







1. 什么是大模型幻觉?
在语言模型的背景下,幻觉指的是一本正经的胡说八道:看似流畅自然的表述,实则不符合事实或者是错误的。
2. 为什么需要解决LLM的幻觉问题?
LLMs的幻觉可能会产生如传播错误信息或侵犯隐私等严重后果。 比如在医疗应用中,对患者生成的报告如果存在幻觉可能导致错误诊断甚至影响生命安全。
幻觉影响了模型的可靠性和可信度,因此需要解决LLM的幻觉问题。
3. 幻觉一定是有害的吗?
幻觉不一定是有害的,特别是在一些需要创造力或灵感的场合,比如写电影剧情,幻觉的存在可能带来一些奇思妙想,使得生成的文本充满想象力。
因此,对幻觉的容忍度取决于具体的应用场景。
4. 幻觉有哪些不同类型?
1.1 事实性问题(Factuality)
- 事实性错误:模型回答与事实不一致
- 事实性虚构:模型回答在真实世界无法考证
1.2 忠诚度问题(Faithfulness)
- 违背指令:模型回答没有遵从指令
- 违背上文:模型回答和上下文内容存在不一致
1.3 自我矛盾(self-Contradiction)
- 模型回答内部问题存在逻辑矛盾,比如COT多步推理之间存在矛盾
5. 为什么LLM会产生幻觉?
有一些研究也在致力于分析幻觉出现的不同原因,已知的一些原因包括:
- 源与目标的差异:当我们在存在源与目标差异的数据上训练模型时,模型产生的文本可能与原始源内容产生偏差。这种差异,有时可能是在数据收集过程中不经意间产生的,有时则是故意为之;
- 无意识的源-目标差异:这种差异的产生有多种原因。例如,数据可能是基于某种经验法则编制的,使得目标信息并不总是完全依赖源信息。举例来说,如果从两家不同的新闻网站获得相同事件的报道作为源与目标,目标报道中可能包含源报道没有的信息,从而导致二者不同;
- 有意识的源-目标差异:某些任务在本质上并不追求源与目标的严格一致,尤其是在需要多样性输出的情境下;
- 训练数据的重复性:训练过程中使用的数据,如果存在大量重复,可能导致模型在生成时过于偏好某些高频短语,这也可能引发“幻觉”;
- 数据噪声的影响:使用充斥噪声的数据进行训练,往往是导致“幻觉”出现的关键因素之一;
- 解码过程中的随机性:某些旨在增加输出多样性的解码策略,如top-k采样、top-p方法以及温度调节,有时会增加“幻觉”的产生。这往往是因为模型在选择输出词汇时引入了随机性,而没有始终选择最可能的词汇;
- 模型的参数知识偏向:有研究表明,模型在处理信息时,可能更依赖其在预训练阶段所积累的知识,而忽略了实时提供的上下文信息,从而偏离了正确的输出路径;
- 训练与实际应用中的解码差异:在常见的训练方法中,我们鼓励模型基于真实数据预测下一个词汇。但在实际应用中,模型则是根据自己先前生成的内容进行预测。这种方法上的差异,尤其在处理长文本时,可能会导致模型的输出出现“幻觉”。
最后,如GPT之类的生成模型,其实只是学会了文本中词汇间的统计规律,所以它们生成内容的准确性仍然是有限的。
6. 如何度量幻觉?
最有效可靠的方式当然是靠人来评估,但是人工评估的成本太高了。因此有了一些自动化评估的指标:
- 命名实体误差:命名实体(NEs)是“事实”描述的关键组成部分,我们可以利用NE匹配来计算生成文本与参考资料之间的一致性。直观上,如果一个模型生成了不在原始知识源中的NE,那么它可以被视为产生了幻觉(或者说,有事实上的错误);
- 蕴含率:该指标定义为被参考文本所蕴含的句子数量与生成输出中的总句子数量的比例。为了实现这一点,可以采用成熟的蕴含/NLI模型;
- 基于模型的评估:应对复杂的句法和语义变化;
- 利用问答系统:此方法的思路是,如果生成的文本在事实上与参考材料一致,那么对同一个问题,其答案应该与参考材料相似。具体而言,对于给定的生成文本,问题生成模型会创建一组问题-答案对。接下来,问答模型将使用原始的参考文本来回答这些问题,并计算所得答案的相似性;
- 利用信息提取系统:此方法使用信息提取模型将知识简化为关系元组,例如<主体,关系,对象>。这些模型从生成的文本中提取此类元组,并与从原始材料中提取的元组进行比较。
7. 幻觉如何检测?
7.1 事实性检测
(1)外部检索增强
基于外部工具调用,例如搜索引擎检索获得的结果来检查模型回答是否存在幻觉。
(2)模型回答的不确定性
- 需要获得模型参数:依赖回答的熵值(不确定性)来判断模型对问题是否可能存在幻觉。
- 无需获得模型参数:使用随机采样多次回答,或者对模型回答进行二次提问的方案判断模型多次回答之间是否存在不一致性。
7.2 忠诚度检测
(1)事实重叠
ngram:判断上文和模型回答间ngram的重合度例如ROUGE,但考虑模型生成的多样性,这个指标可用率较低实体:适用于摘要任务,计算回答和上文之间实体的重合度实体关系:同样适用于摘要任务,抽取实体和关系三元组,判断三元组在回答和上文之间的重合度知识:依赖知识标注才能计算回答和上文间知识的重合度
(2)分类任务
- NLI任务:直接使用NLI模型判断模型生成的回答是否可以被上文所support(entailment)
- 模型微调:使用规则或扰动构建弱监督数据直接训练一个忠诚度判别模型用于检测
(3)QA任务
从模型回答中抽取多个事实,构建针对事实的问题,并基于同样的上文进行QA问答,通过对比QA结果和模型回答的重合度来判断模型是否幻觉
(4)不确定性
Entropy:基于上文使用回答的条件熵值来判断模型回答的不确定性LogProb:基于回答长度标准化的序列概率来评估模型回答的置信程度相似度:使用模型多次回答之间的相似程度来判断模型的置信度
(5)大模型Prompt
直接使用指令让大模型来评估回答是否遵从于上文
8. 幻觉的来源
8.1 来自数据的幻觉
(1)数据源缺陷
数据编码是在预训练阶段把训练数据源内化压缩到模型参数中的过程,而压缩过程中训练数据的问题同样会被模型错误的学习和模仿。
数据有误
- 错误模仿:错误训练数据会注入错误知识,例如网络热梗
- 重复偏差:重复的寻来你数据会导致模型对部分数据过度训练(记忆),例如过采样拒绝回答的样本,问啥模型都回答“对不起”
- 社会偏见:训练数据自带社会偏见,如人种歧视,性别歧视
知识边界
- 领域知识匮乏:如金融、医药等领域知识
- 知识过时未更新
(2)数据利用缺陷
数据利用,既知识召回可以类比Query-Document检索,模型把指令映射成任务向量,去模型参数中召回相应的知识用来回答问题,召回错误或者召回失败,模型的回答就会存在幻觉。
召回取巧错误
- 倾向于召回训练样本中距离近的内容,模型压缩不充分会误把相关当因果
- 倾向于召回预训练共现频率高的知识,模型压缩不充分只会停留在表层语法结构
- 倾向于召回预训练阶段出现频率更高的额外知识,知识的置信度会和训练程度相关
召回失败
- 长尾知识:因为长尾知识在预训练中往往学习不充分,知识压缩效果差
- 复杂场景:当指令过于复杂需要模型推理时,模型召回知识会存在失败
8.2 来自训练的幻觉
(1)预训练
- 训练架构:缺乏双向编码带来的双向信息;注意力机制的问题,例如长程衰减等。
- 训练策略:训练时teacher-force策略和推理策略的不一致性
(2)偏好对齐问题
- 能力对齐:因为指令微调样本的知识部分超出预训练知识的范畴,导致微调过程错误引导模型回答本身压缩知识范围之外的问题,从而加重了模型幻觉。
- 置信度对齐:RLHF的偏好对齐可能会改变模型本身对答案的置信度,导致模型变得阿谀奉承,即便回答正确,如果用户表示反对模型也会自我修正。
8.3 来自推理的幻觉
(1)随机解码的固有问题
虽然随机解码可以缓解greedy解码整个文本质量较差的问题,但同时引入了不确定性。多样性越高,幻觉概率也会相对提高。
(2)解码过程信息损失
注意力机制的长程衰减会导致模型随着解码逐渐降低对指令上文的注意从而产生幻觉。
输出层的softmax layer是token在整个词典的分布,而仅依赖连续token的概率分布序列,可能无法完全表征自然语言的复杂性导致softmax bottleneck。
(3)解码过程的错误累计
如果前面推理的内容存在错误,模型倾向于在只一后面的解码中延续错误而非修正错误,导致越来越离谱。
9. 如何缓解LLM幻觉?
9.1 数据幻觉
(1)缓解数据错误和偏见
降低错误
- 高质量低事实错误的预训练数据集构建,有通过规则筛选高质量web数据源,有通过模型对数据进行过滤
降低偏见
- 重复偏见:使用SimHash、SemDeDup等消重技术对预训练数据进行消重
- 社会偏见:通过检验并筛选更多样,平衡的预训练语料,能想到的就是更全面的数据打标和采样策略
(2)缓解知识边界
模型编辑Model Edit
- 修改内部参数:直接修改模型参数进行知识修改的黑科技,先定位知识在参数中的位置再进行修改,例如ROME,MEMIT
- 增加外部参数:通过外接模型或外接层,来进行知识判断和补充知识存储,不过知识范围的判断难度很高泛化性可能不好,方法有SERAC,T-Patcher, NKB等
检索增强RAG
- 单次检索:传统Retrieve-then-Read
- 链式检索:适用多步问答例如当日成交量最高的板块换手率是多少代表有Self-ask,React
- 检索后处理:和以上流程不同,先让模型回答再进行检索然后对回答进行编辑,在复杂问题检索效果较差的场景有更好的效果,代表有RARR,PURR,CRITIC,LLM-Augmenter等
(3)缓解知识召回问题
- 召回取巧:可以通过对训练数据中知识共现等导致知识召回有偏差的样本进行过滤,不过方法泛化性和效果都相对有限
- 召回失败:提高知识召回率,就像query-Document召回里面提高query的短文本召回一样,可以使用Chain-of-Thought等方案来提升Query上下文
9.2 训练幻觉
(1)预训练问题
- 注意力机制:双向注意力改良的模型架构BATGPT
- 预训练策略:Attention-shapening正则器,通过把self-attention进行稀疏化正则处理,降低soft-attention向前传递的误差,类似L1正则
(2)对齐问题
- 缓解SFT和预训练知识差异的方法,可以对SFT样本中模型可能不确定的知识进行样本调整允许模型表达怀疑和拒绝,代表有R-tuning,不过这类方法的泛化性可能不及RLHF
- 缓解RLHF带来的模型阿谀奉承,可以通过优化RL的标注数据实现,要么使用大模型辅助人工达标,要么使用多人标注降低标注偏差
9.3 推理幻觉
(1)事实性增强解码
解码策略
factual-nucleus:随着解码逐渐衰减top-p的p值,在保证生成通顺度的前提下,降低事实性的随机度。算是top-p和Greedy解码的折中版本Inference-time-intervention:通过干预多头注意力机制中和事实性最相关的Top-K个Head的激活函数输出,引导模型解码更加真实DOLA:基于transformer不同层之间的残差连接,输出层的信息是依赖中间层逐级演化得到的,通过对比底层和高层对下一个token的预测概率分布的差异来进行解码,强调高层知识淡化低层知识
后处理策略
Chain-of-Verification:利用模型自我修正能力,先让模型生成答案,再使用prompt让模型对答案进行多角度的校验提问,并回答这些提问,最后基于以上回答修正初始答案。Self-Reflection:先让模型生成答案,再使用prompt让模型对答案进行反思,多轮迭代直到回答一致
(2)忠诚度增强解码
Context-aware Decode:每个token的解码概率由基于上文的条件解码概率,和不基于上文的无条件解码概率的边际差异决定,降低模型内化知识的影响提高上文的影响KL-guided-sampling:以上CAD的动态优化版本,基于无条件解码和条件解码的KL距离来动态调整P值,这里距离反映上文对模型推理的影响程度。算是CAD和top-p的折中版本Contrastive-Decoding:一个大模型和一个小模型进行同步解码,先用大模型的top-p/k作为候选token,再使用小模型生成的token概率分布作为“噪声分布”,从大模型分布中diff掉小模型的分布得到更准确的token预测。
9.4 通过使用外部知识验证主动检测和减轻幻觉
与幻觉有关的数据问题可以(至少理论上)通过创建高质量无噪声的数据集来解决。但是,验证和清理数百GB的文本语料库难度太大了。
因此也有了一些其他的方法:
- 利用外部知识验证正确性
- 修改解码策略
- 采样多个输出并检查其一致性
《A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation》作者发现:
- 幻觉的生成是会传播的,比如一句话出现幻觉,后续生成的文本可能也会出现幻觉甚至更严重。这意味着,如果我们能够“主动”检测并减轻幻觉,那么我们也可以阻止其在后续生成的句子中的传播;
- logit输出值(输出词汇表上的概率分布)可以用来获取幻觉的信号。具体地说,我们计算了一个概率得分,并展示了当这个得分很低时,模型更容易产生幻觉。因此,它可以作为幻觉的一个信号,当得分很低时,可以对生成的内容进行信息验证。
基于这两个发现,作者提出了主动检测和减轻的方法。
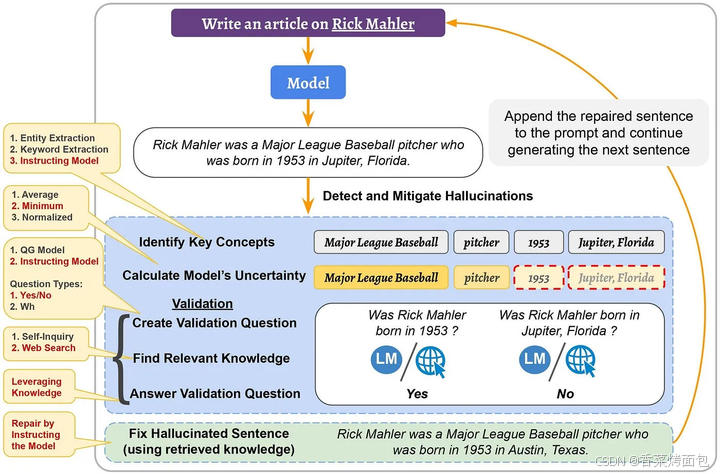
在检测阶段,首先确定潜在幻觉的候选者,即生成句子的重要概念。然后,利用其logit输出值计算模型对它们的不确定性并检索相关知识。
在减轻阶段,使用检索到的知识作为证据修复幻觉句子。将修复的句子附加到输入(和之前生成的句子)上,并继续生成下一个句子。这个过程不仅减轻了检测到的幻觉,而且还阻止了其在后续生成的句子中的传播。
9.5 SelfCheckGPT
SelfCheckGPT的主要思想是:如果模型真的掌握某个事实,那么多次生成的结果应该是相似的且事实一致的;相反,如果模型在胡扯,那么随机采样多次的结果会发散甚至矛盾。
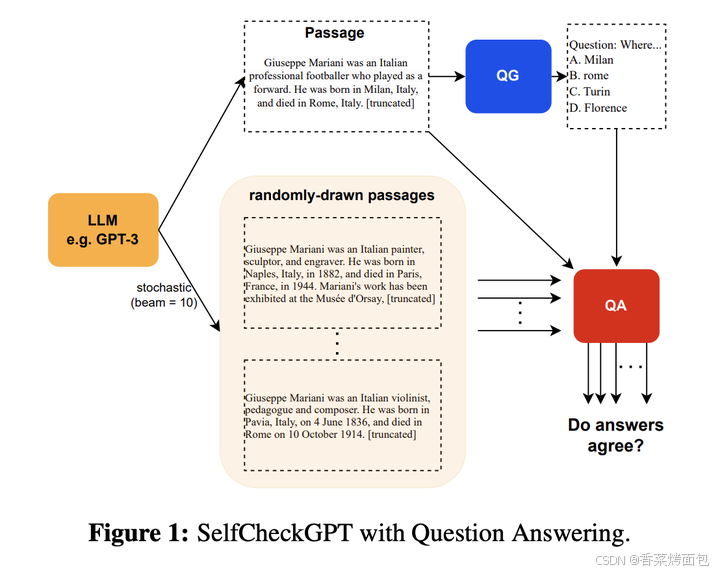
因此,他们从模型中采样多个response(比如通过变化温度参数)并测量不同response之间的信息一致性,以确定哪些声明是事实,哪些是幻觉。这种信息一致性可以使用各种方法计算,比如可以使用神经方法计算语义等价(如BERTScore)或使用IE/QA-based方法。
10. LLMs什么时候最容易产生幻觉?
- 数值混淆:当LLM处理与数字有关的文本,如日期或数值时,容易产生幻觉;
- 处理长文本:在需要解读长期依赖关系的任务中,例如文档摘要或长对话历史,模型可能会生成自相矛盾的内容;
- 逻辑推断障碍:若模型误解了源文本中的信息,它有可能产生不准确的结论。因此,模型的逻辑推理能力至关重要;
- 上下文与内置知识的冲突:模型在处理信息时,可能会过度依赖于预训练阶段获取的知识,而忽略实际上下文,导致输出不准确;
- 错误的上下文信息:当给定的上下文包含错误信息或基于错误的假设时(如:“为什么高尔夫球比篮球大?”或“氦的原子序数为什么是1?”),模型可能无法识别这些错误,并在其回答中产生幻觉。
style="display: none !important;">


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









