






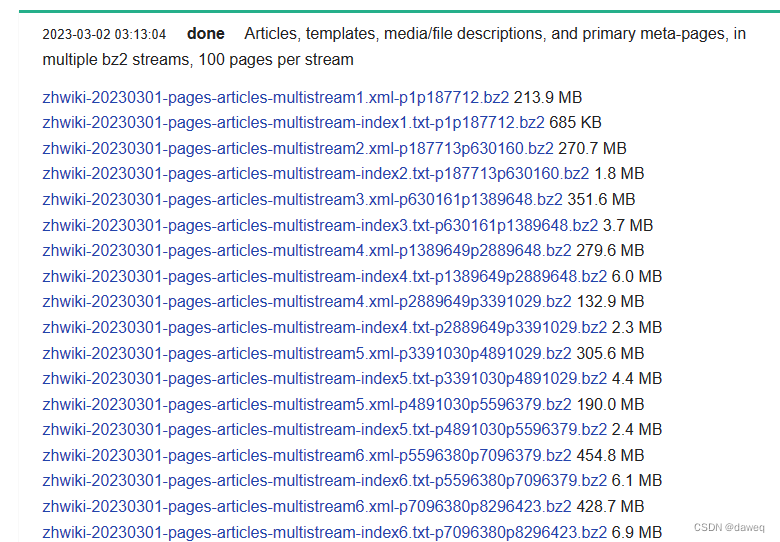
一、获取语料
https://dumps.wikimedia.org/zhwiki/20230301/
二、xml转txt
import logging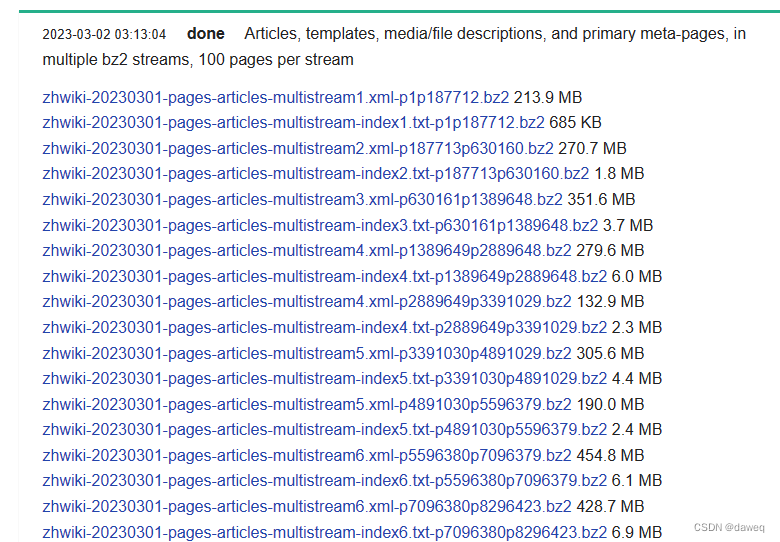
import os.path
import sys
from gensim.corpora import WikiCorpus
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) != 3:
print("Using: python process_wiki.py enwiki.xxx.xml.bz2 wiki.en.text")
sys.exit(1)
inp, outp = sys.argv[1:3]
space = " "
i = 0
output = open(outp, 'w',encoding='utf-8')
wiki = WikiCorpus(inp, dictionary={})
for text in wiki.get_texts():
S=space.join(text)
S=S.encode('utf8').decode('utf8') + "\n"
output.write(S)
i = i+1
if(i%10000==0):
logger.info("Saved"+str(i)+"articles")
output.close()
logger.info("Finished Saved"+str(i)+"articlesconda act")

三、使用opencc将繁体数据转换为简体中文数据
使用Opencc,直接将数据转为简中。
四、jieba进行分词
import jieba
import jieba.analyse
import jieba.posseg as pseg
import codecs,sys
def cut_words(sentence):
return " ".join(jieba.cut(sentence)).encode('utf-8')
f=codecs.open('test.txt','r',encoding="utf8")
target = codecs.open("test_result.txt","w",encoding="utf8")
print('open files')
line_num=1
line=f.readline()
while line:
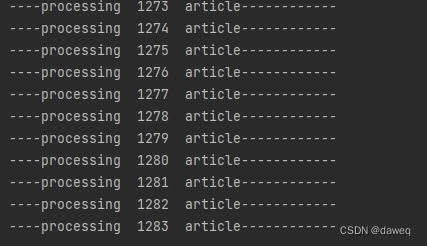
print('----processing ',line_num,' article------------')
line_seg = " ".join(jieba.cut(line))
target.writelines(line_seg)
line_num = line_num+1
line =f.readline()
f.close()
target.close()
exit()

五、构造word2vec模型
import logging
import os.path
import sys
import multiprocessing
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
if len(sys.argv) < 4:
print (globals()['__doc__'], locals())
sys.exit(1)
inp, outp1, outp2 = sys.argv[1:4]
model = Word2Vec(LineSentence(inp), vector_size=1000, window=5, min_count=5, workers=multiprocessing.cpu_count())
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)

六、相似度测试
from gensim.models import Word2Vec
en_wiki_word2vec_model = Word2Vec.load('wiki.test_result.test.model')
testwords = ['可爱','苹果','英语口语','伙伴','朋友']
for i in range(5):
res = en_wiki_word2vec_model.wv.most_similar(testwords[i])
print(testwords[i])
print(res)
















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









