







Liner、RNN、LSTM的构造方法\输入\输出构造参数
pytorch中所有模型分为构造参数和输入和输出构造参数两种类型。
- 模型构造参数主要限定了网络的结构,如对循环网络,则包括输入维度、隐层\输出维度、层数;对卷积网络,无论卷积层还是池化层,都不关心输入维度,其构造方法只涉及卷积核大小\步长等。这里的参数决定了模型持久化后的大小.
- 输入和输出的构造参数一般和模型训练相关,都需指定batch大小,seq大小(循环网络)\chanel大小(卷积网络),以及输入\输出维度,如果是RNN还需涉及 h 0 h_0 h0和 c 0 c_0 c0的初始化等。(ps:input_dim在循环网络模型构造中已经指定了,其实可以省略掉,从这点看Pytorch的api设计还是有点乱,包括batch参数的默认位置在cnn中和rnn中也不相同,囧)。这里的参数决定了模型训练效果。
Liner
- Liner(x_dim,y_dim)
– 输入x,程序输入(batch,x)
– 输出y, 程序输出(batch,y)
代码演示:
import torch.nn as nn
from torch.autograd import Variable as V
line = nn.Linear(2, 4) # 输入2维,输出4维
line.weight # 参数是随机初始化的,维度为out_dim * in_dim
# 输出
Parameter containing:
0.6682 -0.2306
-0.3996 -0.5419
-0.1128 0.3110
0.5297 -0.3773
[torch.FloatTensor of size 4x2]
调用线性模型进行训练:
x = V(torch.randn(5,2)) # batch为5,即一次输入10个x
line(x) # 输出为batch*4
# 输出
Variable containing:
-0.2974 1.1781 -0.4070 -0.5863
-0.0696 1.2479 -0.5280 -0.3468
0.6763 -0.3509 -0.1926 -0.0852
0.7584 0.2388 -0.4621 0.1626
1.0948 0.6177 -0.7511 0.5952
[torch.FloatTensor of size 5x4]
RNN
RNN的简单表示:
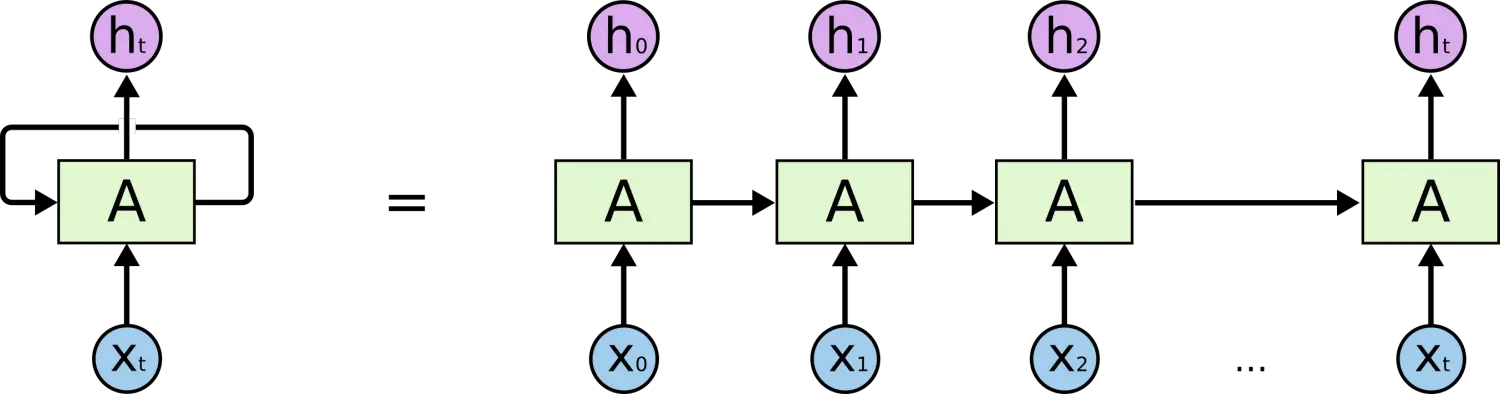
这里输入X一般是一个sequence,如[我 爱 北京 天安门],
x
1
x_1
x1=‘我’。
注意这里的
h
t
h_t
ht一般作为输出
y
t
y_t
yt。当然,你也可以再加上一层变化,令
y
t
=
f
(
h
t
)
y_t=f(h_t)
yt=f(ht)。
更专业的:

对于最简单的 RNN,我们可以使用下面两种方式去调用,分别是 torch.nn.RNNCell() 和 torch.nn.RNN(),这两种方式的区别在于 RNNCell() 只能接受序列中单步的输入,且必须传入隐藏状态,而 RNN() 可以接受一个序列的输入,默认会传入全 0 的隐藏状态,也可以自己申明隐藏状态传入。
-
RNN(input_dim ,hidden_dim ,num_layers ,…)
– input_dim 表示输入 x t x_t xt 的特征维度
– hidden_dim 表示输出的特征维度,如果没有特殊变化,相当于out
– num_layers 表示网络的层数
– nonlinearity 表示选用的非线性激活函数,默认是 ‘tanh’
– bias 表示是否使用偏置,默认使用
– batch_first 表示输入数据的形式,默认是 False,就是这样形式,(seq, batch, feature),也就是将序列长度放在第一位,batch 放在第二位
– dropout 表示是否在输出层应用 dropout
– bidirectional 表示是否使用双向的 rnn,默认是 False -
输入 x t x_t xt, h 0 h_0 h0,
– x t x_t xt[seq,batch,input_dim],
– h 0 h_0 h0[层数×方向,batch,h_dim] -
输出 h t h_t ht, output
– output[seq,batch,h_dim×方向]
– h t h_t ht[层数×方向,batch,h_dim]
公式为:
h
′
=
tanh
(
w
i
h
∗
x
+
b
i
h
+
w
h
h
∗
h
+
b
h
h
)
h' = \tanh(w_{ih} * x + b_{ih} + w_{hh} * h + b_{hh})
h′=tanh(wih∗x+bih+whh∗h+bhh)
代码:
# 构造RNN网络,x的维度5,隐层的维度10,网络的层数2
rnn_seq = nn.RNN(5, 10,2)
# 构造一个输入序列,长为 6,batch 是 3, 特征是 5
x = Variable(torch.randn(6, 3, 5))
out,ht = rnn_seq(x,h0) # h0可以指定或者不指定
# q1:这里out、ht的size是多少呢? out:6*3*10, ht:2*3*5
# q2:out[-1]和ht[-1]是否相等? 相等!
LSTM
LSTM 为了解决长期依赖问题,生生比基本的 RNN 多了三个非线性变化(共4个非线性变化)。见下图

注意共4个非线性变化。其中三个sigmoid变化分别对应的三个门:遗忘门f、输入门(当前状态)i、输出门o。这三个门的取值为[0,1],可以看做选择系数可以很好的控制信息的传导。
记t时刻的输出如下:遗忘门 f t f_t ft、输入门 i t i_t it、候选细胞状态 g t g_t gt、细胞状态 c t c_t ct、隐状态 h t h_t ht,分别对应5个非线性变换,但需要学习参数的只有四个, h t h_t ht不需要学习参数,所以在原图中有个tanh用红色椭圆表示。如图。
则有:
i
t
=
s
i
g
m
o
i
d
(
W
i
i
x
t
+
b
i
i
+
W
h
i
h
(
t
−
1
)
+
b
h
i
)
i_t = \mathrm{sigmoid}(W_{ii} x_t + b_{ii} + W_{hi} h_{(t-1)} + b_{hi})
it=sigmoid(Wiixt+bii+Whih(t−1)+bhi)
f
t
=
s
i
g
m
o
i
d
(
W
i
f
x
t
+
b
i
f
+
W
h
f
h
(
t
−
1
)
+
b
h
f
)
f_t = \mathrm{sigmoid}(W_{if} x_t + b_{if} + W_{hf} h_{(t-1)} + b_{hf})
ft=sigmoid(Wifxt+bif+Whfh(t−1)+bhf)
g
t
=
tanh
(
W
i
g
x
t
+
b
i
g
+
W
h
c
h
(
t
−
1
)
+
b
h
g
)
g_t = \tanh(W_{ig} x_t + b_{ig} + W_{hc} h_{(t-1)} + b_{hg})
gt=tanh(Wigxt+big+Whch(t−1)+bhg)
o
t
=
s
i
g
m
o
i
d
(
W
i
o
x
t
+
b
i
o
+
W
h
o
h
(
t
−
1
)
+
b
h
o
)
o_t = \mathrm{sigmoid}(W_{io} x_t + b_{io} + W_{ho} h_{(t-1)} + b_{ho})
ot=sigmoid(Wioxt+bio+Whoh(t−1)+bho)
c
t
=
f
t
∗
c
(
t
−
1
)
+
i
t
∗
g
t
c_t = f_t * c_{(t-1)} + i_t * g_t
ct=ft∗c(t−1)+it∗gt
h
t
=
o
t
∗
tanh
(
c
t
)
h_t = o_t * \tanh(c_t)
ht=ot∗tanh(ct)
注意:
- 输入有 x t x_t xt、 c t − 1 c_{t-1} ct−1、 h t − 1 h_{t-1} ht−1, 输出是 h t h_t ht和 c t c_t ct。
- 计算 c t c_t ct时,需要计算 f t 、 i t 和 g t f_t、i_t和g_t ft、it和gt(当前时刻的记忆状态);计算h_t时,需要o_t和c_t。
- 和输入相关的 W i h W_{ih} Wih和隐状态相关的 W h h W_{hh} Whh各有四个W要学习
在Pytorch中提供nn.LSTM类可以直接实现LSTM模型。
- LSTM(x_dim,h_dim,layer_num)
- 输入
x
t
x_t
xt,(
h
0
h_0
h0,$ c_0$)
– x t x_t xt(seq,batch,x_dim)
– ( h 0 h_0 h0,$ c_0$),为每个批次的每个x设置隐层状态和记忆单元的初值,其维度都是(num_layers * num_directions,batch,h_dim) - 输出output, (
h
n
h_n
hn,
c
n
c_n
cn)
– output,每个时刻的LSTM网络的最后一层的输出,维度(seq_len, batch, hidden_size * num_directions)
– ( h n h_n hn, c n c_n cn),最后时刻的隐层状态和基于单元状态,维度(num_layers * num_directions, batch, hidden_size)
上代码:
# 输入维度 50,隐层100维,两层
lstm_seq = nn.LSTM(50, 100, num_layers=2)
# 查看网络的权重,ih和hh,共2层,所以有四个要学习的参数
lstm_seq.weight_hh_l0.size(), lstm_seq.weight_hh_l1.size(),lstm_seq.weight_ih_l0.size(),lstm_seq.weight_ih_l1.size()
# q1: 输出的size是多少? 都是torch.Size([400, 100]
# 输入序列seq= 10,batch =3,输入维度=50
lstm_input = Variable(torch.randn(10, 3, 50))
out, (h, c) = lstm_seq(lstm_input) # 使用默认的全 0 隐藏状态
# q1:out和(h,c)的size各是多少?out:(10*3*100),(h,c):都是(2*3*100)
# q2:out[-1,:,:]和h[-1,:,:]相等吗? 相等
GRU
将忘记门和输入门合成了一个单一的 更新门,同样还混合了细胞状态和隐藏状态,只保留了隐藏状态。共三个非线性变化,两个衰减系数 r t r_t rt和 z t z_t zt。输入相关的 W i h W_{ih} Wih和隐状态相关的 W h h W_{hh} Whh各有三个W要学习。
总体看,最终的模型比标准的 LSTM 模型要简单一些,也是非常流行的变体。

具体的:
r
t
=
s
i
g
m
o
i
d
(
W
i
r
x
t
+
b
i
r
+
W
h
r
h
(
t
−
1
)
+
b
h
r
)
r_t = \mathrm{sigmoid}(W_{ir} x_t + b_{ir} + W_{hr} h_{(t-1)} + b_{hr})
rt=sigmoid(Wirxt+bir+Whrh(t−1)+bhr)
z
t
=
s
i
g
m
o
i
d
(
W
i
z
x
t
+
b
i
z
+
W
h
z
h
(
t
−
1
)
+
b
h
z
)
z_t = \mathrm{sigmoid}(W_{iz} x_t + b_{iz} + W_{hz} h_{(t-1)} + b_{hz})
zt=sigmoid(Wizxt+biz+Whzh(t−1)+bhz)
n
t
=
tanh
(
W
i
n
x
t
+
b
i
n
+
r
t
∗
(
W
h
n
h
(
t
−
1
)
+
b
h
n
)
)
n_t = \tanh(W_{in} x_t + b_{in} + r_t * (W_{hn} h_{(t-1)}+ b_{hn}))
nt=tanh(Winxt+bin+rt∗(Whnh(t−1)+bhn))
h
t
=
(
1
−
z
t
)
∗
n
t
+
z
t
∗
h
(
t
−
1
)
h_t = (1 - z_t) * n_t + z_t * h_{(t-1)}
ht=(1−zt)∗nt+zt∗h(t−1)
Pytorch中也提供了nn.GRU类。
- GRU(x_dim,h_dim,layer_num,…)
- 输入, x t x_t xt, h 0 h_0 h0, xt[seq,batch,x_dim],ho[层数×方向,batch,h_dim]
- 输出,out, h t h_t ht, out[seq,batch,h_dim方向], ht[层数方向,batch,h_dim]
上代码:
gru_seq = nn.GRU(10, 20,2) # x_dim,h_dim,layer_num
gru_input = Variable(torch.randn(3, 32, 10)) # seq,batch,x_dim
out, h = gru_seq(gru_input)
# q1: gru_seq的参数有多少个 ? 答案略^_^
# q2:输出h和out的维度是多少 ? 答案略^_^
参考:
【1】 pytorch官网help
【2】 https://www.jianshu.com/p/9dc9f41f0b29















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









