络以其高性能、低延迟和高可靠性,在高性能计算组网中得到广泛应用。其容易上手,但技术体系封闭,主要基于网络设备级能力,不利于深度运营。
RoCE依赖于各厂商提供的技术方案成熟度,随着越来越多的头部互联网及AI厂商越来越多采用基于以太网络的业务级运营运维路线构建RDMA网络,在业界的最佳实践中其在性能上得到有效的保证。
另一方面, 其进一步扩展了网络底座能力的边界,已从单纯网络设备级的运营运维能力延伸到云网端协同,再进一步扩 展到业务级的运营运维能力。比如,Meta在最新的L lama3大模型训练环境采用以太网协议RoCEv2,而腾讯的混元大模型基于RoCEv2构建的智能高性能网络,在高效训练中实现业务0中断。
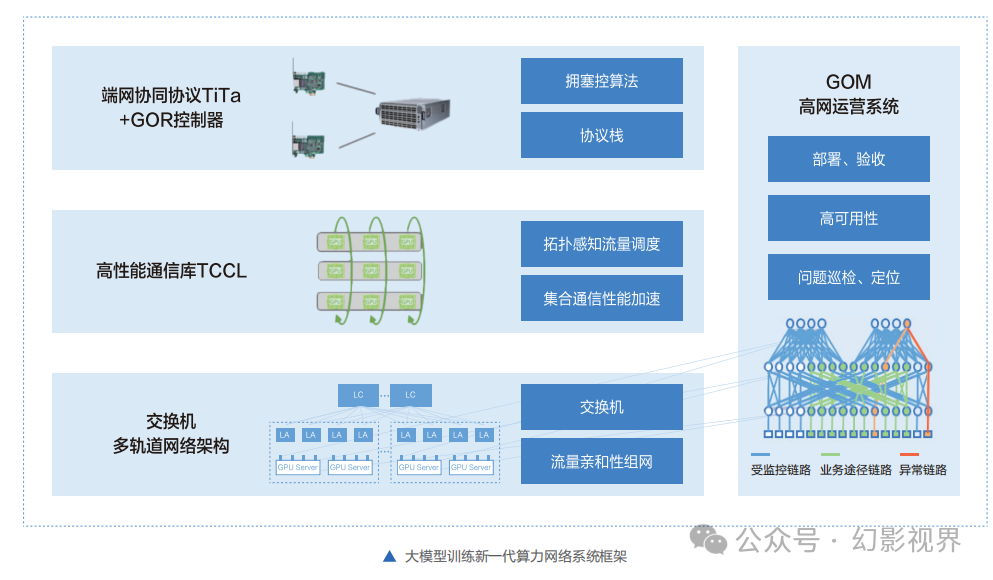
大模型训练新-代算力网络系统在大规模组网上,采用无阻塞胖树(Fat-Tree)拓扑,分为Block-Pod-Cluster三级。
-
Block是最小单元,包括256个GPU。
-
Pod是典型集群规模,包括16~64个Block, 即4096~16384个GPU。
-
多个Block可以组成Cluster。1个Cluster最大支持16个Pod, 即1个cluster可支持65536- -262144个GPU。最高26万个GPU的规模能够满足当前训练需求。
N个场景,云服务商支持电信运营商构建AI大模型场景化解决方案
云服务商支持运营商发展大模型应用的策略涉及多个层面,旨在提供全面的技术和服务支持。首先,云服务商拥有强大的AI算力资源,可以补齐运营商在算力分布、算力种类、算力合规方面的需求,以支撑大模型的训练和推理需求。此外,云服务商积极促进大模型生态建设,通过开源社区和合作伙伴网络,推动技术的共享与创新。提供易用的开发工具和工作流,帮助运营商降低技术门槛,加速大模型的开发和部署。同时,云服务商注重数据安全和隐私保护,确保平台符合法规要求,保护数据安全。
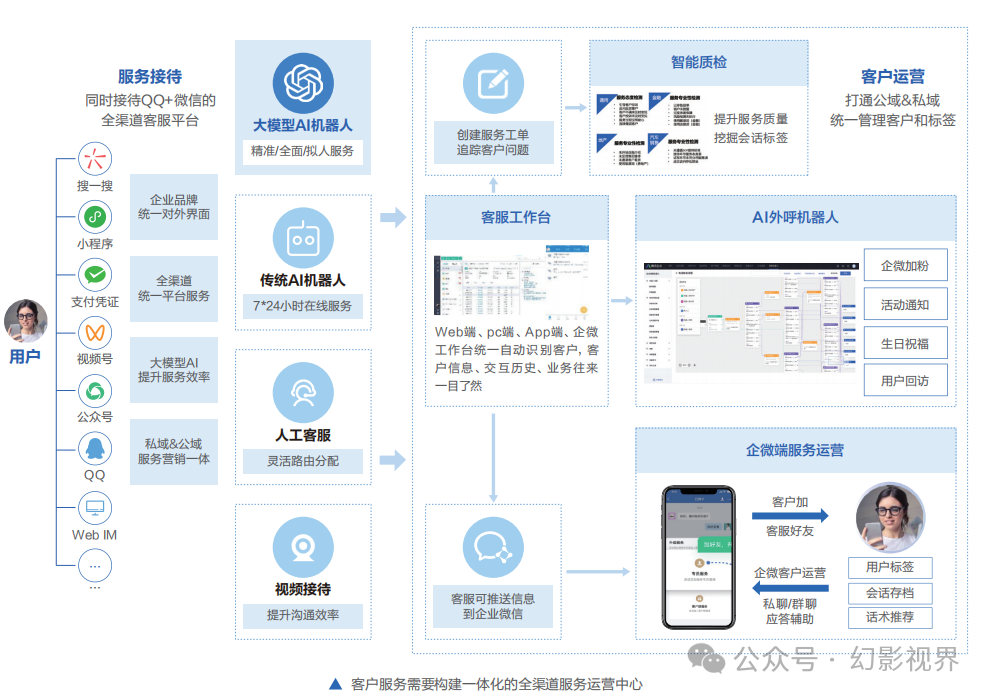
在商业模式创新方面,云服务商与电信运营商共同探索新的服务模式,如基于订阅的服务或按使用量计费,以实现商业价值的最大化。支持多云和混合云策略,为运营商提供灵活的云服务选项,适应不同部署和管理需求。云服务商支持电信运营商大模型应用落地,参与多个场景的共建中,包括:企业知识应用、视联网内容分析、增值内容创作、客服场景、DICT合作等场景。
技术演进,大模型建设与应用不断探索高效率、高精度、高适用性
随着大模型技术的发展及产业生态的丰富,AI大模型除了通过大参数量满足场景普适性需求之外,在计算资源日渐紧缺的背景下,未来将更加关注AI大模型的效率、精度以及场景的适用性。
从效率要求来看,模型训练时常直接决定了AI大模型的生产成本,资源使用上,需要不断探索当前计算性能瓶颈的解决方案,提升有限的高性能计算资源利用效率,例如智算高性能传输网络、高性能并行计算调度方法、高性能训练框架等;模型设计上,避免为了追求大的模型参数量无效地复杂化模型结构,而是将更多的精力投入到模型优化上来。
从精度要求来看,模型的推理精度直接决定了模型的使用体验,在Al大模型激烈竞争的当下,还有可能决定了产品和企业的存亡。不断提升AI大模型的推理精度,在法律法规要求的范围内,提升Al大模型的自然语言交互能力、响应速度、准确程度仍旧是未来-段时间AI大模型的研究重点。
从应用要求来看,伴随大模型的推广以及行业大模型的落地,AI大模 型的部署设备将会从传统的服务器向云、边、端侧算力扩展,应用场景也将出现更加强烈的行业属性,AlI大模 型如何在保证效率、精度的情况下更好的适配多样算力环境、多样应用环境,也将是AI大模型的建设方下一阶段要考虑的重要命题。
幻影视界整理分享报告原文节选如下:






有需要完整报告的朋友,可以扫描下方二维码免费领取👇👇👇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









