








原英文地址: https://timebutt.github.io/static/understanding-yolov2-training-output/
最近有人问起在YOLOv2训练过程中输出在终端的不同的参数分别代表什么含义,如何去理解这些参数?本篇文章中我将尝试着去回答这个有趣的问题。
刚好现在我正在训练一个YOLOv2模型,拿这个真实的例子来讨论再合适不过了,下边是我训练中使用的 .cfg 文件(你可以在cfg文件夹下找到它):
以下是训练过程中终端输出的一个截图:
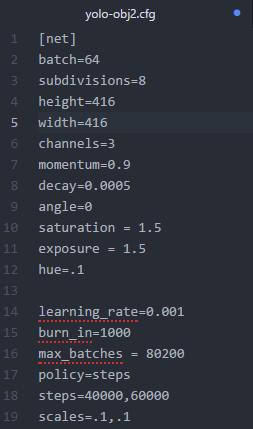

以上截图显示了所有训练图片的一个批次(batch),批次大小的划分根据我们在 .cfg 文件中设置的subdivisions参数。在我使用的 .cfg 文件中 batch = 64 ,subdivision = 8,所以在训练输出中,训练迭代包含了8组,每组又包含了8张图片,跟设定的batch和subdivision的值一致。
(注: 也就是说每轮迭代会从所有训练集里随机抽取 batch = 64 个样本参与训练,所有这些 batch 个样本又被均分为 subdivision = 8 次送入网络参与训练,以减轻内存占用的压力)
批输出
针对上图中最后一行中的信息,我们来一步一步的分析。如下的输出是由 detector.c 生成的,具体代码见:点击打开链接
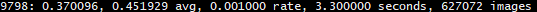
- 9798: 指示当前训练的迭代次数
- 0.370096: 是总体的Loss(损失)
- 0.451929 avg: 是平均Loss,这个数值应该越低越好,一般来说,一旦这个数值低于0.060730 avg就可以终止训练了。
- 0.001000 rate: 代表当前的学习率,是在.cfg文件中定义的。
- 3.300000 seconds: 表示当前批次训练花费的总时间。
- 627072 images: 这一行最后的这个数值是9798*64的大小,表示到目前为止,参与训练的图片的总量。
分块输出
在分析分块输出之前,我们得了解一下IOU(Intersection over Union,也被称为交并集之比:点击打开链接),这样就能理解为什么分块输出中的参数是一些重要且必须要输出的参数了。
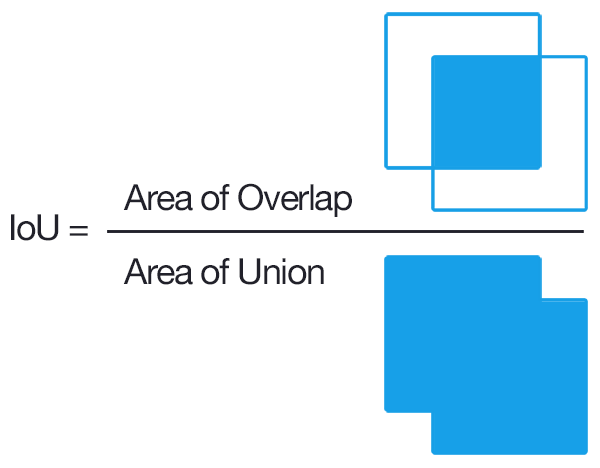
可以看到,IOU(交集比并集)是一个衡量我们的模型检测特定的目标好坏的重要指标。100%表示我们拥有了一个完美的检测,即我们的矩形框跟目标完美重合。很明显,我们需要优化这个参数。
回归正题,我们来分析一下这些用来描述训练图集中的一个批次的训练结果的输出。那些想自己深入源代码验证我所说的内容的同学注意了,这段代码:点击打开链接 执行了以下的输出:

- Region Avg IOU: 0.326577: 表示在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交集与并集之比,这里是32.66%,这个模型需要进一步的训练。
- Class: 0.742537: 标注物体分类的正确率,期望该值趋近于1。
- Obj: 0.033966: 越接近1越好。
- No Obj: 0.000793: 期望该值越来越小,但不为零。
- Avg Recall: 0.12500: 是在recall/count中定义的,是当前模型在所有subdivision图片中检测出的正样本与实际的正样本的比值。在本例中,只有八分之一的正样本被正确的检测到。
- count: 8:count后的值是所有的当前subdivision图片(本例中一共8张)中包含正样本的图片的数量。在输出log中的其他行中,可以看到其他subdivision也有的只含有6或7个正样本,说明在subdivision中含有不含检测对象的图片。
总结
在这篇短文里,我们回顾了一下YOLOv2在终端输出的不同的参数的含义,这些参数也在告诉我们YOLOv2的训练过程是怎样进行的。这个能在一定程度上解答大家关于YOLOv2的训练输出的大部分问题,但请记住,对YOLOv2的探索决不应该到此为止。
跟以往一样,欢迎大家在评论区留言,进一步讨论关于YOLOv2的相关问题,我也会不断优化改进这篇文章,所以,别忘了留言评论哦!原英文地址: https://timebutt.github.io/static/understanding-yolov2-training-output/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









