






说明
该项目为2020年,国赛数学建模,本学长帮助同学完成,共带5队,3个一等奖,2个二等奖,今天带大家进行复盘。
本次复盘非提供给同学的参赛项目,这里只做基础的简单分析,参赛作品不给予提供。
数据
数据一用提供了3个csv文件:
- 附件1:123家有信贷记录企业的相关数据.xlsx
- 附件2:302家无信贷记录企业的相关数据.xlsx
- 附件3:银行贷款年利率与客户流失率关系的统计数据.xlsx
观察数据
import pandas as pd
import numpy as np
df1_1 = pd.read_excel('../data/附件1:123家有信贷记录企业的相关数据.xlsx',sheet_name=0)
df1_2 = pd.read_excel('../data/附件1:123家有信贷记录企业的相关数据.xlsx',sheet_name=1)
df1_3 = pd.read_excel('../data/附件1:123家有信贷记录企业的相关数据.xlsx',sheet_name=2)
df2_1 = pd.read_excel('../data/附件2:302家无信贷记录企业的相关数据.xlsx',sheet_name=0)
df2_2 = pd.read_excel('../data/附件2:302家无信贷记录企业的相关数据.xlsx',sheet_name=1)
df2_3 = pd.read_excel('../data/附件2:302家无信贷记录企业的相关数据.xlsx',sheet_name=2)
df3 = pd.read_excel('../data/附件3:银行贷款年利率与客户流失率关系的统计数据.xlsx',sheet_name=0)
display(df1_1.head())
display(df1_2.head())
display(df1_3.head())

display(df2_1.head())
display(df2_2.head())
display(df2_3.head())

建模
每个企业生存年限
'''
每家公司的成立年限,第一张发票时间到最后一张发票时间的差值,以月为单位
'''
# 支出表生存年限
live_time2 = df1_2[['企业代号','开票日期']]
live_time2_min = live_time2.groupby('企业代号').min().reset_index()
live_time2_max = live_time2.groupby('企业代号').max().reset_index()
live_time2 = pd.merge(live_time2_max,live_time2_min,on='企业代号')
live_time2['生存年限1'] = live_time2['开票日期_x'] - live_time2['开票日期_y']
# 收入表生存年限
live_time3 = df1_3[['企业代号','开票日期']]
live_time3_min = live_time3.groupby('企业代号').min().reset_index()
live_time3_max = live_time3.groupby('企业代号').max().reset_index()
live_time3 = pd.merge(live_time3_max,live_time3_min,on='企业代号')
live_time3['生存年限2'] = live_time3['开票日期_x'] - live_time3['开票日期_y']
# 找出生存年限最大的值作为生存年限
live_time = pd.merge(live_time2,live_time3,on='企业代号')[['企业代号','生存年限1','生存年限2']]
x1 = list(live_time['生存年限1'])
x2 = list(live_time['生存年限2'])
x = []
for i in range(len(x1)):
if x1[i] >= x2[i]:
x.append(x1[i])
else:
x.append(x2[i])
company_id = pd.DataFrame(live_time['企业代号'])
x = pd.DataFrame(x,columns=['生存年限'])
live_time = company_id.join(x)
# 生存年限转为月份
live_time['生存年限'] = live_time['生存年限'].astype(str)
live_time['生存年限'] = live_time['生存年限'].str.split().str.get(0)
live_time['生存年限'] = live_time['生存年限'].map(lambda x: str(int(x) // 30) + '月')
live_time.head()
客户量
计算收入的发票数有多少
ustomer = df1_3[['企业代号','购方单位代号','发票状态']]
customer = customer[customer['发票状态'] == '有效发票']
customer = customer.drop_duplicates(subset=['企业代号','购方单位代号'])
customer = customer.groupby('企业代号')['购方单位代号'].count().reset_index()
customer.rename(columns={'购方单位代号': '客户数'},inplace=True)
customer.head()
公司类别
# 查看公司名字中都有哪些词
company = df1_1[['企业代号','企业名称']]
company_name = list(company['企业名称'])
company_name = ' '.join(company_name).replace('*','').\
replace('有限公司','').replace('责任公司','').\
replace('分公司','')
# 词云
import jieba
import wordcloud
from scipy.misc import imread
w = wordcloud.WordCloud(background_color = 'white',
width = 1000,height = 700,
font_path = 'msyh.ttc',
)
w.generate(company_name)
w.to_file('../output/公司名称词云.png')
# 定义企业类型,销项,中小微
table = {
'餐饮业':{'销项价税合计(年)':{'中':[2000,'正无穷'],
'小':[100,2000],
'微':['负无穷',100]}},
'仓储业':{'销项价税合计(年)':{'中':[1000,'正无穷'],
'小':[100,1000],
'微':['负无穷',100]}},
'信息传输业':{'销项价税合计(年)':{'中':[1000,'正无穷'],
'小':[100,1000],
'微':['负无穷',100]}},
'软件和信息技术服务业':{'销项价税合计(年)':{'中':[1000,'正无穷'],
'小':[50,1000],
'微':['负无穷',50]}},
'房地产开发经营':{'销项价税合计(年)':{'中':[5000,'正无穷'],
'小':[2000,5000],
'微':['负无穷',2000]}},
'物业管理':{'销项价税合计(年)':{'中':[1000,'正无穷'],
'小':[500,1000],
'微':['负无穷',500]}},
'租赁和上午服务业':{'销项价税合计(年)':{'中':[8000,'正无穷'],
'小':[100,8000],
'微':['负无穷',100]}},
'农林牧渔业':{'销项价税合计(年)':{'中':[500,'正无穷'],
'小':[50,500],
'微':['负无穷',50]}},
'工业':{'销项价税合计(年)':{'中':[2000,'正无穷'],
'小':[300,2000],
'微':['负无穷',300]}},
'建筑业':{'销项价税合计(年)':{'中':[5000,'正无穷'],
'小':[300,5000],
'微':['负无穷',300]}},
'批发业':{'销项价税合计(年)':{'中':[5000,'正无穷'],
'小':[1000,5000],
'微':['负无穷',1000]}},
'零售业':{'销项价税合计(年)':{'中':[500,'正无穷'],
'小':[100,500],
'微':['负无穷',100]}},
'交通运输业':{'销项价税合计(年)':{'中':[3000,'正无穷'],
'小':[200,3000],
'微':['负无穷',200]}},
'邮政业':{'销项价税合计(年)':{'中':[2000,'正无穷'],
'小':[100,2000],
'微':['负无穷',100]}},
'住宿业':{'销项价税合计(年)':{'中':[2000,'正无穷'],
'小':[100,2000],
'微':['负无穷',100]}},
'其他':{'销项价税合计(年)':{'中':[2562,'正无穷'],
'小':[325,2562],
'微':['负无穷',325]}},
}
if ('工程' in s):
return '建筑业'
if ('木' in s) or ('林' in s) or ('花' in s) or ('农' in s):
return '农、林、牧、渔业'
if ('矿' in s):
return '采矿业'
else:
return '其他'
company['企业类别'] = company['企业名称'].map(kind)
company

信誉等级时序图
ank = df1_3[df1_3['发票状态'] == '有效发票']
rank = rank[['企业代号','开票日期','价税合计']]
# 开票日期转换为年月
rank['year'] = rank['开票日期'].dt.year
rank['year'] = rank['year'].astype(str)
rank['month'] = rank['开票日期'].dt.month
rank['month'] = rank['month'].astype(str)
rank['开票日期'] = rank['year'] + '-' + rank['month']
rank = rank.groupby(['企业代号','开票日期'])['价税合计'].sum().reset_index()
rank = pd.merge(rank,df1_1,on='企业代号',how='left')
rank.head()

rank_a = rank[rank['信誉评级'] == 'A']
import seaborn as sns
import matplotlib.pyplot as plt
# 设置这些配置,图标才能正常显示
#%matplotlib inline # 让图表直接在 jupyter notebook 中展现出来
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题
plt.rcParams['axes.unicode_minus'] = False # 解决负号无法正常显示的问题
%config InlineBackend.figure_format = 'svg' # 将图标设置成矢量图格式显示,会更清晰
plt.style.use('ggplot') # 设置绘图样式
#display(plt.style.available) # 风格
fig = plt.figure(figsize=(5,4), dpi=100)
sns_line_a=sns.lineplot(x="开票日期", y="价税合计",
hue="企业代号",data=rank_a,
markers=True, dashes=False)
sns_line_a

rank_b = rank[rank['信誉评级'] == 'B']
fig = plt.figure(figsize=(5,4), dpi=100)
sns_line_b=sns.lineplot(x="开票日期", y="价税合计",
hue="企业代号",data=rank_b,
markers=True, dashes=False)
sns_line_b

rank_c = rank[rank['信誉评级'] == 'C']
fig = plt.figure(figsize=(5,4), dpi=100)
sns_line_c=sns.lineplot(x="开票日期", y="价税合计",
hue="企业代号",data=rank_c,
markers=True, dashes=False)
sns_line_c

rank_d = rank[rank['信誉评级'] == 'D']
fig = plt.figure(figsize=(5,4), dpi=100)
sns_line_d=sns.lineplot(x="开票日期", y="价税合计",
hue="企业代号",data=rank_d,
markers=True, dashes=False)
sns_line_d

企业进项,作废发票数,有效发票数
bill_outcome = df1_2[['企业代号','价税合计','发票状态']]
# 有效发票数
yes_bill_outcome = bill_outcome[bill_outcome['发票状态'] == '有效发票']
yes_bill_outcome = yes_bill_outcome.groupby('企业代号')['发票状态'].count()
yes_bill_outcome = yes_bill_outcome.reset_index()
# 作废发票数
no_bill_outcome = bill_outcome[bill_outcome['发票状态'] == '作废发票']
no_bill_outcome = no_bill_outcome.groupby('企业代号')['发票状态'].count()
no_bill_outcome = no_bill_outcome.reset_index()
# 进项有效,作废发票数汇总
bill_outcome = pd.merge(yes_bill_outcome,no_bill_outcome,on='企业代号',
how='left')
bill_outcome.rename(columns={'发票状态_x' : '进项有效发票数',
'发票状态_y' : '进项作废发票数'},
inplace=True)
bill_outcome.head()

企业销项作废发票数,有效发票数
bill_income = df1_3[['企业代号','价税合计','发票状态']]
# 有效发票数
yes_bill_income = bill_income[bill_income['发票状态'] == '有效发票']
yes_bill_income = yes_bill_income.groupby('企业代号')['发票状态'].count()
yes_bill_income = yes_bill_income.reset_index()
# 作废发票数
no_bill_income = bill_income[bill_income['发票状态'] == '作废发票']
no_bill_income = no_bill_income.groupby('企业代号')['发票状态'].count()
no_bill_income = no_bill_income.reset_index()
# 进项有效,作废发票数汇总
bill_income = pd.merge(yes_bill_income,no_bill_income,on='企业代号',
how='left')
bill_income.rename(columns={'发票状态_x' : '销项有效发票数',
'发票状态_y' : '销项作废发票数'},
inplace=True)
bill_income.head()

企业进项价,销项税合计
# 进项
outcome_sum = df1_2[['企业代号','价税合计']]
outcome_sum = outcome_sum.groupby('企业代号')['价税合计'].sum().reset_index()
# 销项
income_sum = df1_3[['企业代号','价税合计']]
income_sum = income_sum.groupby('企业代号')['价税合计'].sum().reset_index()
# 进项,销项汇总
outcome_income_sum = pd.merge(outcome_sum,income_sum,on='企业代号')
outcome_income_sum.rename(columns={'价税合计_x' : '进项价税合计',
'价税合计_y' : '销项价税合计'},inplace=True)
outcome_income_sum.head()

变量汇总
'''
字段为:企业代号,企业名称,信誉评级,是否违约,进项合计,销项合计,进项有效
发票数,进项作废发票数,销项有效发票数,进项作废发票数,成立时间,客户量
'''
import math
data = pd.merge(df1_1,live_time,on='企业代号')
data = pd.merge(data,customer,on='企业代号')
data = pd.merge(data,bill_outcome,on='企业代号')
data = pd.merge(data,bill_income,on='企业代号')
data = pd.merge(data,outcome_income_sum,on='企业代号')
data['利润'] = data['销项价税合计'] - data['进项价税合计']
data['生存年限'] = data['生存年限'].map(lambda x: int(x.replace('月','')))
data['生存年限'] = data['生存年限'].map(lambda x: math.ceil(x / 12))
data['收益率'] = (data['销项价税合计'] - data['进项价税合计']) / data['进项价税合计']
data['收益率'] = data['收益率'] / data['生存年限']
data.to_excel('../data/data.xlsx',encoding='utf8',index=False)
LCR 模型,KMeans 聚类
LCR 建模
data.head()

'''
LCR 模型变量选取
L 成立年限
C 客户数
R 收益率
'''
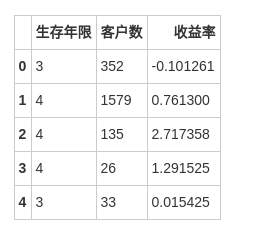
LCR = data[['生存年限','客户数','收益率']]
#LCR['生存年限'] = LCR['生存年限'].map(lambda x: int(x.replace('月','')))
LCR.head()
聚类模型对企业分类
'''
from sklearn.cluster import KMeans
kms = KMeans(n_clusters=4)
kms.fit(LCR)
label = kms.labels_
label = pd.DataFrame(list(label))
# 把企业类别汇总到 data.xlsx,并保存为 new_data.xlsx
data['种类'] = label
data.to_excel('../data/data_Kmeans.xlsx')
data.head()

聚类结果可视化
# 0 类型
kind_0 = data[data['种类'] == 0]
#kind_0['生存年限'] = kind_0['生存年限'].map(lambda x: int(x.replace('月','')))
kind_0 = kind_0[["生存年限","客户数","收益率"]].mean()
kind_0
# 1 类型
kind_1 = data[data['种类'] == 1]
#kind_1['生存年限'] = kind_1['生存年限'].map(lambda x: int(x.replace('月','')))
kind_1 = kind_1[["生存年限","客户数","收益率"]].mean()
kind_1
# 2 类型
kind_2 = data[data['种类'] == 2]
#kind_2['生存年限'] = kind_2['生存年限'].map(lambda x: int(x.replace('月','')))
kind_2 = kind_2[["生存年限","客户数","收益率"]].mean()
kind_2
kind_3 = data[data['种类'] == 3]
#kind_3['生存年限'] = kind_3['生存年限'].map(lambda x: int(x.replace('月','')))
kind_3 = kind_3[["生存年限","客户数","收益率"]].mean()
kind_3
# 雷达图
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.charts import Radar
value_0 = [
list(kind_0.values)
]
value_1 = [
list(kind_1.values)
]
value_2 = [
list(kind_2.values)
]
value_3 = [
list(kind_3.values)
]
c_schema = [
{"name": "成立年限", "max": 5, "min": 0},
{"name": "客户数", "max": 8500, "min": 0},
{"name": "收益率", "max": 4425, "min": 0},
]
c = (
Radar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_schema(schema=c_schema, shape="circle")
.add("0", value_0, color="#f9713c")
.add("1", value_1, color="#b3e4a1")
.add("2", value_2, color="#bd10e0")
.add("3", value_3, color="#FFFF00")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="企业聚类结果"))
)
c.render('../output/聚类结果.html')
c.render_notebook()

建立 KNN 分类模型预测附件2 企业等级
附件1最终数据作为训练集
data = data.fillna(0)
x_train = data.drop(columns=['企业代号','企业名称','信誉评级','是否违约','种类'])
y_train = data['信誉评级']
# 模型建立
from sklearn.neighbors import KNeighborsClassifier as KNN
knn = KNN(n_neighbors=2) # 当有一个新样本时,选取离他最近的 3 个,类别最多的,那新样本也属于这个类别
knn.fit(x_train,y_train)
# 预测准确度评估
an = knn.predict(x_train)
from sklearn.metrics import accuracy_score
score = accuracy_score(an, y_train)
score
附件2处理为需要用到的数据
'''
每家公司的成立年限,第一张发票时间到最后一张发票时间的差值,以月为单位
'''
# 支出表生存年限
live_time2 = df2_2[['企业代号','开票日期']]
live_time2_min = live_time2.groupby('企业代号').min().reset_index()
live_time2_max = live_time2.groupby('企业代号').max().reset_index()
live_time2 = pd.merge(live_time2_max,live_time2_min,on='企业代号')
live_time2['生存年限1'] = live_time2['开票日期_x'] - live_time2['开票日期_y']
# 收入表生存年限
live_time3 = df2_3[['企业代号','开票日期']]
live_time3_min = live_time3.groupby('企业代号').min().reset_index()
live_time3_max = live_time3.groupby('企业代号').max().reset_index()
live_time3 = pd.merge(live_time3_max,live_time3_min,on='企业代号')
live_time3['生存年限2'] = live_time3['开票日期_x'] - live_time3['开票日期_y']
# 找出生存年限最大的值作为生存年限
live_time = pd.merge(live_time2,live_time3,on='企业代号')[['企业代号','生存年限1','生存年限2']]
x1 = list(live_time['生存年限1'])
x2 = list(live_time['生存年限2'])
x = []
for i in range(len(x1)):
if x1[i] >= x2[i]:
x.append(x1[i])
else:
x.append(x2[i])
company_id = pd.DataFrame(live_time['企业代号'])
x = pd.DataFrame(x,columns=['生存年限'])
live_time = company_id.join(x)
# 生存年限转为月份
live_time['生存年限'] = live_time['生存年限'].astype(str)
live_time['生存年限'] = live_time['生存年限'].str.split().str.get(0)
live_time['生存年限'] = live_time['生存年限'].map(lambda x: str(int(x) // 30) + '月')
'''
客户量:计算收入的发票数有多少
'''
customer = df2_2[['企业代号','购方单位代号','发票状态']]
customer = customer[customer['发票状态'] == '有效发票']
customer = customer.drop_duplicates(subset=['企业代号','购方单位代号'])
customer = customer.groupby('企业代号')['购方单位代号'].count().reset_index()
customer.rename(columns={'购方单位代号': '客户数'},inplace=True)
'''
每个企业的进项,作废发票数,有效发票数
'''
bill_outcome = df2_3[['企业代号','价税合计','发票状态']]
# 有效发票数
yes_bill_outcome = bill_outcome[bill_outcome['发票状态'] == '有效发票']
yes_bill_outcome = yes_bill_outcome.groupby('企业代号')['发票状态'].count()
yes_bill_outcome = yes_bill_outcome.reset_index()
# 作废发票数
no_bill_outcome = bill_outcome[bill_outcome['发票状态'] == '作废发票']
no_bill_outcome = no_bill_outcome.groupby('企业代号')['发票状态'].count()
no_bill_outcome = no_bill_outcome.reset_index()
# 进项有效,作废发票数汇总
bill_outcome = pd.merge(yes_bill_outcome,no_bill_outcome,on='企业代号',
how='left')
bill_outcome.rename(columns={'发票状态_x' : '进项有效发票数',
'发票状态_y' : '进项作废发票数'},
inplace=True)
'''
每个企业的销项作废发票数,有效发票数
'''
bill_income = df2_3[['企业代号','价税合计','发票状态']]
# 有效发票数
yes_bill_income = bill_income[bill_income['发票状态'] == '有效发票']
yes_bill_income = yes_bill_income.groupby('企业代号')['发票状态'].count()
yes_bill_income = yes_bill_income.reset_index()
# 作废发票数
no_bill_income = bill_income[bill_income['发票状态'] == '作废发票']
no_bill_income = no_bill_income.groupby('企业代号')['发票状态'].count()
no_bill_income = no_bill_income.reset_index()
# 进项有效,作废发票数汇总
bill_income = pd.merge(yes_bill_income,no_bill_income,on='企业代号',
how='left')
bill_income.rename(columns={'发票状态_x' : '销项有效发票数',
'发票状态_y' : '销项作废发票数'},
inplace=True)
'''
每个企业进项价,销项税合计
'''
# 进项
outcome_sum = df2_2[['企业代号','价税合计']]
outcome_sum = outcome_sum.groupby('企业代号')['价税合计'].sum().reset_index()
# 销项
income_sum = df2_3[['企业代号','价税合计']]
income_sum = income_sum.groupby('企业代号')['价税合计'].sum().reset_index()
# 进项,销项汇总
outcome_income_sum = pd.merge(outcome_sum,income_sum,on='企业代号')
outcome_income_sum.rename(columns={'价税合计_x' : '进项价税合计',
'价税合计_y' : '销项价税合计'},inplace=True)
'''
变量汇总
'''
import math
data1 = pd.merge(df2_1,live_time,on='企业代号')
data1 = pd.merge(data1,customer,on='企业代号')
data1 = pd.merge(data1,bill_outcome,on='企业代号')
data1 = pd.merge(data1,bill_income,on='企业代号')
data1 = pd.merge(data1,outcome_income_sum,on='企业代号')
data1['利润'] = data1['销项价税合计'] - data1['进项价税合计']
data1['生存年限'] = data1['生存年限'].map(lambda x: int(x.replace('月','')))
data1['生存年限'] = data1['生存年限'].map(lambda x: math.ceil(x / 12))
data1['收益率'] = (data1['销项价税合计'] - data1['进项价税合计']) / data1['进项价税合计']
data1['收益率'] = data1['收益率'] / data['生存年限']
data1.to_excel('../data/data2.xlsx',encoding='utf8',index=False)

结束语
数学建模精选资料共享,研究生学长数模指导,建模比赛思路分享,关注我不迷路!
建模指导,比赛协助,有问必答,欢迎打扰















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









