




网站:
LLM Visualization (bbycroft.net)
学神经网络时,经常觉得很难理解卷积层之间是如何相互连接,又如何与不同类型的层连接的。
而该工具的主要功能包括,卷积、最大池化和完全连接层的可视化表示,以及各种能实现更清晰可视化的简化机制等等。让初学者通过最直观的方式,来get到CNN的重点。
LLM的核心能力大致分为六部分:
生成(Generate)、
总结(Summarize)、
提取(Extract)、
分类(Classify)、
检索(Search)与改写(Rewrite)。
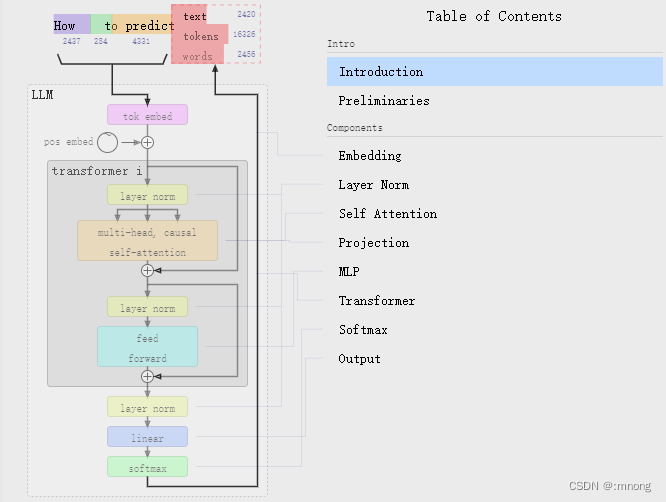
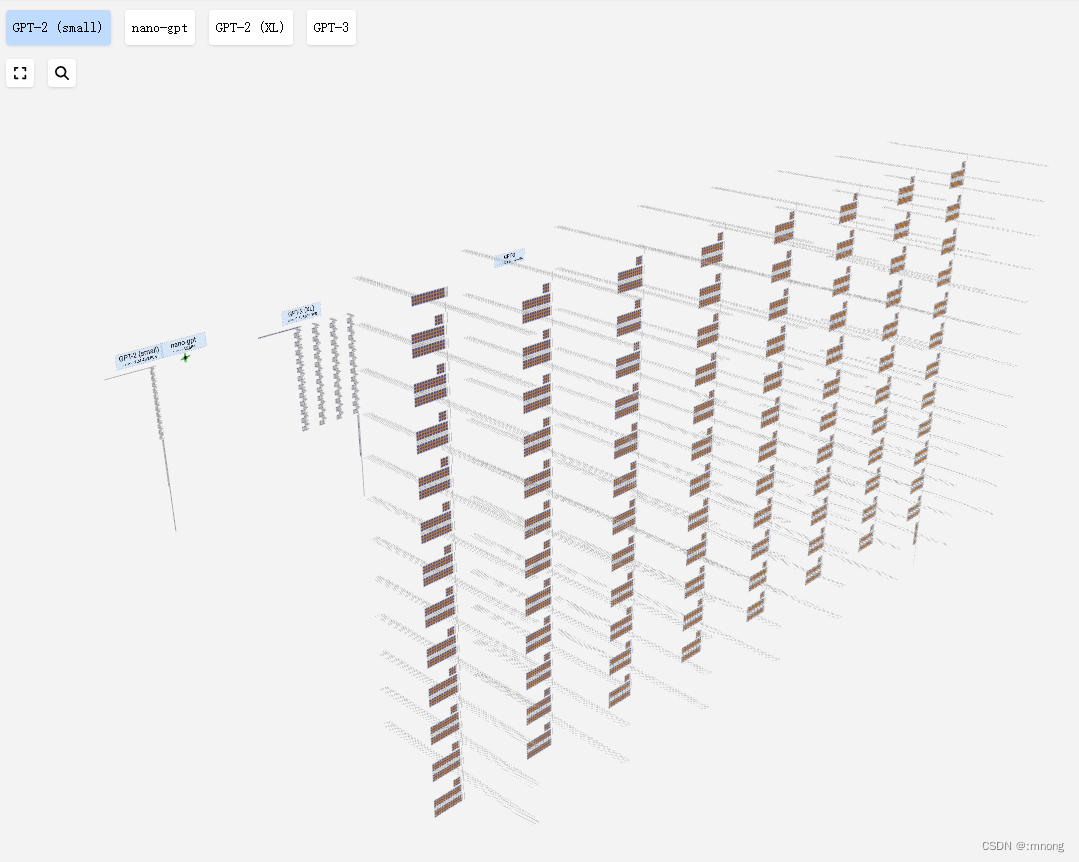
随着epoch(迭代次数)的变化,训练过程中各层出现的实时变化。
还可以在其中自由地折叠、扩展每个层。
比如将特征图在线性布局和网格布局之间转换。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











