







参考:https://www.bilibili.com/video/BV15w411Z7LG?p=4&vd_source=de203b26ba8599fca1d56a5ac83a051c
一、计算视觉解决的问题
主要可以解决:Classification(分类),Localization(定位),Object Detection(目标检测),Segmentation(分割)。
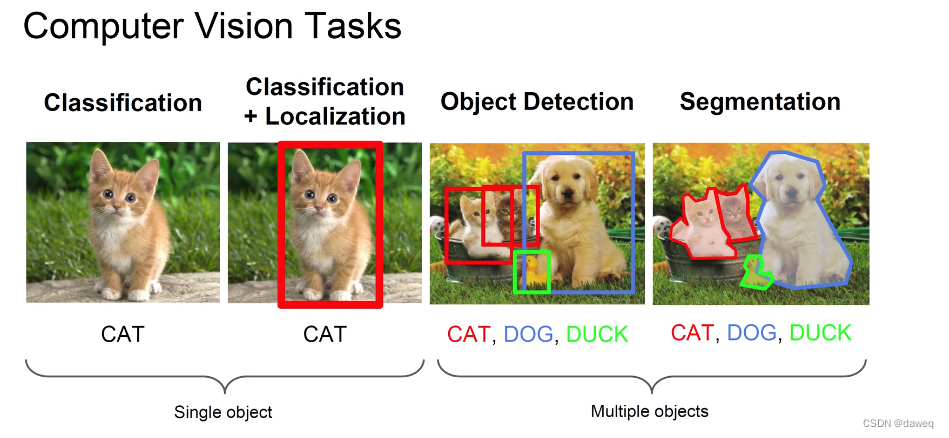
其中分割任务又分为Semantic Segmentation(语义分割),Instance Segmentation(实例分割)。

二、YOLO对于传统模型的优点
(1)无需提取候选区域
(2)无复杂的上下游处理工作
(3)端到端的训练优化
(4)一次前项推断得到bbox定位及分类结果,所以YOLO是单阶段模型。
三、YOLOV1目标检测算法
理解YOLOV1目标检测算法的核心在于:分清预测和训练阶段。
(1)网络结构
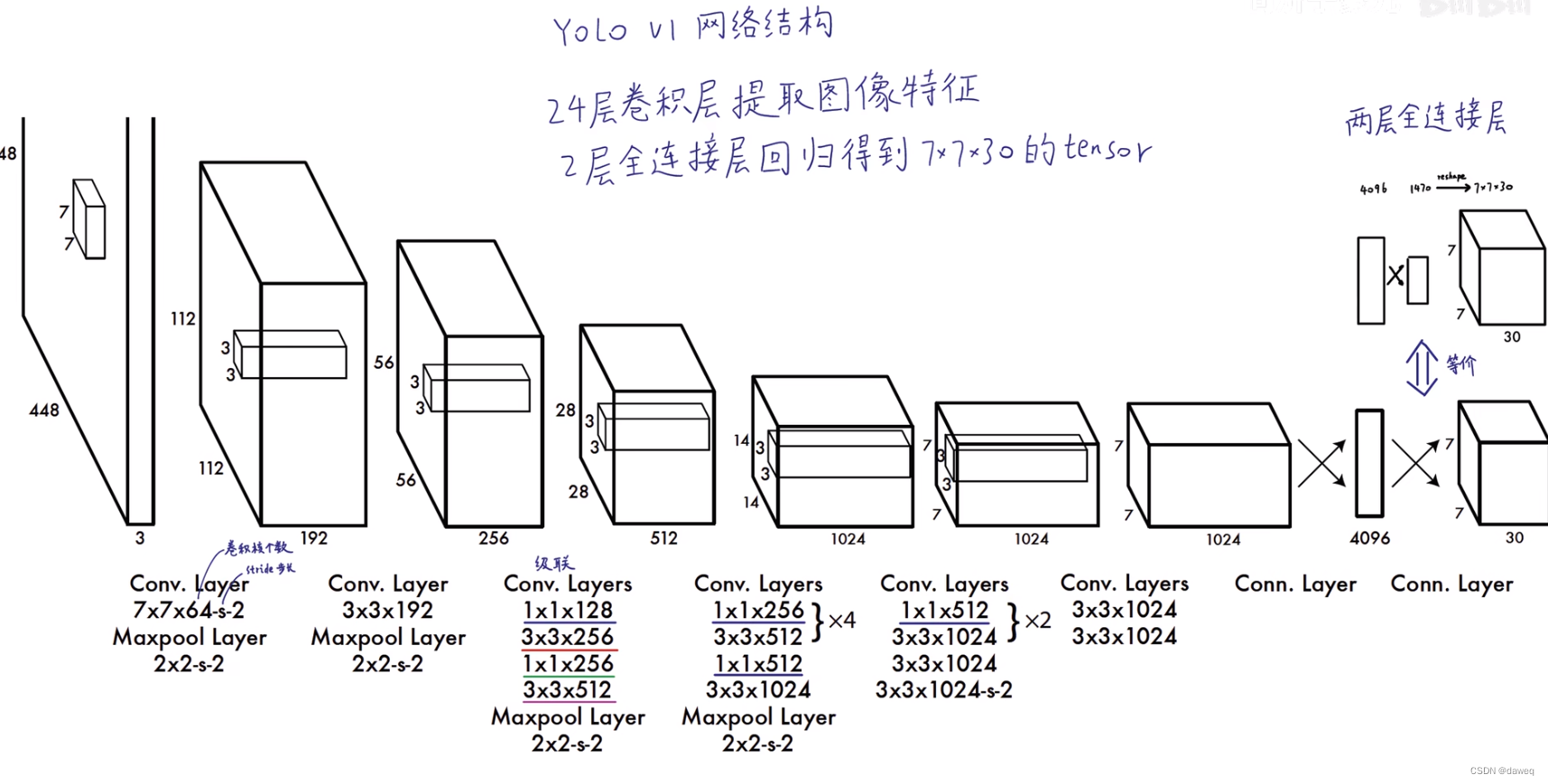
YOLO网络首先需要将输入图片缩放至448x448x3的大小,再通过一系列的卷积,池化,全连接层,最终得到7x7x30的块。这里可以粗略的将模型理解成黑盒子,也就是暂时不关心盒子内部具体的网络结构,只需要知道我们输入一张符合要求的图片,最终可以得到一个7x7x30大小的矩阵的就可以了。
(2)YOLO网络是如何预测的
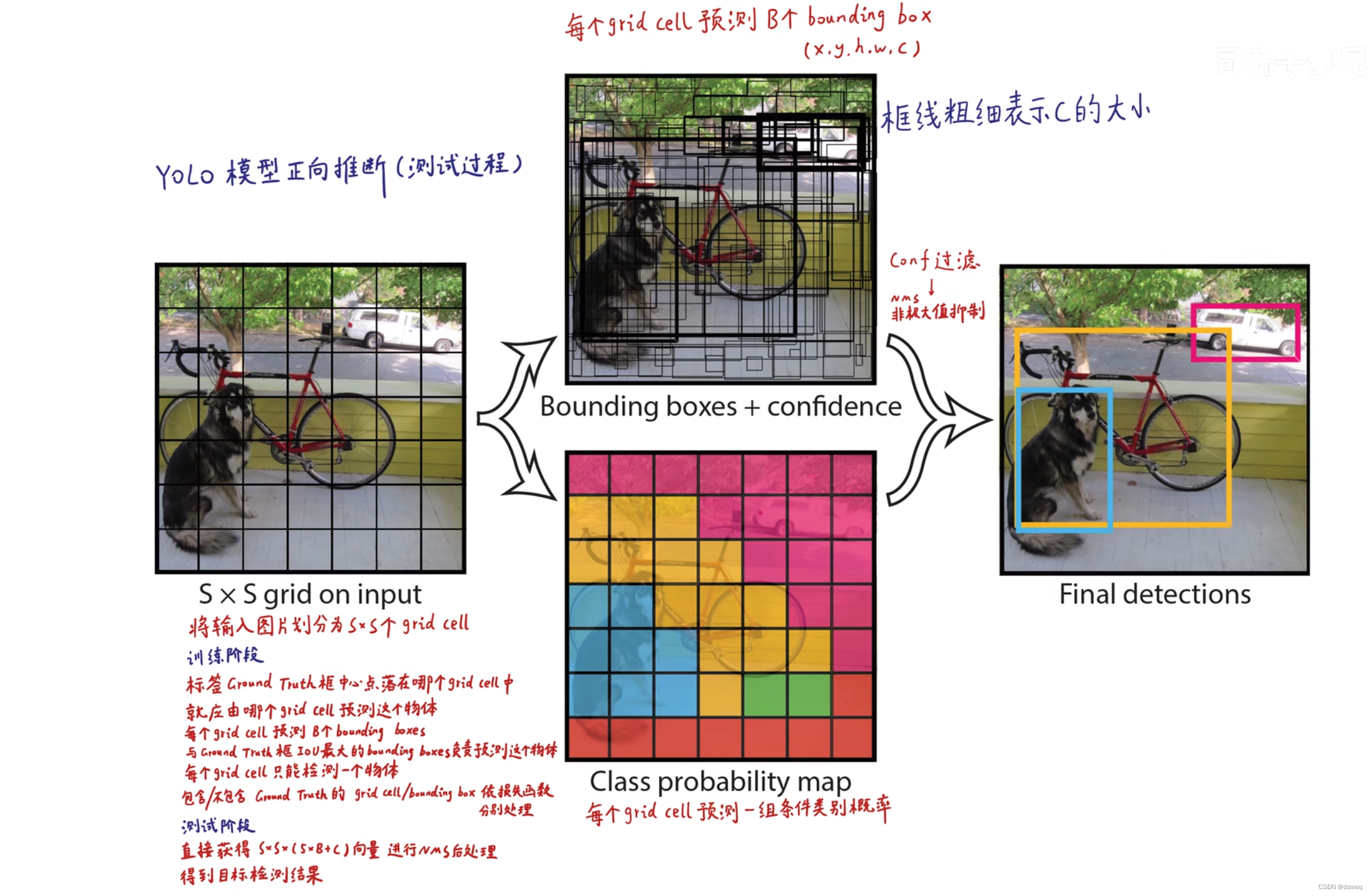
YOLO网络最终要完成的任务是定位+分类。
首先我们来阐述在预测阶段,是怎么对黑盒网络生成的7x7x30的矩阵进行处理的。
①7*7代表我们最终将图片分割为7x7也就是49个方块(如左图所示)。
②一个方块我们叫做Grid cell(网络单元)。
③每一个Grid cell将会预测2个Bounding box(边界框)。每一个边界框需要由4个变量进行定位。
④每一个边界框,都自带置信度,可视化中通过线的粗细来表示。
最终生成的就是如中间上图所示的情况(可视化)。
而每一个Grid cell都还要自带对20种分类结果的可能性大小(类似于回归中的概率大小)。
最终我们可以算出来,一个Grid cell需要有2x5+20=30个变量去定义。
所以这也就是最终输出的7x7x30的矩阵中每一个元素的含义。
(3)预测阶段的后处理
从上述的预测中,我们可以知道,最终我们可以得到98个不同置信度,不同类别的BBox,所以我们最终的任务就是挑选出最好的BBox,删除其他不需要的BBox。所以在预测阶段的后处理中,我们主要进行NMS(非极大值抑制)
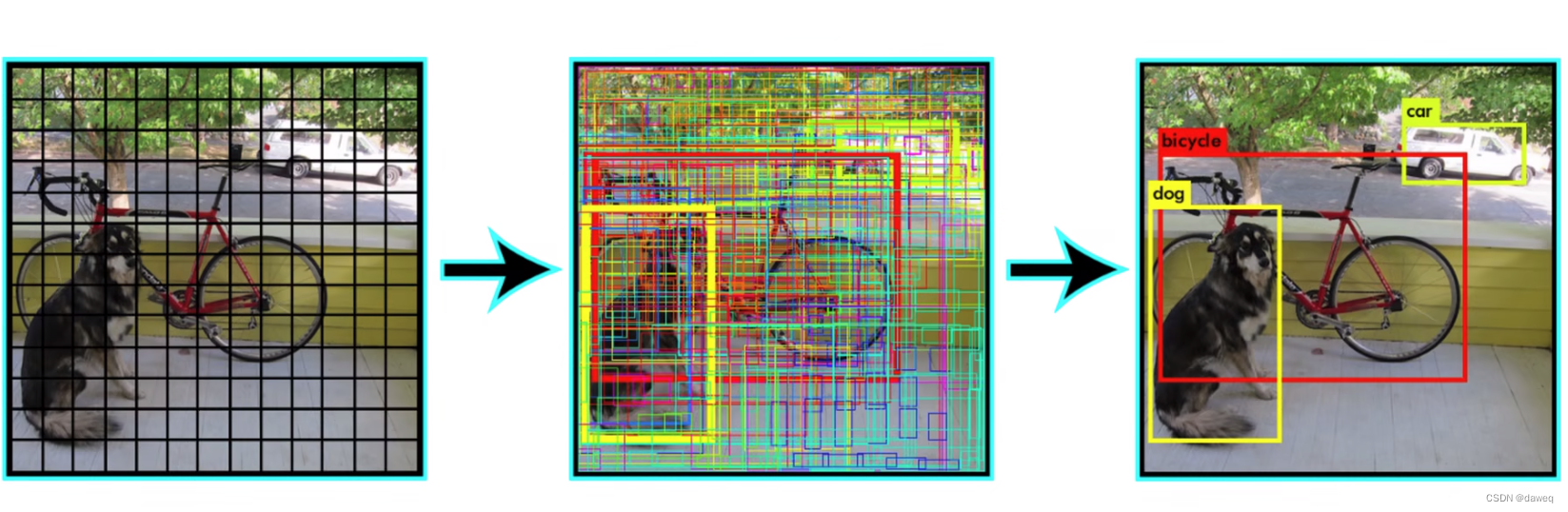
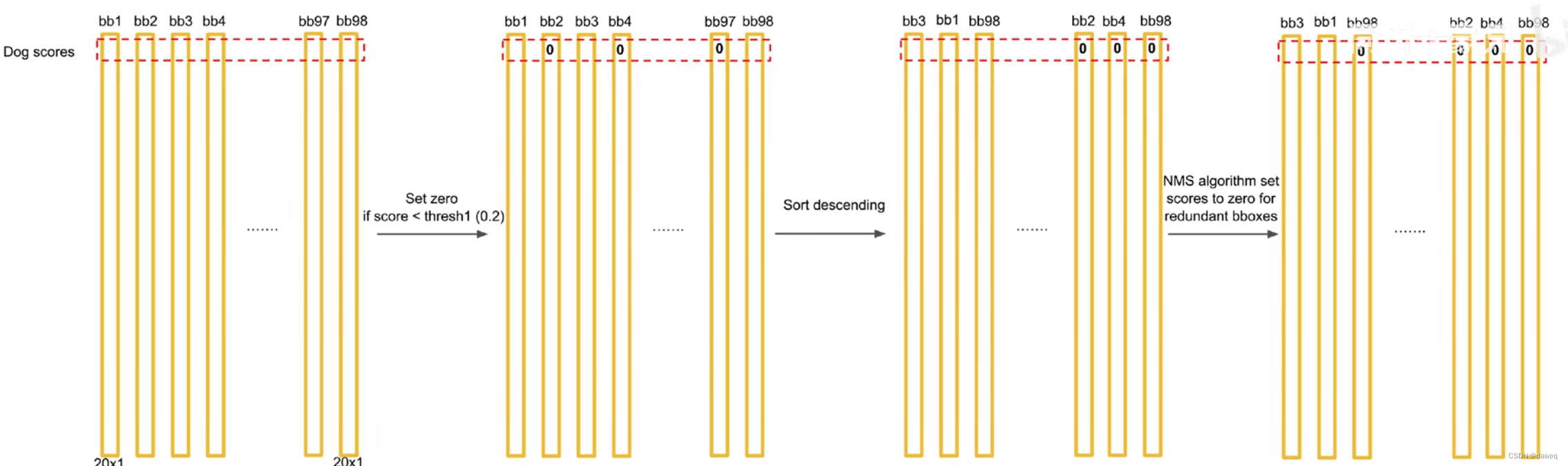
上图主要介绍了整个过程,首先我们将负责处理概率的部分拿出来,也就是有98个竖条,分别代表98个BBox,每个BBox中有20个标签的概率。我们要进行如下几步操作:
①设定阈值,将低于阈值的概率置0。
②从高到低排序
③非极大值抑制。

以上图为例,介绍非极大值抑制的过程。
首先将第一大概率和第二大概率的BBox进行IOU对比。IOU的全称为交并比(Intersection overUnion)。如果最后的结果大于某个阈值,我们就认为,这两个BBOX识别了一个物体,这个时候我们就将低置信度的BBox的概率置0。
将第一名和后续所有的对比一轮。再将第二个不为零的与后续的所有进行对比,以此类推。这样就可以得到所有的结果。当然这是对一个类别的操作。
我们需要将所有类别都进行这样的对比,这样最后得到了一个大的稀疏矩阵,将得到的结果可视化就能得到最后的定位和分类的结果。
**这个故事告诉我们的道理是: **
①我们要有实力,才能在挑选中幸存下来。
②很多情况下,都是赢者通吃。
③不要动别人的蛋糕太多,否则会被更有实力的人吃掉。
(4)YOLOV1是如何训练模型的
在传统深度学习中,训练模型的过程就是使用梯度下降和反向传播方法,不停的迭代网络中的神经元,最终不停的降低损失函数的过程。YOLOV1也是类似的,我们需要有一些已经被分类和定位的图片进行训练。

首先上图中的绿框(gound truth)有一个中心点,而由上面的论述可以知道,一个GC会生成两个BBox,所以要做的就是用这两个BBox中的一个去尽量的拟合这个已经确定好的绿框。而用哪一个BBox去拟合gound truth,这也要用到IOU交并比。这里值得注意的是,剩下的框(这里包含没有被选中的BBox,也包含那些没有被gound truth选中GC所生成的两个BBox)均不会参与预测,但是这并不意味着这些框没有作用,这些框会在损失函数中参与运算。
当然每一个框也包含了这个框所预测物体的标签,所以一个图片中最多能被预测7x7=49个物体,这也是YOLOV1的一些弊端,也就是没法很精准的预测很多小的物体。
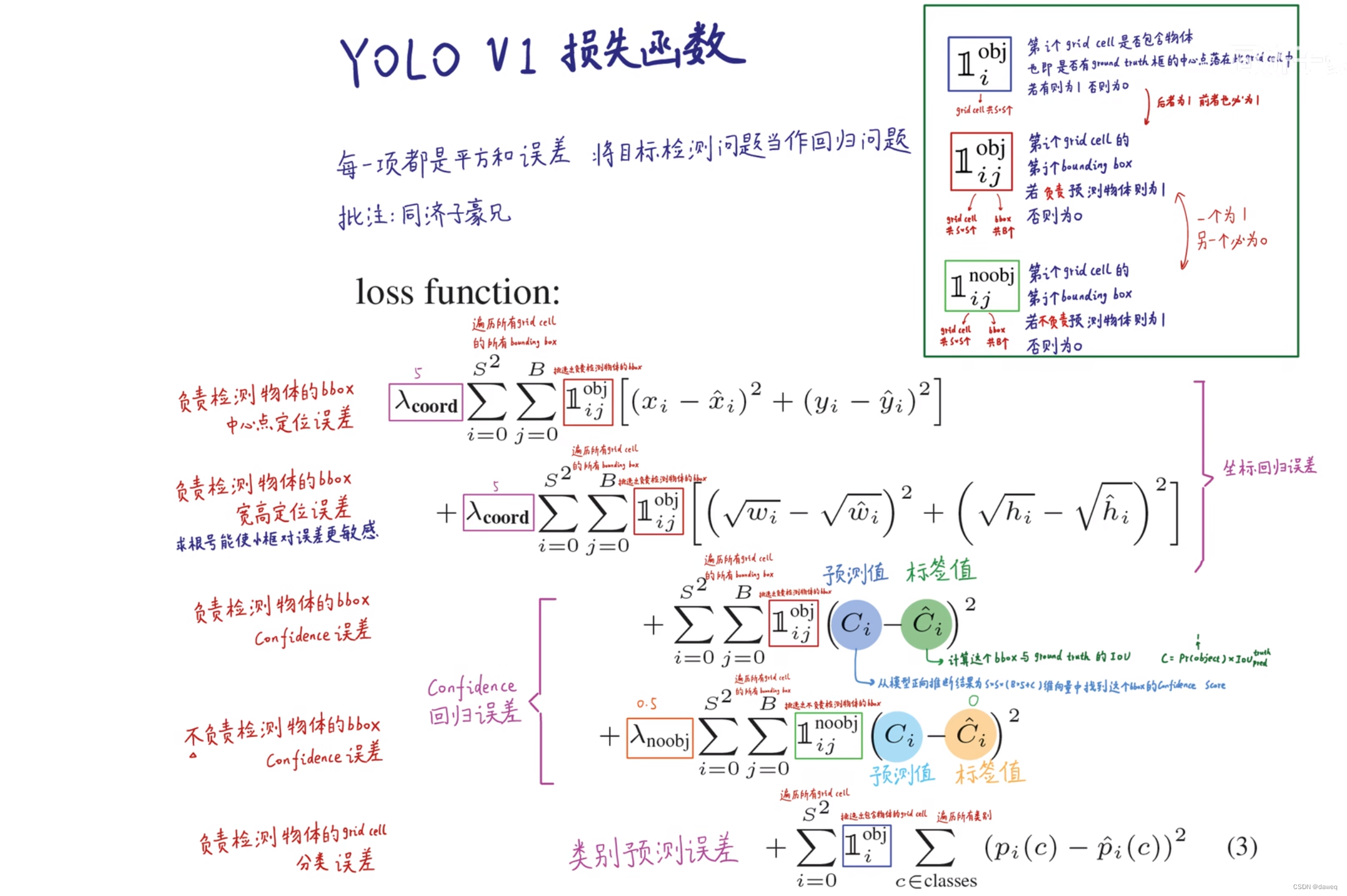
如上图所示,YOLOV1的训练误差函数由五块组成,分别是:
①负责检测物体的BBOX的中心点定位误差。
②负责检测物体的BBOX的宽高定位误差。
③负责检测物体的BBOX的Confidence误差。
④不负责检测物体的BBOX的Confidence误差。
⑤负责检测物体的GC的分类误差。
具体的就不仔细解释了。这里有两个简单逻辑,负责检测物体的BBOX,它对应的GC也是负责检测物体的。一个BBOX负责检测物体,则它对应的另一个BBOX就不负责检测物体。
四、YOLOV1的一些问题
在YOLOV1中有一些显而易见的问题,比如:
(1)为什么一个GC要设定两个BBOX,如果只设定一个BBOX,然后让他去拟合gound truth不就行了吗?
(2)在预测阶段中,最初始的框是怎么生成的?
……
这些问题都将在YOLOV2中得到解释。















 7818
7818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









