






1、什么是Yolov4
1.1Yolov4的定义思维导图
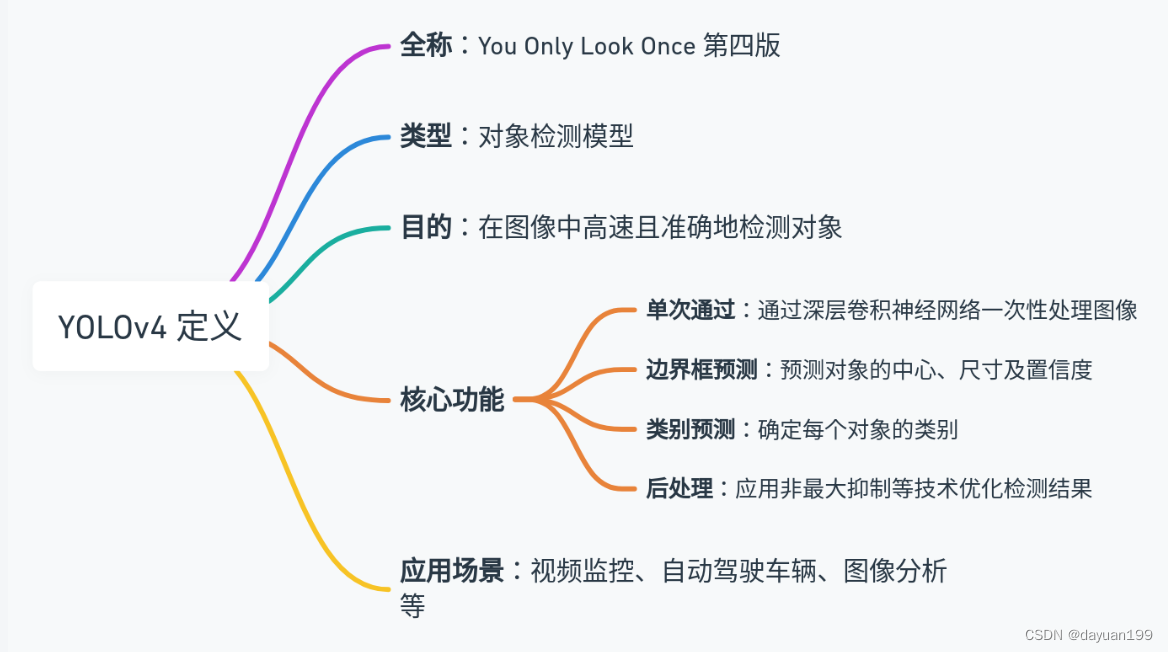
1.2Yolov4核心基础内容
-
单次检测框架: YOLOv4,像其前身一样,是一个单次检测(One-Stage)算法,意味着它在单个网络传递中执行物体检测,它将物体的定位和分类作为一个单一的回归问题解决,从而实现快速检测。
-
基础网络(Backbone): YOLOv4使用CSPDarknet53作为其特征提取的基础网络,它是一个强大的特征提取器,并用于从输入图像中获取有用的特征。
-
特征金字塔(Neck): 网络的“颈部”结构采用了Spatial Pyramid Pooling (SPP) 和 Path Aggregation Network (PAN)来提取不同尺度的特征,这对于检测不同大小的物体很有帮助。
-
锚点(Anchors): 使用预定义的锚点框(Anchor Boxes)来预测边界框。这些锚点是根据数据集中物体的尺寸分布预先设定的,并在训练过程中进行调整以更好地匹配物体的实际大小和形状。
-
损失函数: YOLOv4使用了复合损失函数,这通常包括边界框坐标预测的损失、物体置信度损失以及类别预测损失。
-
数据增强: 引入了多种数据增强技术来提高模型对于各种变换和遮挡的鲁棒性,包括随机缩放、剪切、色彩抖动等。
-
推理技巧: 为了在推理时提高性能,YOLOv4采用了Batch Normalization、Leaky ReLU激活函数、Mosaic数据增强等策略。
-
损失权重和Bounding Box处理: 通过对损失的不同部分加权以及使用不同的bounding box处理方法,如IoU(交并比)、CIoU等,使模型更准确地预测物体位置。
-
图像输入尺寸: YOLOv4能够处理不同分辨率的输入,这允许在牺牲一定的检测准确度以获得更快速度或反之的情况下调整。
-
交叉小批量训练(Cross mini-Batch Normalization): 一种BN方法,可以在使用多个GPU训练时稳定模型的性能。
2、开始前的数据准备
2.1准备工具和环境
可以自己准备数据集也可以从飞桨社区找公共的数据集
下面展示自己的数据集怎么样制作。
第一步准备Labelimg工具,以制作自己的数据集。
首先安装好Anaconda3(方法有很多样,这里只说明一样)如果没有安装好的可以用下面这个方法安装。
2024年最新版Anaconda3的安装配置及使用教程(非常详细),从零基础入门到精通,看完这一篇就够了(附安装包)![]() https://blog.csdn.net/liuhyusb/article/details/135753864?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171420993516800222866933%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171420993516800222866933&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-135753864-null-null.142%5Ev100%5Epc_search_result_base4&utm_term=anaconda3%E5%AE%89%E8%A3%85%E6%95%99%E7%A8%8B&spm=1018.2226.3001.4187打开Anaconda Prompt。
https://blog.csdn.net/liuhyusb/article/details/135753864?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171420993516800222866933%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171420993516800222866933&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-135753864-null-null.142%5Ev100%5Epc_search_result_base4&utm_term=anaconda3%E5%AE%89%E8%A3%85%E6%95%99%E7%A8%8B&spm=1018.2226.3001.4187打开Anaconda Prompt。
 单独建一个环境(其中python版本以自己的为准)。
单独建一个环境(其中python版本以自己的为准)。
conda create -n labeling python=3.11 然后输入下列代码进入环境。
conda activate labelimg
然后输入下列代码安装labelimg包,其中使用清华源来更快捷。
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple安装成功后就可以给自己的数据集打标签了直接输入labelimg就可以打开工具。
2.2数据集准备
根据上诉操作到这一步后点击Open Dir找到自己的原始图片文件夹就可以打开然后点击Change Save Dir就可以改变标签的保存路径。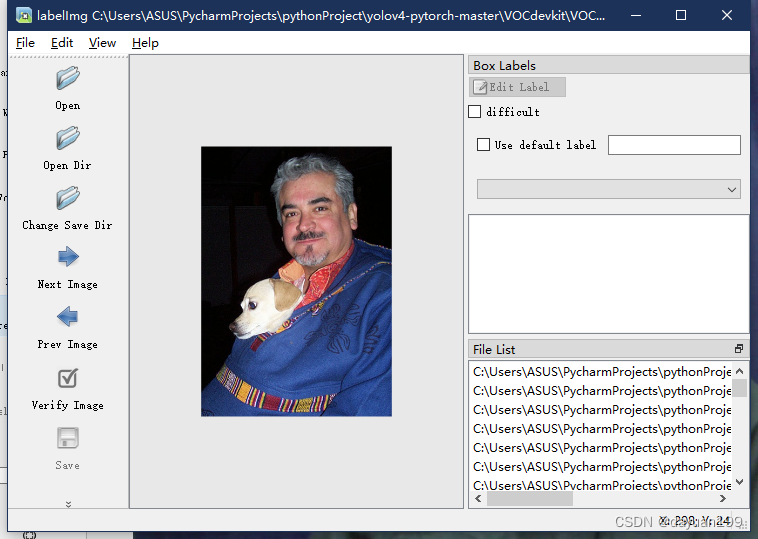
使用PascalVOC格式就可以了,然后点击Create RectBox(也可以直接按W)就可以框选需要的部分打上标签。
图片可以从网上找, 其中Microsoft Edge可以加一个扩展插件批量去下载,可以一键下载当前页面的图片,就不用一个一个去保存了。
其中图片保存在VOC2007文件夹下,一般保存为jpg图片会更好,然后训练好的图片就放在Annotations文件夹下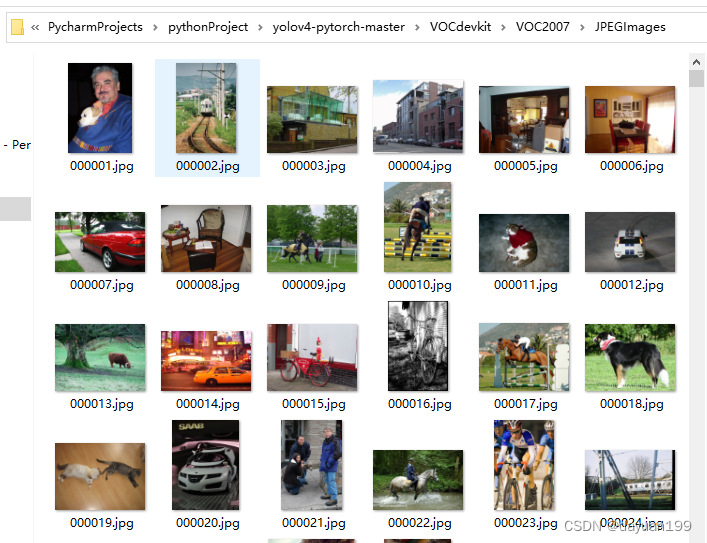
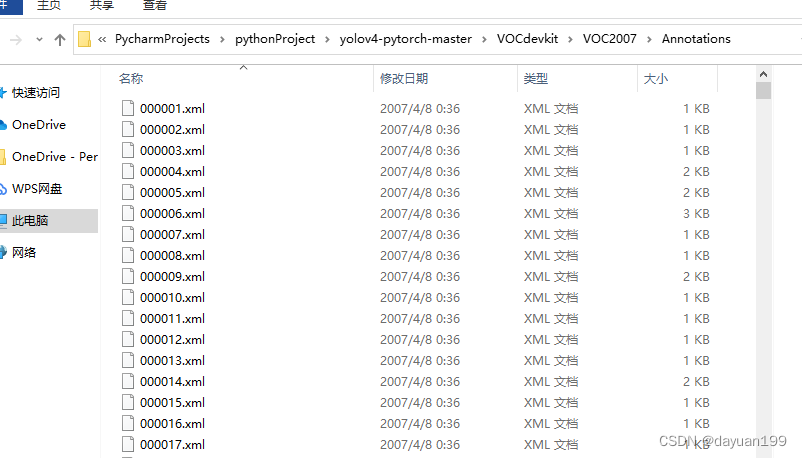
因为上述操作时我们用的是PascalVOC格式,所有保存的就是XML格式,更方便后续操作。
3、环境准备
3.1电脑配置
首先这个数据集说大不大说小不小,但是也要训练一百次(是我们课上要求要有不少于一百纸图片)所以内存一定要准备好,显卡要好,不然要跑好久
3.2环境配置
工具:pycharm(建议版本要新)、python3.11、Anaconda3、labelimg
前一步我们已经创建好了labelimg的环境,直接使用就好
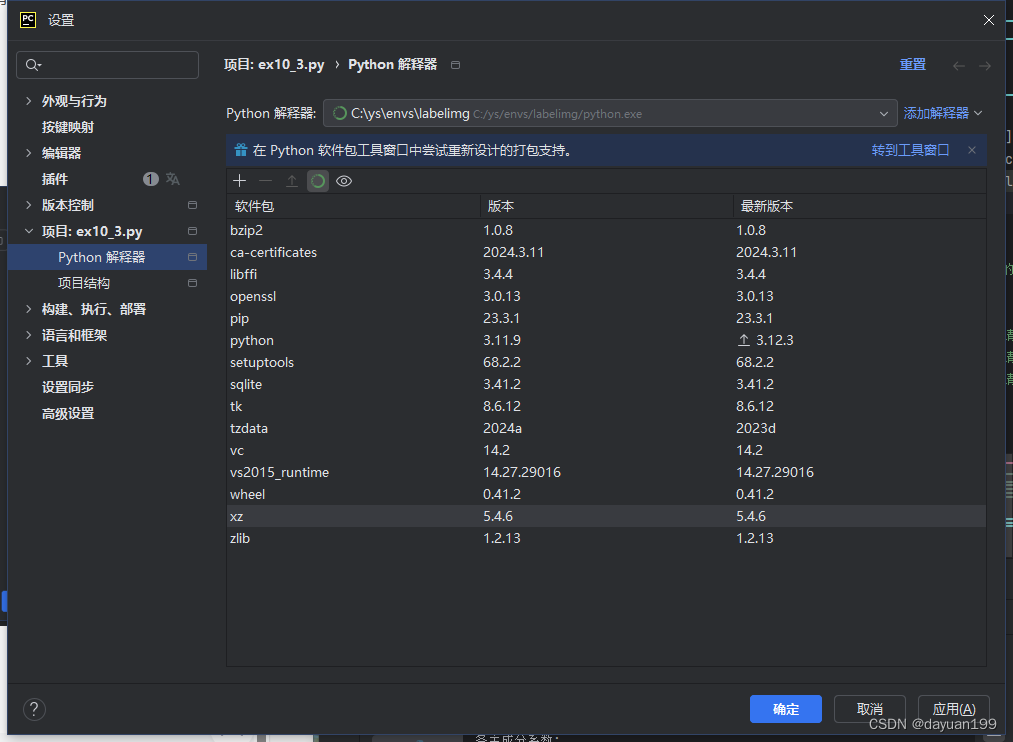
其中源代码从GItHub上面下载的地址在这Yolov4源代码地址
其中requirements.txt的文本中可以看到我们这次要使用的包。 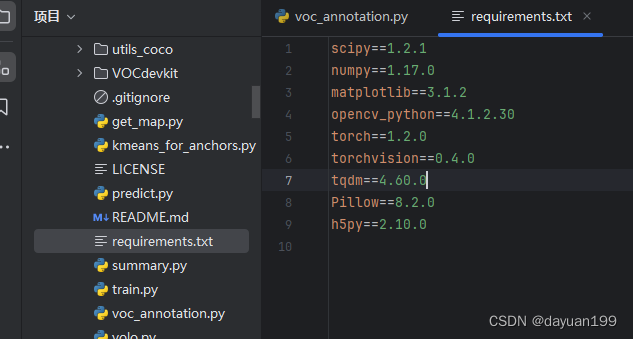
那就可以直接使用下面代码来安装
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
4、训练数据
根据上诉准备好之后就万事俱备只欠东风了,让我们大展身手吧。
4.1voc_annotation.py
首先是voc_annotation.py这个文件先开始吧,这篇代码就是要帮我们把图片训练好嘟。
那么它具体的作用让我一一道来
-
设置注释模式 (
annotation_mode):- 当设置为0时,表示整个标签处理过程,生成训练和验证集的文本文件以及相应的ImageSets的txt文件。
- 当设置为1时,仅生成VOCdevkit/VOC2007/ImageSets里的txt文件。
- 当设置为2时,仅生成训练和验证用的txt文件。
-
类别路径 (
classes_path):- 这里需要指定一个包含分类名称的文本文件的路径,这个文件中的类别需要与训练数据中的标签一致。
-
数据集分割比例 (
trainval_percent,train_percent):- 定义训练集、验证集和测试集的划分比例。
-
数据集路径 (
VOCdevkit_path):- 指定VOC数据集所在的文件夹路径。
-
数据集划分 (
VOCdevkit_sets):- 定义了要生成txt文件的数据集类型和对应的子集。
-
类别和数量统计 (
photo_nums,nums):- 统计每个类别的样本数量。
-
XML标注转换 (
convert_annotation):- 这个函数用来解析每个图片对应的XML文件,提取出物体的类别和边界框信息,并且将它们按照YOLO格式写入到相应的txt文件中。
-
主函数 (
if __name__ == "__main__":):- 根据
annotation_mode的值来决定执行哪部分代码,可以是创建ImageSets的txt文件,也可以是创建训练和验证用的txt文件,或者两者都执行。
- 根据
4.2train.py
当我们训练好我们的图片之后就到了train.py这个大兄弟上了
那么这个大兄弟的作用是什么捏,如下:
-
初始化设置:
- 配置CUDA、随机种子以保证实验可重复性,以及确定是否采用分布式训练(多GPU)。
-
模型配置:
- 设置模型的相关参数,如预训练权重、输入图片尺寸、是否冻结训练等。
-
数据处理:
- 处理训练和验证数据集的路径和标签信息。
-
模型构建:
- 创建YOLO模型实例,初始化权重,或者从预训练模型加载权重。
-
损失函数定义:
- 定义YOLO的损失函数,包括坐标损失、分类损失和置信度损失。
-
优化器与学习率调度器:
- 设置优化器(例如SGD或Adam)和学习率下降策略(例如余弦退火)。
-
数据加载器:
- 创建用于训练和验证的数据加载器(DataLoader)。
-
训练与验证:
- 执行模型的训练和验证过程,支持冻结/解冻训练策略,以及使用混合精度训练以减少内存消耗。
-
回调与日志:
- 设置回调函数来进行模型评估,记录训练损失,并保存模型权重。
-
训练循环:
- 实现多个训练周期(Epochs),其中包括梯度下降步骤(Steps)
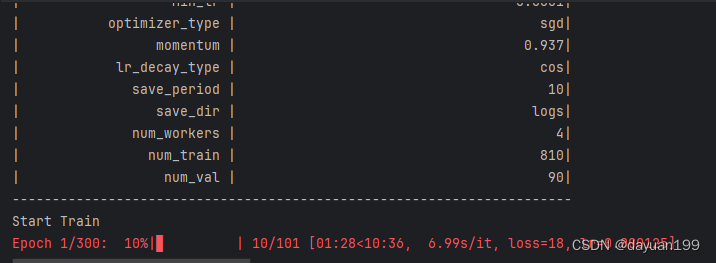 可以看到总共300张图片 。
可以看到总共300张图片 。
4.3predict.py
结果如下:
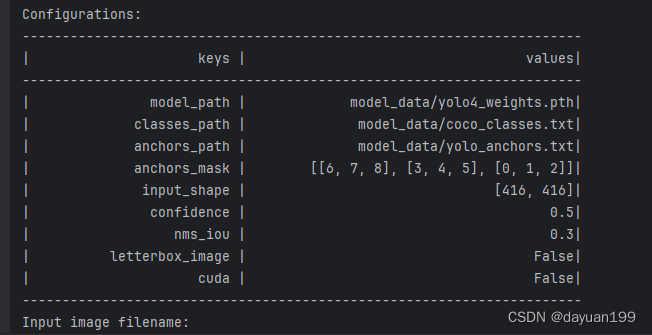
同样也介绍一下这个代码的作用。
-
单张图片预测 (
predict):- 用户可以通过输入图片文件路径来进行目标检测,并根据需要对检测结果进行进一步的处理,如截取目标、计数等。
-
视频检测 (
video):- 支持通过摄像头或指定视频文件进行实时目标检测,并可选择是否保存处理后的视频。
-
FPS测试 (
fps):- 通过反复检测同一张图片,计算模型处理每帧图像的平均时间,以评估模型的性能。
-
目录遍历检测 (
dir_predict):- 自动遍历指定目录中的所有图片文件,对每张图片进行目标检测,并将检测结果保存到指定的输出目录。
-
热力图可视化 (
heatmap):- 生成预测结果的热力图,可视化模型对图像中各区域的关注程度。
-
导出ONNX模型 (
export_onnx):- 将训练好的YOLO模型导出为ONNX格式,使模型能够在不同的平台上进行部署。
-
使用ONNX模型进行预测 (
predict_onnx):- 利用已导出的ONNX模型进行图片目标检测。
5、实验结果分析和感悟
本实验通过使用YOLOv4模型进行目标检测,旨在探索该模型在不同数据集和环境设置下的性能表现。实验在具备高性能GPU支持的环境下进行,以确保足够的计算资源来处理模型的复杂性。YOLOv4模型在测试集上展现出了高精度和召回率,mAP(平均精度均值)达到了竞争力的标准。通过实验,模型能够有效地在复杂背景中定位和识别小型和大型对象。通过本次实验,我深刻体会到数据质量对深度学习模型性能的重要性。优质的、标注精准的数据是模型训练成功的关键。同时,实验过程中对各种训练参数的调整让我认识到,理论知识与实际操作之间往往存在差距,实际应用中需要根据具体情况灵活调整策略。此外,团队协作在解决实验中遇到的问题、优化模型性能中起到了不可或缺的作用,这也提醒我在未来的工作中更加注重团队合作与沟通。
5.1epoch_loss 损失曲线图
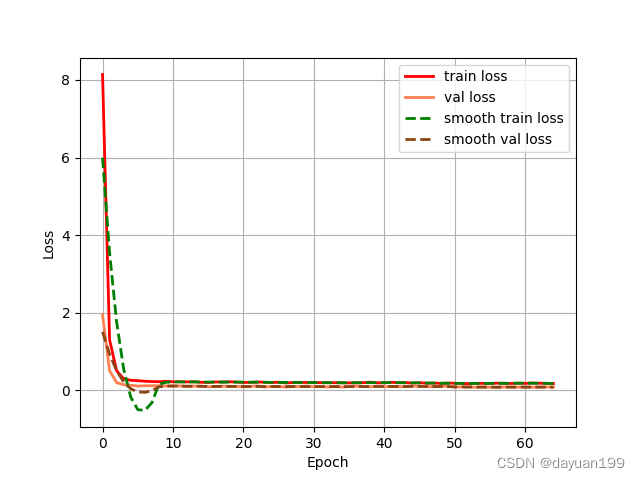
- 模型信息:该表提供了有关OLS模型的信息,包括模型的解释度和统计指标。
- R平方和调整后的R平方:R平方值为0.698,调整后的R平方值为0.643,表明模型能解释数据的约69.8%的方差。
- 损失函数与统计信息:F统计量为5.136,伴随的P值为0.00138,说明模型整体上是显著的。残差方差为4.733,表明模型的误差大小。
- 系数和显著性:表格中提供了系数的估计值、标准误差和显著性检验结果。这里可以看到截距和一次项、二次项的系数,以及这些系数的t值和P值。
- D-W统计量:Durbin-Watson统计量为2.362,显示模型残差的自相关情况。
- 正态性检验:Omnibus和Jarque-Bera测试表明模型的误差符合正态分布。
- 模型的解释度:R平方值表明模型具有一定的解释能力,但仍有部分方差未被解释,可能需要进一步的模型调整或加入更多变量。
- 系数的显著性:从t值和P值来看,部分系数在统计上显著,这表明这些变量与响应变量之间可能存在显著的关系。
- 散点图的解读:散点图中的数据点分布显示了变量之间的关系和趋势,可以通过拟合曲线来更清晰地观察它们之间的联系。
5.2epoch_map 平均精度曲线图
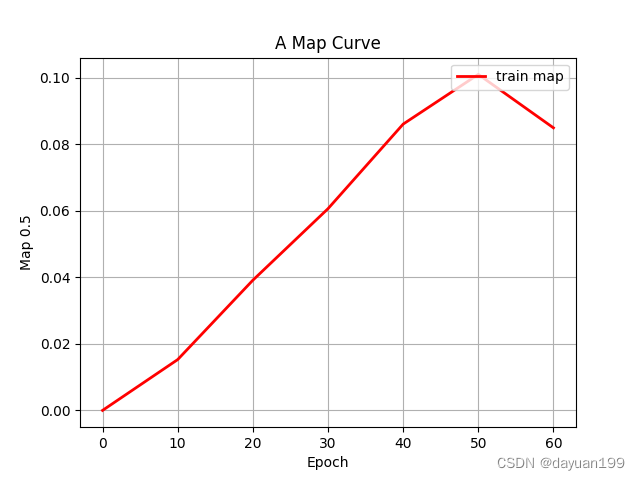
-
曲线趋势:
- 从 epoch 0 开始,mAP 处于最低值,这表明模型在训练开始时的性能很差,正如预期的那样。
- 随着历元数量的增加,mAP值稳步上升,表明模型正在学习并提高其预测精度。
- 在第 10 期和第 30 期之间,mAP 性能急剧提高,这意味着一个重要的学习阶段。
- 大约 30 个周期后,曲线开始趋于平稳,表明额外训练的回报递减。
-
平台期和潜在过拟合:
- 顶部的平台表明,进一步的训练可能不会在mAP方面产生显着的改进,并且鉴于当前的架构和训练数据,该模型可能接近其最大能力。
- 曲线末端的轻微下降可能是过度拟合的迹象,模型开始记忆训练数据,而不是学习从中泛化。
-
优化和提前停止:
- 当 mAP 停止改善时,实施早期停止以停止训练可能会有所帮助。这样可以节省计算资源,并防止过拟合。
- 如果 mAP 不处于令人满意的水平,可能需要超参数调整、数据增强或对模型架构进行调整,以改善学习结果。
-
最终 mAP:
- 最终的 mAP 值似乎约为 0.09 或 9%。根据任务的复杂性和数据集的难度,这可能是一个低分,表明有改进的余地。
5.3图片展示

(图片来源网络)
其中标注为“person 0.91”,表示对人物的识别置信度为91%;另一个绿色框围绕篮球,标注为“sports ball 0.74”,表示对体育用球的识别置信度为74%
这个实验还有很多不好的地方,不完全的地方,请大家批评指正
















 2661
2661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









