







生成DataFrame
在写代码时,我们会用到DataFrame来更直观的观察代码
当然在此之前,需要在第一行import所需要的各种包

生成数据后,用pd.DataFrame()但是这个表是简略版的,如果需要完整查看,就需要导出成CSV文件
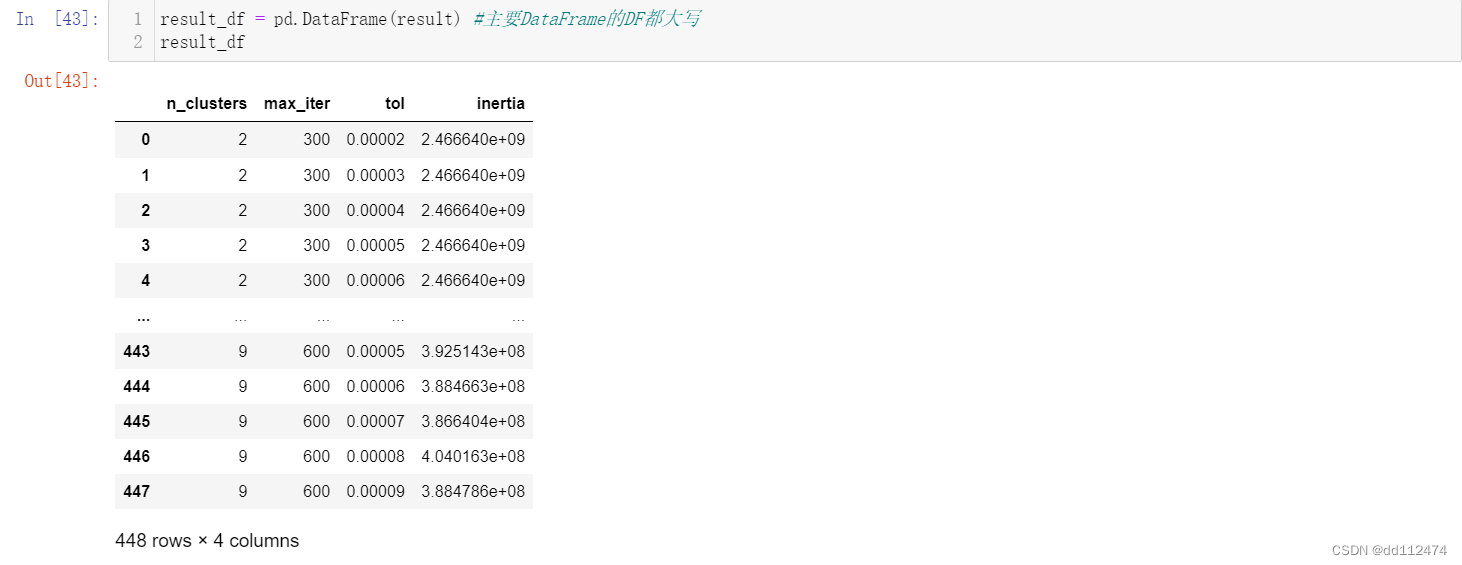
导出代码
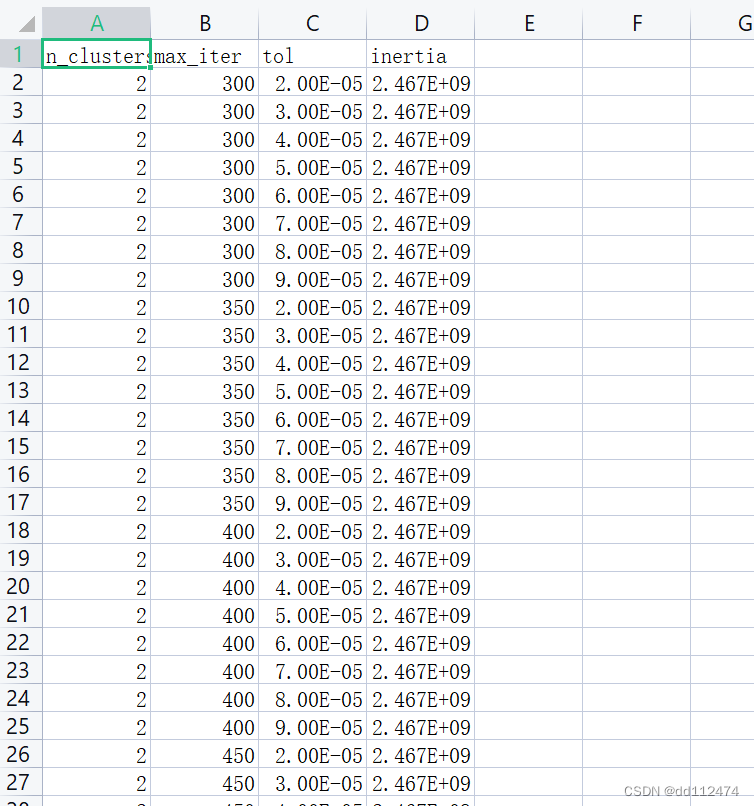
outputpath='C:/Users/DANNY/Desktop/DataFrame导出.csv'
result_df.to_csv(outputpath,sep=',',index=False,header=True)
其中1处是导出的位置,需要注意的是复制过来的是\要改成/
比如:C:\Users\DANNY\Desktop\ ----> C:/Users/DANNY/Desktop/
其中2处是导出文件的名称,可以自己取,我这里是叫DataFrame导出
其他outputpath = ' .csv'是不变的

第二行
result_df.to_csv(outputpath,sep=',',index=False,header=True)
只需要改变False和True即可,需要index就把index=False 改成 index=True
导出结果

参考链接(优质)
【Python】 DataFrame输出为csv\txt\xlsx文件
机器学习8
全文代码
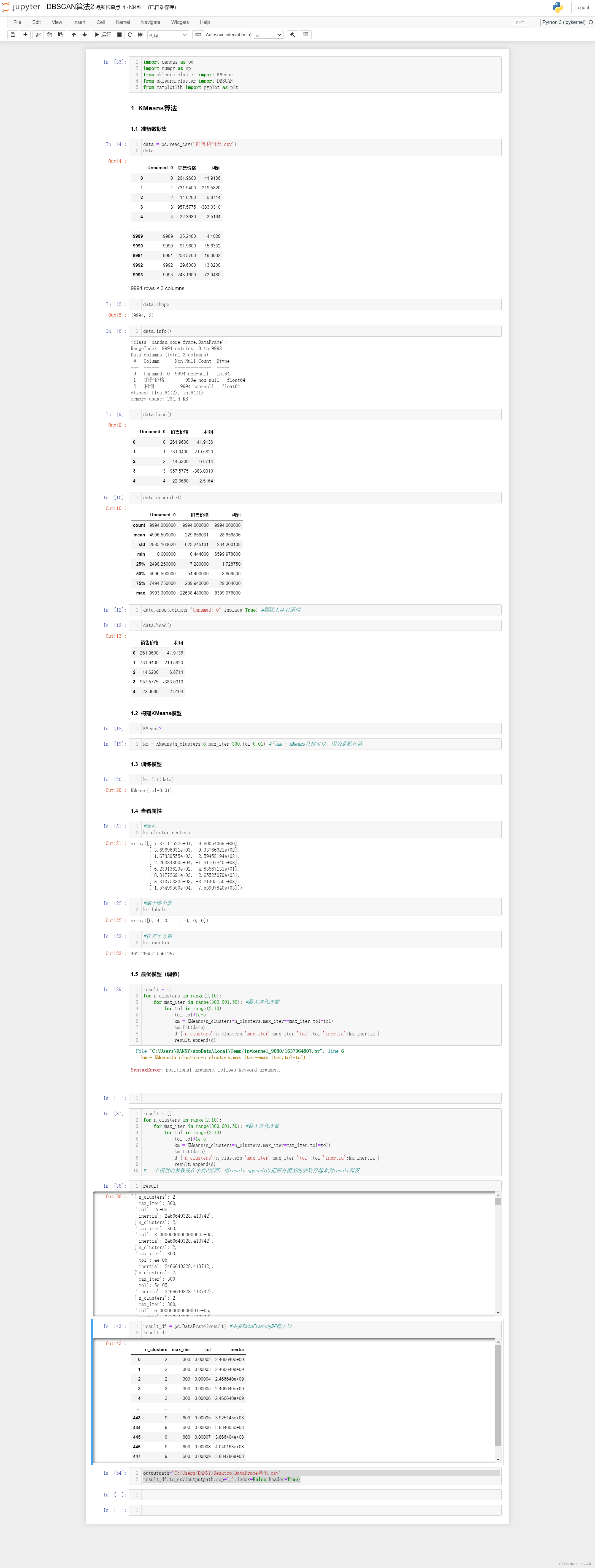
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN
from matplotlib import pyplot as plt
### KMeans算法
#### 准备数据集
data = pd.read_csv('销售利润表.csv')
data
data.shape
data.info()
data.head()
data.describe()
data.drop(columns="Unnamed: 0",inplace=True) #删除未命名那列
data.head()
#### 构建KMeans模型
KMeans?
km = KMeans(n_clusters=8,max_iter=300,tol=0.01) #写km = KMeans()也可以,因为是默认值
#### 训练模型
km.fit(data)
#### 查看属性
#质心
km.cluster_centers_
#属于哪个簇
km.labels_
#误差平方和
km.inertia_
#### 最优模型(调参)
result = []
for n_clusters in range(2,10):
for max_iter in range(300,601,50): #最大迭代次数
for tol in range(2,10):
tol=tol*1e-5
km = KMeans(n_clusters=n_clusters,max_iter==max_iter,tol=tol)
km.fit(data)
d={'n_clusters':n_clusters,'max_iter':max_iter,'tol':tol,'inertia':km.inertia_}
result.append(d)
result = []
for n_clusters in range(2,10):
for max_iter in range(300,601,50): #最大迭代次数
for tol in range(2,10):
tol=tol*1e-5
km = KMeans(n_clusters=n_clusters,max_iter=max_iter,tol=tol)
km.fit(data)
d={'n_clusters':n_clusters,'max_iter':max_iter,'tol':tol,'inertia':km.inertia_}
result.append(d)
# 一个模型的参数放在字典d里面,用result.append(d)把所有模型的参数存起来到result列表
result
result_df = pd.DataFrame(result) #主要DataFrame的DF都大写
result_df
outputpath='C:/Users/DANNY/Desktop/DataFrame导出.csv'
result_df.to_csv(outputpath,sep=',',index=False,header=True)














 8407
8407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









