









HashSet底层原理
JDK 1.6 中文API描述:
此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
此类为基本操作提供了稳定性能,这些基本操作包括 add、remove、contains 和 size,假定哈希函数将这些元素正确地分布在桶中。对此 set 进行迭代所需的时间与 HashSet 实例的大小(元素的数量)和底层 HashMap 实例(桶的数量)的“容量”的和成比例。因此,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
注意,此实现不是同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(…));
此类的 iterator 方法返回的迭代器是快速失败 的:在创建迭代器之后,如果对 set 进行修改,除非通过迭代器自身的 remove 方法,否则在任何时间以任何方式对其进行修改,Iterator 都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒将来在某个不确定时间发生任意不确定行为的风险。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器在尽最大努力抛出 ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误做法:迭代器的快速失败行为应该仅用于检测 bug。
HashSet的add(E e)方法源码解析:
首先,调用add(E e)方法:

可以看到add(E e)方法本身调用了map.put()方法,而这个map就是HashSet中的一个HashMap成员变量,定义如下所示:
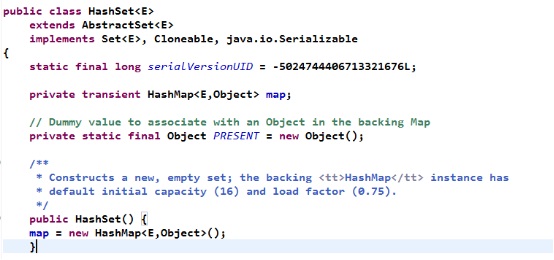
那么,进入map.put()方法的源码:
public V put(K key, V value) {
if (key == null)
// 执行key为空的put方法
return putForNullKey(value);
/* 以下两行代码作用是在hash表中检索//key的hash值的索引,具体HashMap.hash() 以及HashMap.indexFor()方法参见《Hash表的HashMap.hash()以及HashMap.indexFor()方法》,此处不描述。*/
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
/* 此处会根据检索出的索引i,找到hash表(元素为链表的数组)中下标为i的元素(某个链表对象),然后迭代遍历该链表对象中的每一个元素*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
/* 此处首先判断当前迭代元素的*hash值是否等于key的*hash值(*hash表示由 Map.hash()算法计算出的hash值)
相等:继续比较当前链表元素的引用的地址值是否相等
相等:再比较equals()方法
相等:将value值覆盖为新的value值,但是注意key值没有改变,即没有添加新的元素,而是常见的map集合值覆盖
以上比较任何一个不相等,则直接添加一个节点元素,执行 addEntry(hash, key, value, i)方法。*/
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++; // 更改了元素结构,操作计数
addEntry(hash, key, value, i);
return null;
}
那么,知道了HashSet的add(E e)方法能够保证元素唯一性的关键是hashCode()和Equals()两个方法,则重写E元素的这两个方法即可控制。
下面看下Hash表中元素的存储过程以及如何优化该过程:

在做成员变量的hash值相加时,可以让某个变乘以一个常量,这样防止 (变量a=2) + (变量b=3) = (变量a=1) +(变量b= 4) 的现象,即本身两个对象的成员变量不同,被重写的hashCode()方法返回值却相同的情况。















 5269
5269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









