







1.存储的介质与读写
谈存储,那么理解存储的介质的特性显然很重要,书中谈了很多硬件结构,但最重要的结论,都浓缩在存储介质对比这张表中了。
磁盘介质对比
| 类别 | 每秒读写(IOPS)次数 | 每GB价格(元) | 随机读取 | 随机写入 |
|---|---|---|---|---|
| 内存 | 千万级 | 150 | 友好 | 友好 |
| SSD盘 | 35000 | 20 | 友好 | 写入放大问题 |
| SAS磁盘 | 180 | 3 | 磁盘寻道 | 磁盘寻道 |
| SATA磁盘 | 90 | 0.5 | 磁盘寻道 | 磁盘寻道 |
从表中可以看出,内存的随机读写能力最强,远超SSD盘和磁盘。但是我们都知道,内存无法持久化。现在许多公司在性能要求高的地方都使用了SSD盘,相对SAS和SATA磁盘,随机读取速度有了很大的提升。但是对于随机写入,存在写入放大问题。
写入放大问题与SSD盘的特性有关,SSD盘不能随机写入,只能整块整块的写入。最简单的例子,比如要写入一个4KB的数据,最坏的情况就是,一个块里已经没有干净空间了,但是有无效数据可以擦除,所以主控就把所有的数据读出来,擦除块,再加上这个4KB新数据写回去,这个操作带来的写入放大就是: 实际写4K的数据,造成了整个块(512KB)的写入操作,那就是128倍放大。此外,SSD盘的寿命也有写入次数相关。
如果使用SSD来作为存储引擎的存储介质,最好从设计上减少或避免随机写入,使用顺序写入取而代之。
2.Bitcask存储模型介绍
存储系统的基本功能包括:增、删、读、改。其中读取操作有分为顺序读取和随机读取。
总体来说,大部分应用使用读的功能最多,解决读的性能是存储系统的重要命题。一般来说。快速查找的思想基本源自二分查找法和哈希查询。例如关系数据库中常用的B+存储模型就是使用二分查找的思想,当然,实际实现比二分查找复杂很多。B+存储模型支持顺序扫描。另外一类则是基于哈希思想的键值模型,这类模型不支持顺序扫描,仅支持随机读取。
今天要讨论的Bitcask模型是一种日志型键值模型。所谓日志型,是指它不直接支持随机写入,而是像日志一样支持追加操作。Bitcask模型将随机写入转化为顺序写入。有两个好处:
- 提高随机写入的吞吐量,因为写操作不需要查找,直接追加即可
- 如果使用SSD作为存储介质,能够更好的利用新硬件的特性
Bitcask中存在3种文件,包括数据文件,索引文件和线索文件(hint file,姑且就叫线索文件吧)。数据文件存储于磁盘上,包含了原始的数据的键值信息;索引文件存在于内存,用于记录记录的位置信息,启动Bitcask时,它会将所有数据的位置信息全部读入一个内存中的哈希表,也就是索引文件;线索文件(hint file)并不是Bitcask的必需文件,它的存在是为了提供启动时构建索引文件的速度。
2.1 日志型的数据文件
Bitcask的数据文件组织如下图:任意时刻,系统中只有一个数据文件支持写入,称为active data file。其余的数据文件都是只读文件,称为older data file。

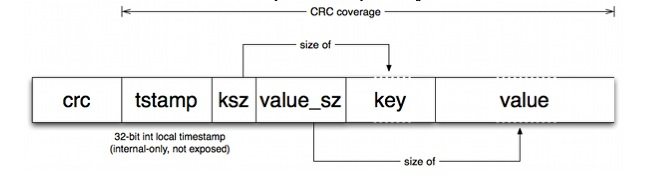
上面数据项分别为:后面几项的crc校验值,时间戳,key,value,key的大小,value的大小。
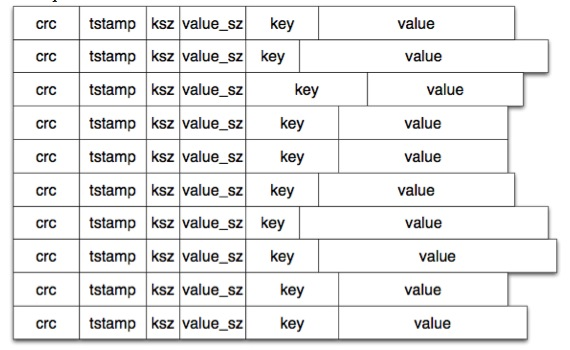
数据文件中就是连续一条条上面格式的数据,如下图:
2.2 索引哈希表
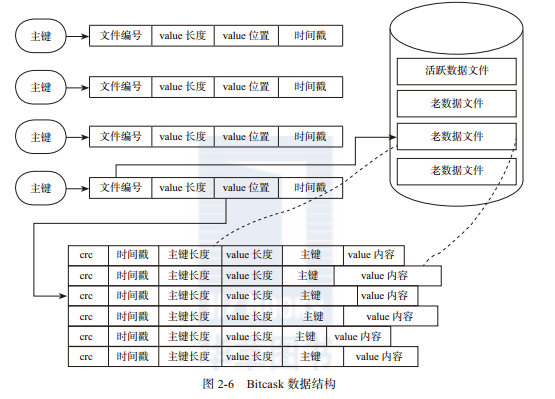
索引哈希表记录了全部记录的主键和位置信息,索引哈希表的值包含了:记录文件的编号,value长度,value的在文件中的位置和时间戳。Bitcask的总体数据结构如下图:
2.3 线索文件(hint file)
Bitcask启动时要重建索引哈希表,如果数据量特别大,则会导致启动很慢。而线索文件(hint file)则是用来加速启动时重建哈希表的速度。线索文件(hint file)的记录与数据文件的格式基本相同,唯一不同的是数据文件记录数据的值,而线索文件(hint file)则是记录数据的位置。
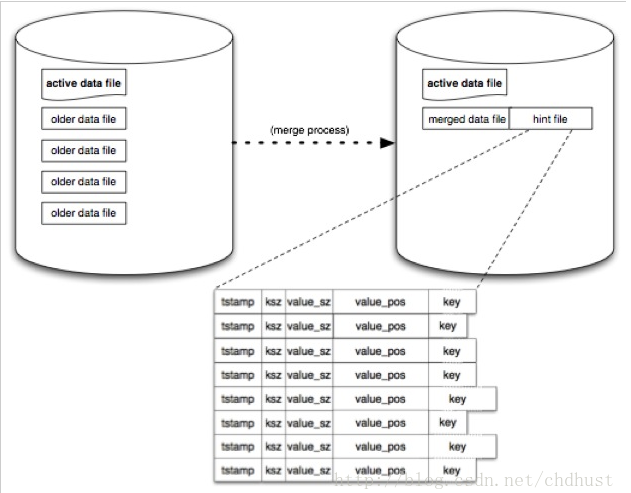
这样在启动的时候就可以不用读数据文件,而是读取线索文件(hint file),一行行重建即可,大大加快了哈希表的重建速度。
3. Bitcask功能介绍
上节提到,存储系统的基本功能包括:增、删、读、改。那么Bitcask中如何实现的呢?
-
如何增加记录?
用户写入的记录直接追加到活动文件,因此活动文件会越来越大,当到达一定大小时,Bitcask会冻结活动文件,新建一个活动文件用于写入,而之前的活动文件则变为了older data file。写入记录的同时还要在索引哈希表中添加索引记录。 -
如何删除记录?
Bitcask不直接删除记录,而是新增一条相同key的记录,把value值设置一个删除的标记。原有记录依然存在于数据文件中,然后更新索引哈希表。 -
如何修改记录?
Bitcask不支持随机写入。因为对于存储系统的基本功能中的增和改,实际上都是一样的,都是直接写入活动数据文件。同时修改索引哈希表中对应记录的值。(这个时候,实际上数据文件中同一个key值对应了多条记录,根据时间戳记录来判断,以最新的数据为准。) -
如何读取记录?
读取时,首先从索引哈希表中定位到记录在磁盘中位置,然后通过IO读取出对应的记录。 -
合并(Marge)操作
Bitcask这种只增不减地不断写入,必然会是数据文件不断的膨胀。而其中有许多是被标记删除和修改后留下的无用记录。合并操作就是为了剔除这部分数据,减小数据文件大小。
merge操作,通过定期将所有older data file中的数据扫描一遍并生成新的data file(没有包括active data file 是因为它还在不停写入)。如果同一个Key有多条记录,则只保留最新的一条。从而去掉数据文件中的冗余数据。而且进行合并(Marge)操作时,还可以顺带生成线索文件(hint file)。合并(Marge)操作通常会在数据库较闲的时候进行,比如凌晨一两点等。
4.总结
Bitcask是一个精炼的键值存储模型。采用日志型的数据结构,只追加不改写就记录,提高了随机写入的吞吐量,通过建立哈希表来加快查询速度,定期合并数据文件,并生成线索文件(hint file),提高启动时重建哈希表的速度。















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









