







pytorch使用-nn.RNN
一、nn.RNN 定义
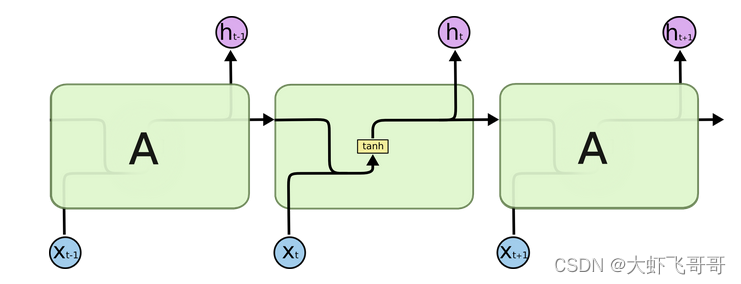
对于输入序列中的每个元素,每一层计算以下函数:
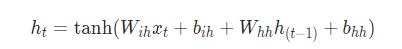
nn.RNN(input_size: int, hidden_size: int,
num_layers: int = 1, bias: bool = True, batch_first: bool = False,
dropout: float = 0., bidirectional: bool = False)
input_size: 输入特征的维度, 一般rnn中输入的是词向量,那么 input_size 就等于一个词向量的维度。
hidden_size: 隐藏层神经元个数,或者也叫输出的维度(因为rnn输出为各个时间步上的隐藏状态)。
num_layers:网络的层数。
nonlinearity:激活函数。
bias:是否使用偏置。
batch_first:输入数据的形式,默认是 False,就是这样形式,(seq(num_step), batch, input_dim),也就是将序列长度放在第一位,batch 放在第二位。
dropout:是否应用dropout, 默认不使用,如若使用将其设置成一个0-1的数字即可。
birdirectional:是否使用双向的 rnn,默认是 False。
二、nn.RNN 输入 input, h_0
input 形状:当设置 batch_first = False 时,
(
L
,
N
,
H
i
n
)
(L, N, H_{in})
(L,N,Hin) —— [时间步数, 批量大小, 特征维度]
当设置 batch_first = True时,
(
N
,
L
,
H
i
n
)
(N, L, H_{in})
(N,L,Hin)
当输入只有两个维度且 batch_size 为 1 时 : ( L , H i n ) (L, H_{in}) (L,Hin) 时,需要调用 torch.unsqueeze() 增加维度。
h_0 形状:
(
D
∗
n
u
m
_
l
a
y
e
r
s
,
N
,
H
o
u
t
)
(D * {num\_layers}, N, H_{out})
(D∗num_layers,N,Hout) , D 代表单向 RNN 还是双向 RNN。

三、nn.RNN 输出 output, h_n
output 形状:当设置 batch_first = False 时,
(
L
,
N
,
D
∗
H
o
u
t
)
(L, N, D * H_{out})
(L,N,D∗Hout) —— [时间步数, 批量大小, 隐藏单元个数];
当设置 batch_first = True 时,
(
N
,
L
,
D
∗
H
o
u
t
)
(N, L, D * H_{out})
(N,L,D∗Hout)。
h_n 形状: ( D ∗ num_layers , N , H o u t ) (D * \text{num\_layers}, N, H_{out}) (D∗num_layers,N,Hout)
四、测试
import torch
import torch.nn as nn
# 输入维度5, 隐藏层维度10, 一层网络
rnn = nn.RNN(5, 10, 1)
# 初始化 input - one_hot 编码, 时间步数=2, batch_size=1, input_size=5,
input = torch.tensor([[0, 1, 0, 0, 0],
[0, 0, 0, 1, 0]], dtype=torch.float32)
print(input.size())
# 扩展 batch_size 维度为 1
input = input.unsqueeze(1)
print("输入维度")
print(input.size())
# 初始化 h_0 - (D, N, H_out)
hidden = torch.randn(1, 1, 10)
print(hidden.size())
# 调用 rnn
output, h_n = rnn(input, hidden)
print("输出维度")
print(output.size())
print(h_n.size())

五、RNN 网络
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(RNN, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input_data, hidden):
input_data = input_data.unsqueeze(0)
rr, hn = self.rnn(input_data, hidden)
return self.softmax(self.linear(rr)), hn
def init_hidden(self):
return torch.zeros(self.num_layers, 1, self.hidden_size)
















 9426
9426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











