







开始了leetcode的刷题之路,话不多说,从头开始。。。
344.Reverse String
//my code
#include <string>
using namespace std;
class Solution {
public:
string reverseString(string s) {
int numb = s.size();
string s1 = "";
for(int i = numb - 1; i >= 0; i--)
{
s1 += s[i];
}
return s1;
}
};//others c code
char* reverseString(char* s) {
char *t,*r,tmp;
r=s;
t=s+strlen(s)-1;
while(s<t){
tmp=*t;
*t=*s;
*s=tmp;
s++;
t--;
}
return r;
} 而看了别人用c写的代码,没有用到for循环,使用两个指针,一个指向第一个字符,一个指向最后一个字符,将两个字符实现交换,然后指向第一个字符的指针+1,指向最后一个字符的指针-1,这跟我的方法相比,只循环了一半的次数,就实现了字符反转,好吧。。
345.Reverse Vowels of a String
//My code
class Solution {
public:
string reverseVowels(string s) {
int numb = s.size();
string s1 = "", s2 = s;
for(int i = 0; i < numb; i++)
{
if( s[i] == 'a' || s[i] == 'A' || s[i] == 'e' || s[i] == 'E' || s[i] == 'i' || s[i] == 'I' || s[i] == 'o' || s[i] == 'O' || s[i] == 'u' || s[i] == 'U' )
{
s1 += s[i];
}
}
int n = 0;
for(int j = numb-1; j >= 0; j--)
{
if(s[j] == 'a' || s[j] == 'A' || s[j] == 'e' || s[j] == 'E' || s[j] == 'i' || s[j] == 'I' || s[j] == 'o' || s[j] == 'O' || s[j] == 'u' || s[j] == 'U' )
{
s2[j] = s1[n];
n++;
}
}
return s2;
}
}; //others code
class Solution {
public:
string reverseVowels(string s) {
int start = 0;
int end = s.size()-1;
while(start<end) {
if (isVowel(s[start]) && isVowel(s[end])) {
char temp = s[start];
s[start++] = s[end];
s[end--] = temp;
}else if (isVowel(s[start])) {
end--;
}else if (isVowel(s[end])) {
start++;
} else {
end--;
start++;
}
}
return s;
}
bool isVowel(char l)
{
return (l == 'a' || l == 'A' || l == 'e' || l == 'E' || l == 'i' || l == 'I' || l == 'o' || l == 'O' || l == 'u' || l == 'U');
} 而别人的思路是设置两个指针,分别指向字符串的第一位和最后一位,然后进行一个while循环,对两个指针所指的字符进行分类判断,当前后指针都指向了元音字母,那么交换数据,如果前指针指向元音字符而后指针没有,那么后指针向前进一位,相反,前指针向前进一位,如果两个指针都没有指向元音字母,那么各进一位,知道前指针等于后指针,字符串全部遍历了一遍结束。整个代码还是只循环了一半的字符串长度的次数,而我的是循环了两遍,真的蠢哭了。
1. Two Sum
<span style="font-size:18px;">//My code
//功能:给定一个vector数组和一个目标数traget,若在数组中能寻找到两个数a,b,使得a+b=target,
则输出a,b对应的vertor下标[i,j];
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
vector<int> result;
int count = nums.size();
for(int i = 0; i < count-1; i ++)
{
for(int j = i+1; j < count; j++)
{
if(nums[i] + nums [j] == target)
{
result.push_back(i);
result.push_back(j);
}
}
}
return result;
}</span>
};<span style="font-size:18px;">//others code
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> hash;
unordered_map<int,int>::iterator got;
int len = nums.size();
int idx1, idx2;
//将vector中的内容存储到关联容器,格式为(vector中的值,其对应的下标)。
for (int i = 0; i < len; i++) {
got = hash.find(nums[i]);
if (got == hash.end()) {
hash.insert(make_pair(nums[i],i));
} else {
got->second = i;
}
}
for (vector<int>::const_iterator it = nums.begin(); it != nums.end(); ++it) {
if (hash.count(target-*it)) { //判断加法对应*it的另一个加数是否在容器中
idx1 = (it - nums.begin()); //若在,返回*it的位置索引
idx2 = hash[target-*it]; //并返回hash表中另一个加数对应的值
if (idx1 != idx2) {
break;
}
}
}
return {idx1,idx2};
}
};</span>别人的代码中用到了关联容器unordered_map,容器中保存的关键字是vector中的值,其值则是对应的vector中的下标。让后循环遍历vector,并在遍历中让target减去当前遍历vector位置的值,所得结果为该位置下所对应的另一个加数的值,然后在哈希表中查找,若找到,则表明vector容器中存在这样的一对值,加起来的结果为target,于是返回这两个值对应的下标。这种方式使得一次循环就能得出结果。
2. Add Two Numbers
//My code
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* Create() //创建一个头结点
{
ListNode * lNode = (ListNode*)malloc(sizeof(struct ListNode));
lNode->val = 0;
lNode->next = NULL;
return lNode;
}
void Insert(ListNode* l,int a)
{
ListNode *pNode;
while(l->next != NULL)
l = l->next;
pNode = (ListNode*)malloc(sizeof(struct ListNode));
pNode->val = a;
pNode->next = NULL;
l->next = pNode;
}
int Read(ListNode* l,int x) //头结点不计入
{
int value;
ListNode *pNode = l;
for(int i = 1; i < x; i++)
{
pNode = pNode->next;
}
value = pNode->val;
return value;
}
int Size(ListNode *l) //头结点不计入
{
ListNode *pNode = l;
int count = 0;
while(pNode != NULL)
{
pNode = pNode->next;
++count;
}
return count;
}
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
int size1,size2,min,max,value,value1,value2,fillout = 0;
ListNode *pNode;
pNode = Create();
size1 = Size(l1);
size2 = Size(l2);
if(size1 >= size2)
{
max = size1;
min = size2;
}
else
{
max = size2;
min = size1;
}
for(int i = 1, j = 1 ; i <= max; i++,j++)
{
if(size1 >= size2)
{
value1 = Read(l1,i);
if(j <= min)
{
value2 = Read(l2,j);
}
else
{
value2 = 0;
}
}
else
{
value1 = Read(l2,i);
if(j <= min)
{
value2 = Read(l1,j);
}
else
{
value2 = 0;
}
}
value = value1 + value2 + fillout;
if(value >= 10)
{
value = value % 10;
Insert(pNode,value );
fillout = 1;
}
else
{
Insert(pNode,value );
fillout = 0;
}
}
if(fillout == 1)
{
Insert(pNode,fillout);
}
return pNode->next;
}
};//others code
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2)
{
int c = 0;
ListNode newHead(0);
ListNode *t = &newHead;
while(c || l1 || l2)
{
c += (l1? l1->val : 0) + (l2? l2->val : 0);
t->next = new ListNode(c%10);
t = t->next;
c /= 10;
if(l1) l1 = l1->next;
if(l2) l2 = l2->next;
}
return newHead.next;
}
};ListNode(int x) : val(x), next(NULL) {}
The pseudocode is as following(本题算法伪代码如下):
- Initialize current node to dummy head of the returning list.
- Initialize carry to 0.
- Initialize p and q to head of l1 and l2 respectively.
- Loop through lists l1 and l2 until you reach both ends.
- Set x to node p's value. If p has reached the end of l1, set to 0.
- Set y to node q's value. If q has reached the end of l2, set to 0.
- Set sum=x+y+carry.
- Update carry=sum/10.
- Create a new node with the digit value of (summod10)(summod10) and set it to current node's next, then advance current node to next.
- Advance both p and q.
- Check if carry=1, if so append a new node with digit 1 to the returning list.
- Return dummy head's next node.
Note that we use a dummy head to simplify the code. Without a dummy head, you would have to write extra conditional statements to initialize the head's value.
3. Longest Substring Without Repeating Characters
大致说一下题:
要求:给一个字符串,求其中最长无重复字符的子串的长度
例子:
给出"abcabcbb",符合要求的子串是"abc", 其长度为 3.
给出"bbbbb", 符合要求的子串是 "b", 其长度为1.
给出"pwwkew",符合要求的子串是 "wke", 其长度为 3.
注意答案要求的是子串, 因此上面的例子中"pwke" 是一个字字符序列,而不是一个子串.
算法思路:这里面需要做两件事情
第一是需要能够判别出前面重复出现过的字符。
第二是需要统计未重复出现的连续字符长度,并且其中最长的作为结果。
我的代码(思路):
采取的是超级笨的办法,用一个新的字符串变量收集遍历的字符,如果没有出现,就加进去,并统计新子串的长度,如果重复出现了,将遍历的起始位置加一,重新统计,算算时间复杂度,几乎达到n^3,真是愚蠢。虽然结果正确,但是对于较长的字符,效率较低,因此提交的时候未能通过。。。
//My code
class Solution {
public:
bool IsInclude(string s,char a)
{
int len = s.size();
int i = 0;
while(i < len)
{
if(s[i] == a)
return true;
i++;
}
return false;
}
int lengthOfLongestSubstring(string s) {
int len, lensub, i, j;
int maxlensub = 0;
len = s.size();
string substring = "";
for(int i = 0; i < len; i++)
{
substring += s[i];
if(maxlensub < 1)
maxlensub = 1;
for(int j = i + 1; j < len; j++)
{
if(false == IsInclude(substring,s[j]))
{
substring += s[j];
}
else
{
substring = "";
break;
}
lensub = substring.size();
if(maxlensub < lensub)
maxlensub = lensub;
if(maxlensub >= len - i)
return maxlensub;
}
}
return maxlensub;
}
};别人优秀的代码(思路):
对于需要判别重复出现的字符这个要求,怎样才能做到呢,别人给出的一种巧妙的方法。我们知道,每个字符所对应的ASCII码是不同的,因此我们完全可以申请一个可以统计所有字符大小(比如256?)的空间的数组或vector容器。一开始的时候,我们给定他们一个统一的标记-1,然后再遍历给定的字符串,在遍历的过程中,判断该字符对应的ACSII码的位置是否为-1,如果为-1,说明前面没有出现过,我们给他重新作标记,以表示出现了,如果不为-1,说明该字符前面出现过,这样我们需要作别的处理,这个处理的目的就是为了下面做的事,也就是统计最长子串所做。
那么该怎么统计最长子串的长度呢:
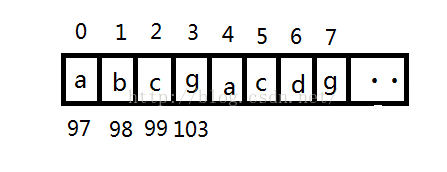
假设我们的字符串s为adcgacdg:
申请一个vector<int> dict(256,-1); dict存储着int型的变量,且初始大小为256,全部赋值为-1,这个-1是辨识是否重复的标记。再创建maxlen变量统计最长子串,初始化为0,start变量统计最初的位置,初始化为-1;接着走一个for循环,从头到尾遍历字符串,循环体里首先判断dict[s[i]]>start;对于第一个字符a,s[i]=97,dict[97]=-1;判断不成立,也就是a字符前面没出现过,但是呢,现在出现了,所以dict[97]现在不能再为-1了,否则下次再出现a判断的结果还是不成立,我们给dict[97]=0,也就是代表a在字符串中的序号值,接着计算maxlen,这里的表达式为maxlen = max(maxlen,i - start)。0-(-1)=1,这个表达式用的很妙。其实这里strat和序号i可以算是两个哨兵,一个站在我们当前要计算的子串的前面一个位置(注意不包括),一个站在我们当前要计算的子串的最后面的位置(这里是包括的,他们的差正好是串的长度)。就这样遍历下去,得到dict[98]=1,dict[99]=2,dict[103]=3,一直到i=4,这里判断dict[97]>start。0>-1,判断成立,也就是说前面出现了a,这是可怎么办呢,好办,我们把出现在前面出现的a的前面的字符全部除掉,再接着后面不包括这个出现的a的部分继续统计,这样做能行得通是因为前面计算maxlen时是取前一次的maxlen和当前的串里面大的数,因此即便前面截去了很大一部分也没有关系,他的值还保留着,知道后面有一个更大的来取代他。那么我们该怎么截去呢,更简单不过了,把前面的那个哨兵start移到a的位置上来即可。
看下面的代码,区区9行就实现了要求,而且时间复杂度为o(n),简直是神来之笔啊。
int lengthOfLongestSubstring(string s) {
vector<int> dict(256, -1);
int maxLen = 0, start = -1;
for (int i = 0; i != s.length(); i++) {
if (dict[s[i]] > start)
start = dict[s[i]];
dict[s[i]] = i;
maxLen = max(maxLen, i - start);
}
return maxLen;
}














 2926
2926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









