







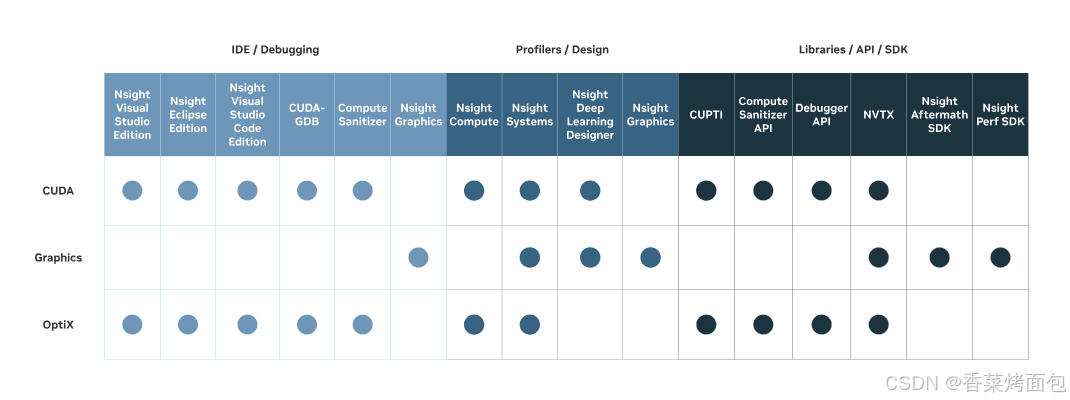
NVIDIA Nsight 是 NVIDIA 的 性能分析和调试工具(新一代 profiling 工具,支持 Pascal 及以后显卡),可以简单地理解为一种帮助用户查看和理解用到GPU程序在计算机上如何运行的工具,如下图,Nsight 有很多 SDK:
-
Nsight Systems 是系统级别的性能分析工具,记录程序在运行过程中的各种信息,如每个任务的开始和结束时间、GPU的利用率、内存使用情况等
-
Nsight Compute 内核级(Kernel)分析,针对 Kernel 函数的详细性能分析工具
工作流:先用nsight system做全局的分析,如果需要看kernel内部的profile再用nsight compute
Nsight Systems(nsys)
主要功能:
-
系统级分析:Nsight Systems 能够捕获和分析整个系统的性能数据,包括 CPU 和 GPU 的活动、内存使用情况、线程调度、I/O 操作等
-
时间轴视图:提供详细的时间轴视图,展示不同时间点上系统中各个组件的活动情况,通过时间轴视图直观地看到 CPU 和 GPU 任务的执行时间、数据传输时间等
-
API 跟踪:能够跟踪各种 API 调用,如 CUDA API、NVTX(NVIDIA Tools Extension)标记、操作系统线程调度等,了解程序的执行流程和时间开销
NVTX是 NVIDIA 提供的一种 标记(instrumentation)工具,类似于日志,在代码执行时插入一个时间点,方便后续分析。例如用于标记一段代码的开始和结束,在 Nsight Systems 中可以看到该代码块的运行时间。
安装了CUDA Toolkit,那么 ${CUDA_HOME}/bin/nsys 就是 nsight system 的可执行程序,它可以分为两部分,服务器上的性能测试工具用于生成程序运行报告,以及各种平台都可用的可视化工具用于可视化报告。
安装
官网下载:Nsight Systems - Get Started | NVIDIA Developer
# 可通过 NVIDIA CUDA Toolkit 安装:
sudo apt-get install nsight-systems
# 使用官网下载的 .run 安装包
sudo sh ./nsight-systems-2024.1.1-linux-x64-installer.run使用方法
nsys profile -o report_name ./program-
profile 是 Nsight Systems 的主要命令,表示进行性能分析
-
-o report_name 表示生成的报告文件名
-
./program 是要分析的可执行程序
这个命令会生成一个 .qdrep 文件格式的报告文件,它包含详细的性能数据,可在 Nsight Systems GUI 里查看
参数说明
可用参数:User Guide — nsight-systems 2025.2 documentation
常用参数:
| 参数 | 作用 |
| -o <file> | 指定输出文件名,默认 .qdrep 格式 |
| --export=json,csv | 以 JSON 或 CSV 格式导出数据 |
| --trace | 选择跟踪的API,可以选择多个API,用逗号分隔(可选 cuda, nvtx, cublas, cublas-verbose, cusparse, cusparse-verbose, cudnn, cudla, cudla-verbose, cusolver, cusolver-verbose, opengl, opengl-annotations, openacc, openmp, osrt, mpi, nvvideo, vulkan, vulkan-annotations, dx11, dx11-annotations, dx12, dx12-annotations, openxr, openxr-annotations, oshmem, ucx, wddm, tegra-accelerators, python-gil, syscall, none 等),默认cuda, opengl, nvtx, osrt |
| --stats=true | 生成汇总统计数据(如CUDA API调用次数、内存复制耗时、内核执行时间等) |
| --delay=5 | 分析开始前的延迟时间(5秒) |
| --gpu-metrics-device=all | 启用GPU指标采样(如SM利用率、显存带宽等),--gpu-metrics-device=0 采集设备0的GPU指标 |
| --cpu-sampling=true | 采集 CPU 采样信息 |
| --sample=cpu / none(禁用) | 启用或禁用 CPU 采样 |
| --cuda-memory-usage=true | 记录 CUDA 设备内存使用情况 |
| --cuda-graph-trace=true | 记录 CUDA Graph 相关事件 |
| --cuda-api-trace=true | 跟踪所有 CUDA API 调用 |
| --cuda-kernel-trace=true | 记录所有 CUDA Kernel 运行情况 |
使用示例
nsys profile -o cosyvoice_output_profile --trace=cuda,nvtx,cudnn,cublas --force-overwrite true --stats=true python3 test.py输出日志:
Generating '/tmp/nsys-report-f320.qdstrm'
[1/7] [========================100%] cosyvoice_output_profile.nsys-rep
[2/7] [========================100%] cosyvoice_output_profile.sqlite
[3/7] Executing 'nvtx_sum' stats report
Time (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Style Range
-------- --------------- --------- --------- -------- -------- -------- ----------- ------- ----------------------
100.0 25914250 5 5182850.0 381205.0 190341 24717605 10920804.1 PushPop cuBLAS:cublasCreate_v2
[4/7] Executing 'cuda_api_sum' stats report # CUDA API 调用情况
Time (%) Total Time (ns) Num Calls Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- ---------- ---------- -------- --------- ----------- ---------------------------------------------
80.3 10358881689 1409857 7347.5 5237.0 3188 343075341 306124.0 cudaLaunchKernel
11.1 1436493713 124736 11516.3 6206.0 2236 15224393 83925.4 cudaMemcpyAsync
2.3 295162087 8 36895260.9 34495481.5 33785770 53554183 6766844.3 cuModuleLoadData
2.3 292028324 59181 4934.5 4173.0 647 2876973 12701.6 cudaStreamSynchronize
1.0 128752583 248 519163.6 425018.0 555 14443880 988469.1 cudaFree
0.7 84060664 392 214440.5 192236.5 3452 701729 79004.7 cudaMalloc
0.5 70052591 9163 7645.2 6416.0 3829 1326380 22441.2 cudaLaunchKernelExC_v11060
0.4 52285398 108 484124.1 8696.0 3023 2603350 830488.0 cudaMemcpy
0.4 50324530 41747 1205.5 797.0 316 3182562 21494.7 cudaOccupancyMaxActiveBlocksPerMultiprocessor
0.3 44518268 13903 3202.1 2156.0 415 519551 5378.2 cudaEventRecord
0.2 24419384 31970 763.8 749.0 268 18761 402.7 cudaStreamIsCapturing_v10000
0.2 23140304 118 196104.3 69098.0 12565 10974009 1011387.6 cuLibraryUnload
0.1 18422715 128 143927.5 2280.0 1572 15800233 1398763.7 cudaStreamCreateWithPriority
0.0 3504721 353 9928.4 8088.0 340 66210 7807.4 cudaMemsetAsync
0.0 3074673 11 279515.7 271034.0 255070 337612 23474.4 cudaGetDeviceProperties_v2_v12000
0.0 3046025 32 95188.3 2248.0 1447 2464976 435194.5 cudaStreamCreateWithFlags
0.0 2991256 9 332361.8 12234.0 10977 2875108 953541.7 cuMemcpyHtoD_v2
0.0 955800 5 191160.0 32399.0 24370 832921 358775.6 cudaHostAlloc
0.0 612264 1915 319.7 199.0 116 43860 1679.2 cuGetProcAddress_v2
0.0 492834 46 10713.8 8355.5 6277 25048 4922.6 cuLaunchKernel
0.0 485943 92 5282.0 730.0 314 280721 29439.7 cudaEventCreateWithFlags
0.0 414859 1 414859.0 414859.0 414859 414859 0.0 cuMemFree_v2
0.0 319254 8 39906.8 42172.5 27425 49642 8442.1 cuMemGetInfo_v2
0.0 275576 1 275576.0 275576.0 275576 275576 0.0 cuMemAlloc_v2
0.0 214321 11 19483.7 3722.0 2599 165368 48457.1 cudaDeviceSynchronize
0.0 70210 16 4388.1 3274.0 2302 21516 4591.2 cudaStreamDestroy
0.0 26123 16 1632.7 1163.5 481 4317 1181.4 cudaStreamWaitEvent
0.0 22822 1 22822.0 22822.0 22822 22822 0.0 cudaFreeHost
0.0 21214 1 21214.0 21214.0 21214 21214 0.0 cudaMemGetInfo
0.0 19249 37 520.2 416.0 271 2938 465.1 cudaEventDestroy
0.0 11246 5 2249.2 2551.0 1328 3243 822.8 cuInit
0.0 3707 6 617.8 277.5 206 2384 866.8 cuModuleGetLoadingMode
[5/7] Executing 'cuda_gpu_kern_sum' stats report
Time (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- -------- -------- -------- -------- ----------- ----------------------------------------------------------------------------------------------------
14.6 772567971 75600 10219.2 11872.0 1440 20704 3758.4 std::enable_if<!T7, void>::type internal::gemvx::kernel<int, int, __half, __half, __half, float, (b…
11.0 580247887 127951 4534.9 4288.0 2720 17504 1167.9 std::enable_if<!T7, void>::type internal::gemvx::kernel<int, int, __half, __half, __half, float, (b…
9.8 519450330 14742 35236.1 31296.0 30272 103168 10084.7 ampere_fp16_s16816gemm_fp16_128x128_ldg8_f2f_stages_32x5_tn
6.9 363848726 61966 5871.7 5984.0 2592 12833 2016.2 void at::native::<unnamed>::CatArrayBatchedCopy<at::native::<unnamed>::OpaqueType<(unsigned int)2>,…
5.9 312309518 64198 4864.8 2271.0 1408 161953 13546.1 void at::native::<unnamed>::CatArrayBatchedCopy_contig<at::native::<unnamed>::OpaqueType<(unsigned …
4.8 251616640 96074 2619.0 2688.0 2143 12384 180.5 void at::native::<unnamed>::vectorized_layer_norm_kernel<c10::Half, float>(int, T2, const T1 *, con…
3.3 172392465 159121 1083.4 1056.0 896 7488 123.9 void at::native::vectorized_elementwise_kernel<(int)4, at::native::CUDAFunctor_add<c10::Half>, at::…
3.1 164766835 28018 5880.7 6176.0 4480 23808 1336.1 ampere_fp16_s16816gemm_fp16_64x64_ldg8_relu_f2f_stages_64x5_tn
2.6 134799439 23414 5757.2 4224.0 2753 23904 2740.3 ampere_fp16_s16816gemm_fp16_64x64_ldg8_f2f_stages_64x5_tn
2.6 134756826 14720 9154.7 8544.0 4928 43521 2605.5 fmha_cutlassF_f16_aligned_64x64_rf_sm80(PyTorchMemEffAttention::AttentionKernel<cutlass::half_t, cu…
2.4 128633611 40754 3156.3 2880.0 2368 12832 702.7 std::enable_if<T7, void>::type internal::gemvx::kernel<int, int, __half, __half, __half, float, (bo…
2.3 123877156 39623 3126.4 3040.0 2208 27616 760.5 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_128x2_tn_align8>(T1::Params)
2.1 108588446 6272 17313.2 17248.0 16352 62881 858.0 ampere_fp16_s16816gemm_fp16_128x64_ldg8_f2f_stages_64x3_tn
2.0 106948205 62164 1720.4 1696.0 1631 7680 64.1 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl_nocast<at::n…
1.8 94728772 47693 1986.2 1952.0 1791 11809 184.6 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl_nocast<at::n…
1.5 78954813 6627 11914.1 10240.0 9600 17312 2640.7 void at_cuda_detail::cub::DeviceRadixSortDownsweepKernel<at_cuda_detail::cub::DeviceRadixSortPolicy…
1.3 70262245 38073 1845.5 1792.0 1184 13984 262.3 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl_nocast<at::n…
1.0 54732201 952 57491.8 57408.0 56928 59361 357.7 ampere_fp16_s16816gemm_fp16_256x128_ldg8_f2f_stages_32x3_tn
0.9 50160766 17224 2912.3 1856.0 1248 16224 1521.0 void cudnn::ops::nchwToNhwcKernel<__half, __half, float, (bool)0, (bool)1, (cudnnKernelDataType_t)0…
0.9 48771463 34762 1403.0 1376.0 1151 5023 133.7 void at::native::unrolled_elementwise_kernel<at::native::AUnaryFunctor<long, long, bool, at::native…
0.9 48049575 45802 1049.1 1055.0 960 8800 113.9 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BUnaryFunctor<c10::Half, c10::Ha…
0.8 42741937 46012 928.9 928.0 800 9601 84.6 void at::native::vectorized_elementwise_kernel<(int)4, at::native::FillFunctor<c10::Half>, at::deta…
0.8 42736157 20493 2085.4 2048.0 1760 12576 294.7 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl_nocast<at::n…
0.8 42694098 13286 3213.5 3232.0 2687 4928 283.6 void <unnamed>::softmax_warp_forward<c10::Half, c10::Half, float, (int)10, (bool)0, (bool)0>(T2 *, …
0.7 38980768 6770 5757.9 5632.0 5343 26656 722.5 sm80_xmma_fprop_implicit_gemm_f16f16_f16f32_f32_nhwckrsc_nhwc_tilesize64x32x64_stage5_warpsize2x2x1…
0.7 36879043 33161 1112.1 1120.0 1023 3840 29.1 void at::native::vectorized_elementwise_kernel<(int)4, at::native::<unnamed>::launch_clamp_scalar(a…
0.6 33668323 551 61104.0 77440.0 25120 167137 23480.9 sm86_xmma_fprop_implicit_gemm_tf32f32_tf32f32_f32_nhwckrsc_nchw_tilesize128x128x16_stage3_warpsize2…
0.5 26740815 7682 3481.0 3359.0 2656 14784 599.3 void at::native::<unnamed>::RowwiseMomentsCUDAKernel<c10::Half>(long, T1, const T1 *, T1 *, T1 *)
0.5 26301532 448 58708.8 58497.0 57536 109057 2638.9 ampere_fp16_s1688gemm_fp16_256x64_ldg8_f2f_stages_32x1_tn
0.5 26174749 3910 6694.3 6784.0 3840 18912 799.8 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_16x16_128x1_tn_align8>(T1::Params)
0.5 24986853 14493 1724.1 1728.0 1471 13952 157.0 void splitKreduce_kernel<(int)32, (int)16, int, __half, __half, float, __half, (bool)1, (bool)1, (b…
0.4 23504855 6888 3412.4 3423.0 2655 5792 330.7 std::enable_if<!T7, void>::type internal::gemvx::kernel<int, int, __half, __half, __half, float, (b…
0.4 22271972 6277 3548.2 3585.0 2688 6176 442.6 void at::native::<unnamed>::cunn_SoftMaxForward<(int)8, c10::Half, float, c10::Half, at::native::<u…
0.4 22175058 6258 3543.5 3456.0 2656 11456 515.6 std::enable_if<!T7, void>::type internal::gemvx::kernel<int, int, __half, __half, __half, float, (b…
0.4 21447850 6627 3236.4 3232.0 2848 4320 86.9 void at_cuda_detail::cub::DeviceRadixSortUpsweepKernel<at_cuda_detail::cub::DeviceRadixSortPolicy<_…
0.4 21011848 14720 1427.4 1376.0 1119 9344 310.0 void at::native::vectorized_elementwise_kernel<(int)4, at::native::GeluCUDAKernelImpl(at::TensorIte…
0.4 20423084 9621 2122.8 2272.0 1601 8608 347.7 void at::native::reduce_kernel<(int)512, (int)1, at::native::ReduceOp<long, at::native::func_wrappe…
0.4 20127825 7084 2841.3 2817.0 1760 4544 348.1 std::enable_if<!T7, void>::type internal::gemvx::kernel<int, int, __half, __half, __half, float, (b…
0.4 20020709 1190 16824.1 16832.0 16224 31745 460.7 ampere_fp16_s16816gemm_fp16_128x64_ldg8_f2f_stages_64x4_tn
0.3 18336483 16486 1112.2 1056.0 992 1504 94.2 void at::native::vectorized_elementwise_kernel<(int)4, void at::native::compare_scalar_kernel<c10::…
0.3 17060458 11362 1501.5 1472.0 1376 12512 251.0 void at::native::vectorized_elementwise_kernel<(int)4, at::native::<unnamed>::mish_kernel(at::Tenso…
0.3 16795347 8022 2093.7 2111.0 1440 3008 270.4 void gemvNSP_kernel<__half, __half, __half, float, (int)1, (int)32, (int)4, (int)1024, (bool)0, cub…
0.3 16332108 532 30699.5 30592.0 30112 89856 2579.5 ampere_fp16_s16816gemm_fp16_128x128_ldg8_f2f_stages_64x3_tn
0.3 15969543 7462 2140.1 2112.0 1824 2624 147.3 void <unnamed>::softmax_warp_forward<c10::Half, c10::Half, float, (int)9, (bool)0, (bool)0>(T2 *, c…
0.3 15760971 7682 2051.7 2016.0 1856 11936 301.2 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl_nocast<void …
0.3 15081750 6627 2275.8 2272.0 2112 2848 20.6 void at_cuda_detail::cub::RadixSortScanBinsKernel<at_cuda_detail::cub::DeviceRadixSortPolicy<__half…
0.3 13774194 9621 1431.7 1440.0 1120 10560 288.3 void at::native::unrolled_elementwise_kernel<at::native::direct_copy_kernel_cuda(at::TensorIterator…
0.2 12582718 7682 1637.9 1632.0 1472 12512 226.9 void at::native::<unnamed>::ComputeFusedParamsCUDAKernel<c10::Half>(long, long, long, const T1 *, c…
0.2 12262121 2870 4272.5 4065.0 3904 15296 640.2 void cutlass::Kernel<cutlass_75_wmma_tensorop_f16_s161616gemm_f16_32x32_128x2_nn_align1>(T1::Params)
0.2 12105441 8622 1404.0 1408.0 1280 7488 107.5 void cudnn::ops::nhwcToNchwKernel<__half, __half, float, (bool)1, (bool)0, (cudnnKernelDataType_t)0…
0.2 12002938 240 50012.2 49408.0 48832 63105 1953.3 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_s1688fprop_optimized_tf32_128x64_32x3_nhwc_align4…
0.2 11391185 3602 3162.5 2944.0 2784 10208 808.7 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_16x16_128x2_tn_align8>(T1::Params)
0.2 10559484 1260 8380.5 8032.0 7679 30304 1304.6 sm86_xmma_fprop_implicit_gemm_indexed_f16f16_f16f32_f32_nhwckrsc_nhwc_tilesize64x64x64_stage3_warps…
0.2 10272693 5514 1863.0 1825.0 1472 2560 153.5 std::enable_if<!T7, void>::type internal::gemvx::kernel<int, int, __half, __half, __half, float, (b…
0.2 9319404 120 77661.7 77536.5 76609 79648 614.0 sm86_xmma_fprop_implicit_gemm_indexed_tf32f32_tf32f32_f32_nhwckrsc_nchw_tilesize128x64x32_stage4_wa…
0.2 9196646 1700 5409.8 5248.0 4960 23232 1180.0 ampere_fp16_s16816gemm_fp16_64x64_ldg8_relu_f2f_stages_64x6_tn
0.2 8720435 2653 3287.0 3200.0 2560 4736 331.3 void at::native::reduce_kernel<(int)512, (int)1, at::native::ReduceOp<c10::Half, at::native::ArgMax…
0.2 8684992 2632 3299.8 3232.0 3008 10144 247.7 std::enable_if<!T7, void>::type internal::gemvx::kernel<int, int, __half, __half, __half, float, (b…
0.2 8650671 2300 3761.2 2848.0 1600 14016 1518.5 void at::native::elementwise_kernel<(int)128, (int)2, void at::native::gpu_kernel_impl_nocast<at::n…
0.2 8469323 2635 3214.2 2463.0 1408 21953 1846.1 void cudnn::ops::nchwToNhwcKernel<float, float, float, (bool)0, (bool)1, (cudnnKernelDataType_t)2>(…
0.2 8340383 5116 1630.3 1632.0 1471 3136 107.0 void <unnamed>::softmax_warp_forward<c10::Half, c10::Half, float, (int)8, (bool)0, (bool)0>(T2 *, c…
0.1 7412591 6830 1085.3 1056.0 960 4865 243.5 void at::native::vectorized_elementwise_kernel<(int)4, at::native::AUnaryFunctor<c10::Half, c10::Ha…
0.1 7269373 2889 2516.2 2463.0 2016 2977 202.1 void at::native::reduce_kernel<(int)512, (int)1, at::native::ReduceOp<c10::Half, at::native::func_w…
0.1 7087814 2889 2453.4 2336.0 2080 4031 234.7 void at::native::reduce_kernel<(int)512, (int)1, at::native::ReduceOp<c10::Half, at::native::func_w…
0.1 6926676 2889 2397.6 2336.0 1920 3008 167.8 void at::native::reduce_kernel<(int)512, (int)1, at::native::ReduceOp<c10::Half, at::native::func_w…
0.1 6912929 3982 1736.0 1632.0 1280 9408 332.7 void at::native::unrolled_elementwise_kernel<at::native::direct_copy_kernel_cuda(at::TensorIterator…
0.1 6587511 2209 2982.1 2913.0 2751 5120 198.1 void at::native::<unnamed>::cunn_SoftMaxForward<(int)8, c10::Half, float, c10::Half, at::native::<u…
0.1 6560602 3220 2037.5 2048.0 1664 12224 264.8 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl<at::native::…
0.1 6303529 1840 3425.8 2912.0 1088 12512 1720.2 void at::native::vectorized_elementwise_kernel<(int)4, at::native::CUDAFunctor_add<float>, at::deta…
0.1 5189724 2209 2349.4 2400.0 1984 2848 158.7 void at::native::index_elementwise_kernel<(int)128, (int)4, void at::native::gpu_index_kernel<void …
0.1 5122891 1426 3592.5 2593.0 1376 11872 1589.5 void at::native::elementwise_kernel<(int)128, (int)2, void at::native::gpu_kernel_impl_nocast<at::n…
0.1 4991986 1311 3807.8 2944.0 2048 16192 1905.9 void at::native::<unnamed>::weight_norm_fwd_first_dim_kernel<float, float>(T1 *, T2 *, const T1 *, …
0.1 4953793 4887 1013.7 1023.0 928 1600 30.3 void at::native::unrolled_elementwise_kernel<at::native::CUDAFunctor_add<c10::Half>, at::detail::Ar…
0.1 4761442 4260 1117.7 1088.0 992 9056 222.2 void at::native::vectorized_elementwise_kernel<(int)4, at::native::AUnaryFunctor<long, long, bool, …
0.1 4534932 102 44460.1 44304.5 43649 47360 639.6 sm80_xmma_fprop_implicit_gemm_tf32f32_tf32f32_f32_nhwckrsc_nchw_tilesize128x128x16_stage4_warpsize2…
0.1 4505234 2209 2039.5 2048.0 1887 2240 60.3 void at::native::triu_tril_kernel<float, int, (bool)0, (int)2, (bool)0>(at::cuda::detail::TensorInf…
0.1 4058537 3703 1096.0 1056.0 928 10239 269.6 void at::native::vectorized_elementwise_kernel<(int)4, at::native::CUDAFunctorOnOther_add<c10::Half…
0.1 4021087 2669 1506.6 1408.0 1152 4096 262.0 void at::native::unrolled_elementwise_kernel<at::native::direct_copy_kernel_cuda(at::TensorIterator…
0.1 3772419 1380 2733.6 1857.0 1344 7392 1324.2 void at::native::vectorized_elementwise_kernel<(int)4, at::native::sin_kernel_cuda(at::TensorIterat…
0.1 3752430 2889 1298.9 1312.0 1248 1568 18.0 void at::native::<unnamed>::distribution_elementwise_grid_stride_kernel<float, (int)4, void at::nat…
0.1 3597844 1694 2123.9 2112.0 2047 2240 26.6 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_16x16_64x1_tn_align2>(T1::Params)
0.1 3583889 2889 1240.5 1152.0 1088 1760 166.9 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BinaryFunctor<c10::Half, c10::Ha…
0.1 3355313 2889 1161.4 1184.0 992 2049 68.1 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BinaryFunctor<bool, bool, bool, …
0.1 3192444 1127 2832.7 2144.0 992 8448 1314.6 void at::native::vectorized_elementwise_kernel<(int)4, void at::native::<unnamed>::pow_tensor_scala…
0.1 3166371 2203 1437.3 1472.0 1311 1696 72.4 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl_nocast<at::n…
0.1 3070130 2889 1062.7 1056.0 960 3680 51.0 void at::native::vectorized_elementwise_kernel<(int)4, at::native::AUnaryFunctor<c10::Half, c10::Ha…
0.1 2669748 210 12713.1 12512.0 12384 25952 1253.2 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_f16_s16816fprop_optimized_f16_64x64_64x5_nhwc_ali…
0.0 2601593 2463 1056.3 1056.0 960 2624 45.0 void at::native::vectorized_elementwise_kernel<(int)2, at::native::CUDAFunctor_add<c10::Half>, at::…
0.0 2598915 2209 1176.5 1184.0 1151 1568 17.8 at::native::<unnamed>::fill_reverse_indices_kernel(long *, int, at::cuda::detail::IntDivider<unsign…
0.0 2545557 342 7443.1 7296.0 7040 8704 317.5 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_128x1_tn_align8>(T1::Params)
0.0 2401782 1364 1760.8 1760.0 1567 11489 351.4 void <unnamed>::softmax_warp_forward<c10::Half, c10::Half, float, (int)7, (bool)0, (bool)0>(T2 *, c…
0.0 2301558 2209 1041.9 1055.0 991 1311 17.5 void at::native::vectorized_elementwise_kernel<(int)4, at::native::CUDAFunctorOnSelf_add<c10::Half>…
0.0 2085704 2301 906.4 896.0 863 2048 33.9 void at::native::vectorized_elementwise_kernel<(int)4, at::native::FillFunctor<float>, at::detail::…
0.0 2041076 410 4978.2 4576.0 4223 12224 762.2 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_128x2_nn_align2>(T1::Params)
0.0 2013201 2232 902.0 896.0 863 1056 14.2 void at::native::vectorized_elementwise_kernel<(int)4, at::native::FillFunctor<bool>, at::detail::A…
0.0 1887575 916 2060.7 2047.5 1664 3488 227.7 void at::native::<unnamed>::CatArrayBatchedCopy_contig<at::native::<unnamed>::OpaqueType<(unsigned …
0.0 1859061 230 8082.9 8000.0 7840 14208 609.8 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_f16_s16816dgrad_optimized_f16_64x64_64x5_nhwc_ali…
0.0 1820968 1679 1084.6 1056.0 928 4321 215.6 void at::native::vectorized_elementwise_kernel<(int)4, at::native::AUnaryFunctor<float, float, floa…
0.0 1778220 140 12701.6 15664.5 5760 26208 4374.6 sm86_xmma_fprop_implicit_gemm_indexed_tf32f32_tf32f32_f32_nhwckrsc_nchw_tilesize64x32x64_stage4_war…
0.0 1617582 492 3287.8 3264.0 2304 7840 349.1 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_128x1_nn_align2>(T1::Params)
0.0 1295252 1104 1173.2 1152.0 1023 2592 78.9 void at::native::vectorized_elementwise_kernel<(int)4, at::native::CUDAFunctorOnSelf_add<float>, at…
0.0 1290299 1104 1168.7 1152.0 1119 10400 295.2 void at::native::vectorized_elementwise_kernel<(int)4, at::native::reciprocal_kernel_cuda(at::Tenso…
0.0 1289162 23 56050.5 58112.0 29504 67617 9096.2 void at::native::tensor_kernel_scan_innermost_dim<float, std::plus<float>>(T1 *, const T1 *, unsign…
0.0 1221956 36 33943.2 29600.0 29185 43200 6345.1 sm86_xmma_fprop_implicit_gemm_indexed_tf32f32_tf32f32_f32_nhwckrsc_nhwc_tilesize128x64x32_stage4_wa…
0.0 1115971 25 44638.8 45153.0 28032 49280 3576.6 sm86_xmma_fprop_implicit_gemm_tf32f32_tf32f32_f32_nhwckrsc_nchw_tilesize128x128x16_stage6_warpsize2…
0.0 1088520 21 51834.3 50113.0 49888 61409 3459.4 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_s1688fprop_optimized_tf32_256x64_16x4_nhwc_align4…
0.0 843048 386 2184.1 2016.0 1535 10561 816.4 void cudnn::ops::nhwcToNchwKernel<float, float, float, (bool)1, (bool)0, (cudnnKernelDataType_t)0>(…
0.0 778043 69 11276.0 11456.0 5088 11840 1086.4 void at::native::<unnamed>::upsample_linear1d_out_frame<c10::Half, float>(int, T2, bool, at::Generi…
0.0 756536 306 2472.3 2592.0 1664 3232 307.1 void at::native::<unnamed>::CatArrayBatchedCopy<at::native::<unnamed>::OpaqueType<(unsigned int)2>,…
0.0 732774 21 34894.0 35168.0 20128 38272 3589.0 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_s1688dgrad_optimized_tf32_64x64_32x5_nhwc_align4>…
0.0 642363 460 1396.4 1376.0 1344 1856 72.9 void <unnamed>::softmax_warp_forward<c10::Half, c10::Half, float, (int)6, (bool)0, (bool)0>(T2 *, c…
0.0 617665 230 2685.5 2656.0 2464 4671 142.8 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl<at::native::…
0.0 554755 17 32632.6 31648.0 31360 44768 3195.9 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_s1688dgrad_optimized_tf32_64x128_32x3_nhwc_align4…
0.0 546241 144 3793.3 3808.0 3392 4032 112.4 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_64x1_nn_align2>(T1::Params)
0.0 513453 386 1330.2 1216.0 1183 4032 252.7 void at::native::vectorized_elementwise_kernel<(int)4, at::native::<unnamed>::silu_kernel(at::Tenso…
0.0 471457 20 23572.9 23440.0 23232 25248 429.9 ampere_fp16_s16816gemm_fp16_128x64_ldg8_relu_f2f_stages_64x3_tn
0.0 470885 9 52320.6 49505.0 49056 75745 8786.7 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_s1688fprop_optimized_tf32_128x64_16x6_nhwc_align4…
0.0 453728 276 1643.9 1568.0 1440 2624 253.9 void at::native::unrolled_elementwise_kernel<at::native::direct_copy_kernel_cuda(at::TensorIterator…
0.0 432797 92 4704.3 4640.0 4512 6528 232.9 sm80_xmma_fprop_implicit_gemm_indexed_f16f16_f16f32_f32_nhwckrsc_nhwc_tilesize64x32x64_stage5_warps…
0.0 427270 154 2774.5 2752.0 2208 8864 557.7 void cutlass::Kernel<cutlass_75_wmma_tensorop_f16_s161616gemm_f16_32x32_64x1_tn_align1>(T1::Params)
0.0 415804 299 1390.6 1056.0 992 7776 947.3 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BUnaryFunctor<float, float, floa…
0.0 392484 233 1684.5 1632.0 1568 2784 144.6 void at::native::<unnamed>::CatArrayBatchedCopy_aligned16_contig<at::native::<unnamed>::OpaqueType<…
0.0 364196 20 18209.8 17215.5 16736 33792 3711.1 sm80_xmma_fprop_implicit_gemm_indexed_wo_smem_tf32f32_tf32f32_f32_nhwckrsc_nhwc_tilesize128x32x16_s…
0.0 363171 20 18158.6 18112.0 17921 18912 224.2 ampere_fp16_s16816gemm_fp16_128x64_ldg8_relu_f2f_stages_32x6_tn
0.0 357434 253 1412.8 1377.0 1344 2079 85.8 void at::native::vectorized_elementwise_kernel<(int)4, at::native::cos_kernel_cuda(at::TensorIterat…
0.0 352768 23 15337.7 14944.0 13377 18656 1228.2 void tensorTransformGeneric<float, float, float, (bool)1, (bool)0, (bool)0, (cudnnKernelDataType_t)…
0.0 333504 20 16675.2 16672.0 16639 16832 44.0 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_f16_s16816fprop_optimized_f16_128x128_32x3_nhwc_a…
0.0 324419 328 989.1 928.0 895 2816 164.9 void <unnamed>::elementwise_kernel_with_index<int, at::native::arange_cuda_out(const c10::Scalar &,…
0.0 314018 4 78504.5 78544.5 77920 79009 448.7 sm86_xmma_fprop_implicit_gemm_indexed_tf32f32_tf32f32_f32_nhwckrsc_nchw_tilesize128x64x32_stage4_wa…
0.0 298267 253 1178.9 1152.0 1119 4128 242.0 void at::native::vectorized_elementwise_kernel<(int)4, at::native::exp_kernel_cuda(at::TensorIterat…
0.0 291230 120 2426.9 2368.0 2335 7840 499.9 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_128x2_nn_align8>(T1::Params)
0.0 263715 120 2197.6 2145.0 2111 5728 340.7 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_64x1_tn_align8>(T1::Params)
0.0 261727 20 13086.4 13088.0 12864 13121 55.4 sm86_xmma_fprop_implicit_gemm_f16f16_f16f32_f32_nhwckrsc_nhwc_tilesize64x64x64_stage3_warpsize2x2x1…
0.0 215443 239 901.4 896.0 863 929 14.4 void at::native::vectorized_elementwise_kernel<(int)4, at::native::FillFunctor<long>, at::detail::A…
0.0 198016 4 49504.0 49568.0 49152 49728 267.7 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_s1688fprop_optimized_tf32_64x128_16x6_nhwc_align4…
0.0 182751 21 8702.4 8736.0 8128 9471 282.3 cudnn_infer_ampere_scudnn_128x32_relu_interior_nn_v1
0.0 176770 46 3842.8 3824.0 3295 4896 532.4 void at::native::<unnamed>::_unfold_backward_elementwise_kernel<(int)128, (int)4, void at::native::…
0.0 175170 20 8758.5 8767.5 8448 8896 91.8 sm86_xmma_fprop_implicit_gemm_f16f16_f16f32_f32_nhwckrsc_nhwc_tilesize64x64x64_stage6_warpsize2x2x1…
0.0 166817 115 1450.6 1440.0 1375 1504 27.1 void at::native::vectorized_elementwise_kernel<(int)4, at::native::<unnamed>::elu_kernel(at::Tensor…
0.0 161956 69 2347.2 1696.0 1120 4960 1353.4 void at::native::vectorized_elementwise_kernel<(int)4, at::native::<unnamed>::leaky_relu_kernel(at:…
0.0 161311 46 3506.8 2368.5 1088 6944 2442.9 void at::native::<unnamed>::reflection_pad1d_out_kernel<float>(const T1 *, T1 *, long, long, long)
0.0 144415 43 3358.5 2880.0 2657 4192 639.1 void at::native::<unnamed>::CatArrayBatchedCopy<at::native::<unnamed>::OpaqueType<(unsigned int)4>,…
0.0 143328 5 28665.6 33536.0 20672 34176 7184.7 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_s1688dgrad_optimized_tf32_128x64_16x6_nhwc_align4…
0.0 135392 20 6769.6 6784.0 6560 6848 63.6 void cutlass::Kernel<cutlass_75_tensorop_f16_s1688gemm_f16_64x128_tn_align1>(T1::Params)
0.0 131395 23 5712.8 5888.0 4096 6400 540.1 void at::native::reduce_kernel<(int)512, (int)1, at::native::ReduceOp<float, at::native::func_wrapp…
0.0 125891 10 12589.1 12576.0 12416 12801 136.7 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_s1688fprop_optimized_tf32_64x64_32x5_nhwc_align4>…
0.0 119009 46 2587.2 2544.0 1408 5120 937.5 void at::native::<unnamed>::distribution_elementwise_grid_stride_kernel<float, (int)4, void at::nat…
0.0 101030 60 1683.8 1552.5 1503 2208 183.6 void at::native::elementwise_kernel<(int)128, (int)2, void at::native::gpu_kernel_impl_nocast<at::n…
0.0 100162 26 3852.4 3745.0 3712 4320 188.1 void cutlass::Kernel<cutlass_75_wmma_tensorop_f16_s161616gemm_f16_32x32_64x2_tn_align1>(T1::Params)
0.0 93638 49 1911.0 1953.0 1471 2432 164.2 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl<at::native::…
0.0 79807 32 2494.0 2496.0 2432 2528 25.6 void cutlass::Kernel<cutlass_75_wmma_tensorop_f16_s161616gemm_f16_32x32_32x1_tn_align1>(T1::Params)
0.0 78529 20 3926.5 3936.0 3903 3968 21.1 void cutlass::Kernel<cutlass_75_wmma_tensorop_f16_s161616gemm_f16_32x32_128x1_nn_align1>(T1::Params)
0.0 74402 26 2861.6 3200.0 2208 3328 453.5 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_64x1_tn_align2>(T1::Params)
0.0 69056 20 3452.8 3040.0 3008 4513 651.5 void cutlass::Kernel<cutlass_75_wmma_tensorop_f16_s161616gemm_f16_32x32_64x1_nn_align1>(T1::Params)
0.0 69026 20 3451.3 3440.5 3392 3584 44.3 void gemvNSP_kernel<float, float, float, float, (int)1, (int)16, (int)4, (int)1024, (bool)0, cublas…
0.0 66272 5 13254.4 10432.0 10272 24704 6401.3 void implicit_convolve_sgemm<float, float, (int)1024, (int)5, (int)5, (int)3, (int)3, (int)3, (int)…
0.0 66240 1 66240.0 66240.0 66240 66240 0.0 sm86_xmma_fprop_implicit_gemm_indexed_tf32f32_tf32f32_f32_nhwckrsc_nchw_tilesize128x256x32_stage2_w…
0.0 65471 46 1423.3 1328.5 1120 1760 187.3 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BinaryFunctor<float, float, floa…
0.0 64610 26 2485.0 2496.0 2304 2656 77.1 void at::native::reduce_kernel<(int)512, (int)1, at::native::ReduceOp<c10::Half, at::native::NormTw…
0.0 58751 46 1277.2 1184.0 1088 1632 176.2 void at::native::vectorized_elementwise_kernel<(int)4, at::native::<unnamed>::launch_clamp_scalar(a…
0.0 57503 49 1173.5 1184.0 1024 2208 172.3 void at::native::vectorized_elementwise_kernel<(int)4, at::native::bitwise_not_kernel_cuda(at::Tens…
0.0 56031 46 1218.1 1264.0 1120 1376 84.1 void at::native::vectorized_elementwise_kernel<(int)4, void at::native::compare_scalar_kernel<float…
0.0 53476 23 2325.0 2368.0 2016 2464 104.2 void gemv2N_kernel<int, int, float, float, float, float, (int)128, (int)2, (int)4, (int)4, (int)1, …
0.0 52191 23 2269.2 2272.0 1760 4768 585.1 void vector_fft_c2r<(unsigned int)16, EPT<(unsigned int)4>, (unsigned int)32, (unsigned int)16, (pa…
0.0 51490 23 2238.7 2240.0 2080 2400 69.3 void at::native::<unnamed>::indexSelectLargeIndex<c10::Half, long, unsigned int, (int)2, (int)2, (i…
0.0 51331 23 2231.8 2208.0 1985 2336 89.5 void at::native::reduce_kernel<(int)512, (int)1, at::native::ReduceOp<int, at::native::func_wrapper…
0.0 48928 2 24464.0 24464.0 24416 24512 67.9 void cudnn::detail::dgrad_engine<float, (int)512, (int)6, (int)5, (int)3, (int)3, (int)3, (bool)0>(…
0.0 48769 46 1060.2 1056.0 1023 1088 18.6 void at::native::vectorized_elementwise_kernel<(int)4, at::native::AbsFunctor<float>, at::detail::A…
0.0 48094 23 2091.0 2080.0 1695 2784 197.0 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BUnaryFunctor<float, float, floa…
0.0 47361 23 2059.2 2016.0 1824 2720 204.0 void at::native::elementwise_kernel<(int)128, (int)2, void at::native::gpu_kernel_impl_nocast<at::n…
0.0 47136 23 2049.4 1504.0 1440 12992 2395.0 void at::native::unrolled_elementwise_kernel<at::native::sin_kernel_cuda(at::TensorIteratorBase &):…
0.0 44190 26 1699.6 1696.5 1567 1760 49.1 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl_nocast<at::n…
0.0 43714 23 1900.6 1920.0 1696 2017 75.7 void vector_fft_r2c<(unsigned int)16, EPT<(unsigned int)4>, (unsigned int)32, (unsigned int)16, (pa…
0.0 40004 18 2222.4 2208.5 2177 2273 25.0 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_16x16_32x1_tn_align2>(T1::Params)
0.0 37984 1 37984.0 37984.0 37984 37984 0.0 void cutlass_cudnn_infer::Kernel<cutlass_tensorop_s1688dgrad_optimized_tf32_64x128_16x6_nhwc_align4…
0.0 36063 18 2003.5 2048.0 1855 2112 95.9 void cutlass::Kernel<cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_32x1_nn_align2>(T1::Params)
0.0 35358 23 1537.3 1632.0 1184 1760 158.7 void at::native::vectorized_elementwise_kernel<(int)4, at::native::<unnamed>::complex_kernel_cuda(a…
0.0 33568 23 1459.5 1312.0 1184 3200 495.8 void at::native::vectorized_elementwise_kernel<(int)4, at::native::cos_kernel_cuda(at::TensorIterat…
0.0 33182 23 1442.7 1440.0 1376 1632 56.1 void at::native::<unnamed>::distribution_elementwise_grid_stride_kernel<float, (int)4, void at::nat…
0.0 31809 14 2272.1 2272.0 2240 2304 12.6 void cutlass::Kernel<cutlass_75_wmma_tensorop_f16_s161616gemm_f16_32x32_32x1_nn_align1>(T1::Params)
0.0 30752 23 1337.0 1344.0 1311 1408 21.4 void at::native::<unnamed>::upsample_nearest1d_out_frame<float, &at::native::nearest_neighbor_compu…
0.0 30048 26 1155.7 1152.0 1120 1376 60.3 void at::native::vectorized_elementwise_kernel<(int)4, at::native::CUDAFunctor_add<int>, at::detail…
0.0 28256 23 1228.5 1216.0 1152 1408 56.2 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BinaryFunctor<float, float, floa…
0.0 28031 23 1218.7 1216.0 1088 1344 50.1 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BinaryFunctor<bool, bool, bool, …
0.0 27136 2 13568.0 13568.0 13472 13664 135.8 void precomputed_convolve_sgemm<float, (int)1024, (int)5, (int)5, (int)4, (int)3, (int)3, (int)1, (…
0.0 26846 23 1167.2 1184.0 1120 1184 19.1 void at::native::vectorized_elementwise_kernel<(int)4, at::native::tanh_kernel_cuda(at::TensorItera…
0.0 26593 23 1156.2 1120.0 1120 1375 70.4 void at::native::vectorized_elementwise_kernel<(int)4, at::native::<unnamed>::launch_clamp_scalar(a…
0.0 26047 21 1240.3 1248.0 1184 1344 30.2 void cask_cudnn_infer::computeOffsetsKernel<(bool)0, (bool)0>(cask_cudnn_infer::ComputeOffsetsParam…
0.0 25568 23 1111.7 1088.0 1024 1633 120.0 void at::native::vectorized_elementwise_kernel<(int)4, at::native::CUDAFunctorOnOther_add<float>, a…
0.0 23488 23 1021.2 1024.0 992 1025 9.2 void <unnamed>::elementwise_kernel_with_index<int, at::native::linspace_cuda_out(const c10::Scalar …
0.0 20736 2 10368.0 10368.0 10240 10496 181.0 sm86_xmma_fprop_implicit_gemm_tf32f32_tf32f32_f32_nhwckrsc_nhwc_tilesize64x32x64_stage4_warpsize2x2…
0.0 9537 9 1059.7 1056.0 1024 1088 24.8 void at::native::vectorized_elementwise_kernel<(int)4, at::native::AUnaryFunctor<long, long, long, …
0.0 9439 2 4719.5 4719.5 4671 4768 68.6 void cutlass::Kernel<cutlass_80_tensorop_s1688gemm_64x64_16x6_nn_align1>(T1::Params)
0.0 9249 6 1541.5 1536.0 1536 1568 13.0 void <unnamed>::softmax_warp_forward<c10::Half, c10::Half, float, (int)5, (bool)0, (bool)0>(T2 *, c…
0.0 9152 3 3050.7 3072.0 2912 3168 129.3 void cutlass::Kernel<cutlass_75_tensorop_f16_s1688gemm_f16_64x64_nn_align1>(T1::Params)
0.0 8800 6 1466.7 1376.0 1248 1792 253.9 void at::native::unrolled_elementwise_kernel<at::native::CUDAFunctor_add<long>, at::detail::Array<c…
0.0 7616 3 2538.7 2496.0 2432 2688 133.2 void at::native::<unnamed>::indexSelectLargeIndex<c10::Half, int, unsigned int, (int)2, (int)2, (in…
0.0 5920 3 1973.3 2016.0 1824 2080 133.2 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl_nocast<at::n…
0.0 5888 3 1962.7 1984.0 1920 1984 37.0 void at::native::elementwise_kernel<(int)128, (int)4, void at::native::gpu_kernel_impl_nocast<at::n…
0.0 5088 3 1696.0 1696.0 1696 1696 0.0 void splitKreduce_kernel<(int)32, (int)16, int, __half, __half, float, __half, (bool)1, (bool)0, (b…
0.0 4960 2 2480.0 2480.0 2464 2496 22.6 void gemvNSP_kernel<float, float, float, float, (int)1, (int)32, (int)4, (int)1024, (bool)0, cublas…
0.0 3745 3 1248.3 1248.0 1216 1281 32.5 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BUnaryFunctor<long, long, long, …
0.0 3520 3 1173.3 1184.0 1152 1184 18.5 void at::native::vectorized_elementwise_kernel<(int)4, at::native::AUnaryFunctor<int, int, bool, at…
0.0 3265 3 1088.3 1088.0 1088 1089 0.6 void at::native::vectorized_elementwise_kernel<(int)4, at::native::BinaryFunctor<long, long, bool, …
0.0 3232 3 1077.3 1088.0 1056 1088 18.5 void at::native::vectorized_elementwise_kernel<(int)4, at::native::CUDAFunctorOnSelf_add<long>, at:…
0.0 2975 2 1487.5 1487.5 1471 1504 23.3 void nchwAddPaddingKernel<float, float, float, (bool)1, (cudnnKernelDataType_t)0>(int, int, int, in…
0.0 2912 2 1456.0 1456.0 1440 1472 22.6 void cudnn::ops::scalePackedTensor_kernel<float, float>(long, T1 *, T2)
0.0 2336 1 2336.0 2336.0 2336 2336 0.0 std::enable_if<!T7, void>::type internal::gemvx::kernel<int, int, float, float, float, float, (bool…
0.0 1888 2 944.0 944.0 928 960 22.6 void cudnn::cnn::kern_precompute_indices<(bool)0>(int *, int, int, int, int, int)
[6/7] Executing 'cuda_gpu_mem_time_sum' stats report
Time (%) Total Time (ns) Count Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Operation
-------- --------------- ----- -------- -------- -------- -------- ----------- ------------------------------
51.2 263283192 10639 24747.0 384.0 320 10279243 187382.5 [CUDA memcpy Host-to-Device]
35.8 184040917 48551 3790.7 928.0 863 8178371 63348.3 [CUDA memcpy Device-to-Host]
13.0 66687256 65663 1015.6 993.0 768 12352 65.2 [CUDA memcpy Device-to-Device]
0.0 148667 332 447.8 384.0 351 1376 196.9 [CUDA memset]
[7/7] Executing 'cuda_gpu_mem_size_sum' stats report
Total (MB) Count Avg (MB) Med (MB) Min (MB) Max (MB) StdDev (MB) Operation
---------- ----- -------- -------- -------- -------- ----------- ------------------------------
3278.385 10639 0.308 0.000 0.000 106.222 1.998 [CUDA memcpy Host-to-Device]
1753.915 48551 0.036 0.000 0.000 106.222 0.727 [CUDA memcpy Device-to-Host]
1307.626 65663 0.020 0.017 0.000 0.701 0.027 [CUDA memcpy Device-to-Device]
1.774 332 0.005 0.000 0.000 0.072 0.018 [CUDA memset]
Generated:
/workspace/output_profile.nsys-rep
/workspace/output_profile.sqliteNsight Compute(ncu)
Nsight Compute 是 CUDA 核心(Kernel)级分析工具,分析 CUDA 内核执行效率、寄存器/访存/算力利用率,用于内核级分析,优化 CUDA Kernel 执行效率。
安装
官网下载:https://developer.nvidia.com/tools-overview/nsight-comp
sudo apt-get install nsight-compute
# .run 安装包
sudo sh ./nsight-compute-2024.1.1-linux-x64-installer.run使用方法
# 对某个 CUDA Kernel 进行分析
ncu --set full -o report_name ./program完成后会在服务器上产生一个 .ncu-rep 文件, 可以在本地用 Nsight Compute 打开
参数说明
可用参数:4. Nsight Compute CLI — NsightCompute 12.8 documentation
常用参数:
| 参数 | 作用 |
| --export <file> | 导出结果到文件 |
| --csv | 以 CSV 格式输出数据 |
| --json | 以 JSON 格式输出数据 |
| --launch-skip <n> | 跳过前 n 次 Kernel 执行 |
| --launch-count <n> | 分析前 n 次 Kernel 执行 |
| --section <name> | 选择分析的部分,(如 --section=SpeedOfLight 分析计算/内存吞吐瓶颈) |
| --set <profile-set> | full(全面分析)、memory(内存分析)、compute(计算分析) |
| --target-processes | 分析的进程范围,常用 all(捕获所有CUDA进程) |
| --metrics <metric-list> | 指定要分析的 GPU 指标,如 sm__cycles_elapsed.avg, dram__throughput.avg |
| --kernel-regex | 过滤需分析的内核(通过正则表达式匹配内核名称),--kernel-regex="matmul" 仅分析名称含 matmul 的内核 |
| --sampling-interval <ms> | 采样间隔(毫秒) |
| --nvtx | 采集 NVTX 事件 |

















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









