






记得还是在上半年的程序员中看到有关CUDA的介绍,一直零零星星看了些介绍,没时间仔细去验证,这段时间捡起来研究一番,闲言碎语不多表,切入正题
先做下广告,什么是CUDA,CUDA(Compute Unified Device Architecture),是英伟达公司为下一代大规模并行计算提供的统一计算框架
为什么使用CUDA,很简单,由于现在CPU主频已经遇到了明显的瓶颈,45nm制程已经是公认的极限,要想再提高主频要付出很大的代价,而同时现代的显示晶片已经具有高度的可程式化能力,由于显示晶片通常具有相当高的记忆体频宽,以及大量的执行单元,因此开始有利用显示晶片来帮助进行一些计算工作的想法,即GPGPU。CUDA即是NVIDIA的GPGPU模型.而显卡的工作原理就是通过增加SP的数量来应对大规模的数据运算,新的NVGTX280拥有240个主频为1.5GHz的SP。其实说简单点CUDA的取胜秘诀就是三个臭皮匠顶一个诸葛亮,是一种空间换时间的方法,以下一个图标足以说明问题:
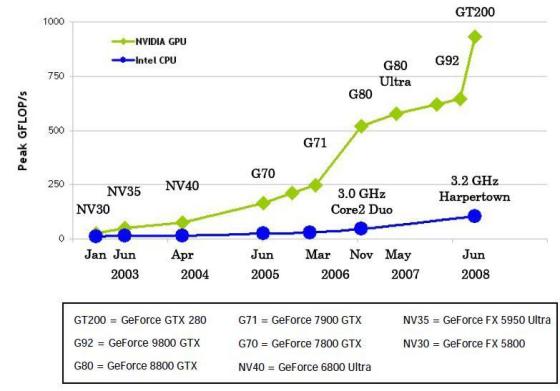 图标上为现实的GTX280的浮点运算能力已经轻松突破1.008TFLOPs,而双黄的酷睿爬到100GPFLOPS已经是相当吃力了,也许你要说浮点运算不能说明问题,问题计算所体现出的速度包括主频,频宽,流水线处理,缓存等多方面作用的结果,的确intel大哥已经把CPU已经把缓存和CPU配合到极致的程度,但是毕竟双拳难敌四手,那么就用事实说话:
图标上为现实的GTX280的浮点运算能力已经轻松突破1.008TFLOPs,而双黄的酷睿爬到100GPFLOPS已经是相当吃力了,也许你要说浮点运算不能说明问题,问题计算所体现出的速度包括主频,频宽,流水线处理,缓存等多方面作用的结果,的确intel大哥已经把CPU已经把缓存和CPU配合到极致的程度,但是毕竟双拳难敌四手,那么就用事实说话:
我是我自己dell(XPS1530)做为试验机:配置如下:
GPU GeForce 8600M GT 流处理器数目32,主频950MHz
CPU intel core2 T7500 2.0~2.2GHz
测试科目很简单将12484800个随机整形数字求平方和,以下是运行结果
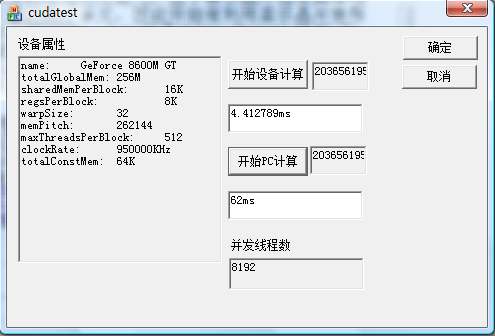 GPU共启动8192个线程耗时4.412789ms完成,CPU耗时62ms,GPU超过CPU14倍之多
GPU共启动8192个线程耗时4.412789ms完成,CPU耗时62ms,GPU超过CPU14倍之多
这里也许你会不明白为什么会有那么多线程,其实这也正是CUDA的特点海量并行,用并行和弥补流水线和缓存的先天不足,用CUDA计算只有将线程在这个数量级上才可以发挥作用,而这个GF8600GT的浮点运算能力仅为91.200GFLOPS,如果换成GTX280这般猛兽会是什么结果。。。。















 2555
2555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









