






文章目录
文本分类主流模型
有监督学习(分类,回归)
logistic 分类
linear 回归(比分类多了一个激活函数)
分类模型–分类器(调优后)
单分类–多分类
单标签(二分类)–多标签
文本变为结构化数据 方法

Word Embedding(词向量)
1 word2vec
是一个模型 目前使用最广泛
使用算法:
LM(根据前面预测后面,没考虑到下文的语境)、
CBOW(根据两边的词预测中间的词)
Skip-gram(根据中间预测两边的词)

1.1 Language Model
某一个词出现的概率可以通过前面的词的词性、含义等推测它出现的概率
整句话出现的概率就是所有词出现概率的累乘
改进:ngram
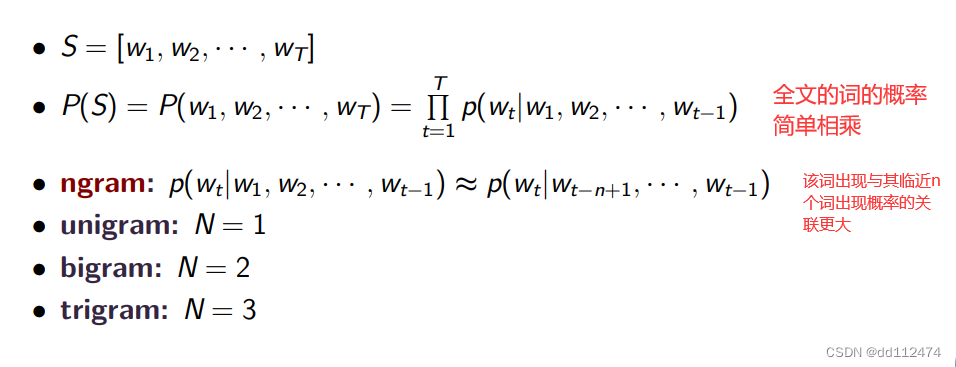
1.2 两个语义假设
根据词语词频和主题(一个词是否重要)
根据文章背景(一个词的语义)
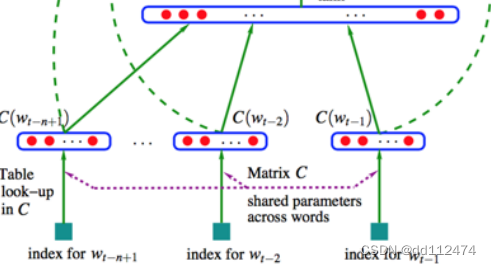
1.3 神经网络语言模型 NNbased LM
将每一个字与已有的字典对照(look up)抽象为一个向量,
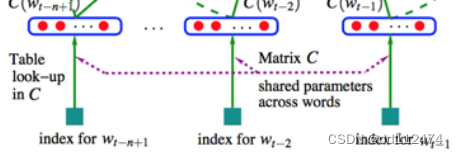
将三个词(字)组合,向量相加再取平均,3个3个一组不断学习
将上一步的向量进行分类(用多层感知机MLP预测下一个词是什么)
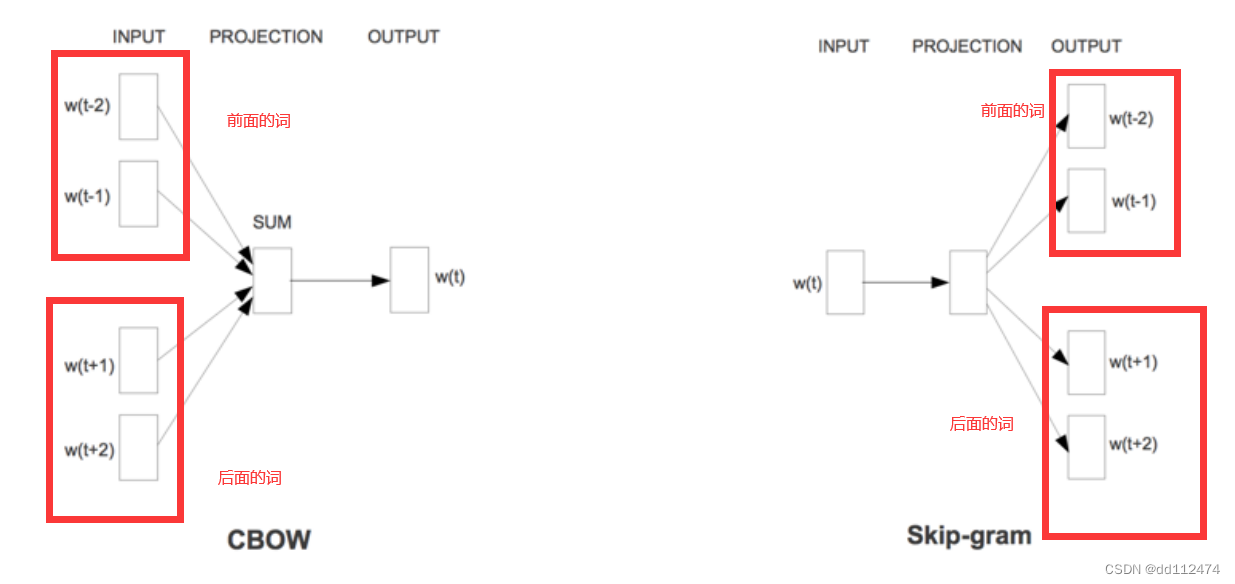
1.4 word2vec
诞生于2013年
CBOW(根据两边的词预测中间的词)
Skip-gram(根据中间预测两边的词)
只要用到神经网络都是有监督模型,
判断是否是有监督,无监督,首先判断每一步有无一个真实值和预测值比较
(因为自然语言预测没有一个标准的真实值,所以也可以说是 无监督学习)
检验效果:
看看生成的相似词是否真的有关联
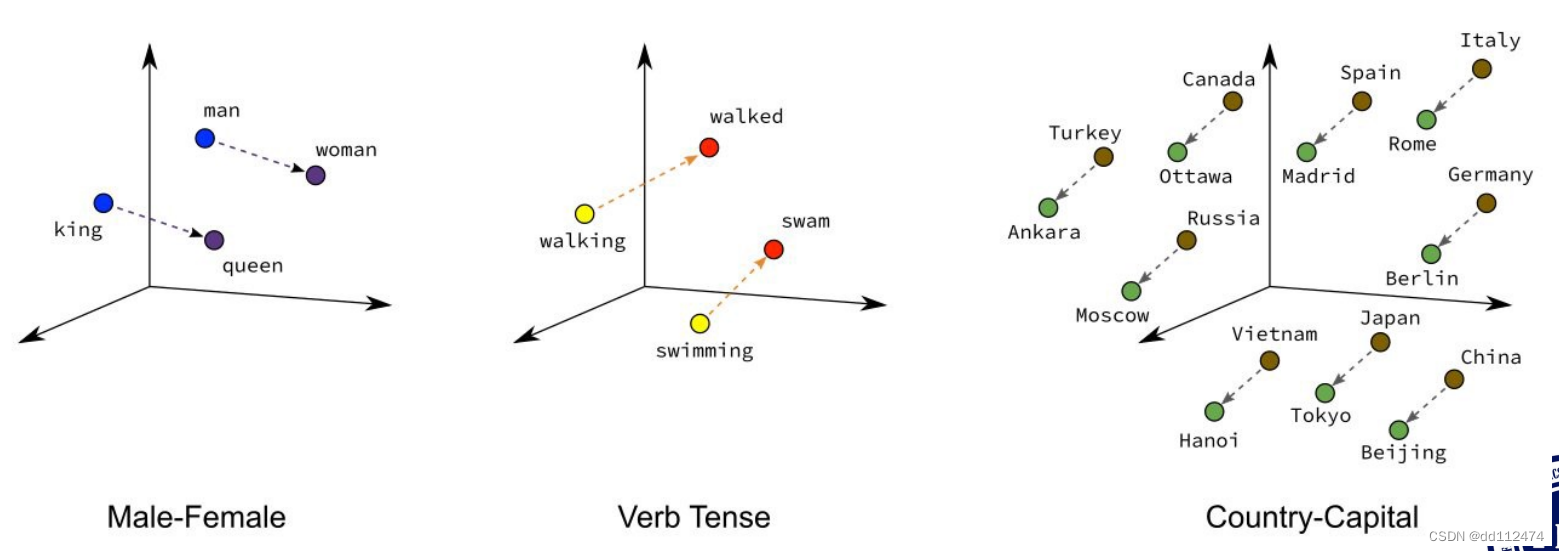
不用 去停用词(神经网络认为of 这些介词也有自己的含义)
不用 找词根 (因为语义效果均等)
2 GloVe
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性
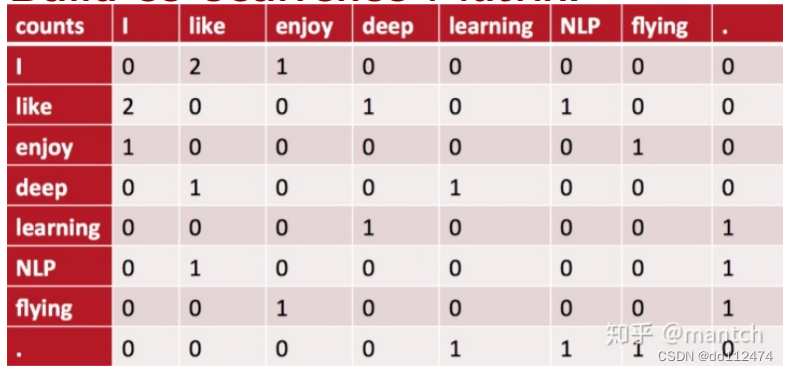
3 Fasttext
作为论文的baseline进行比较
过程和1.3的NNbased LM 过程一样
分类模型 Classfication Models
pre-process 预处理(分词、词性标注、取词根)
pre-train 预训练 (Word2vec模型、BERT模型)(训练的是无标签数据,无监督训练)
1 传统的文本分类
方法1:把一句话分词,用词向量空间模型将词转换成向量,通过多层感知机MLP得到一个结果output
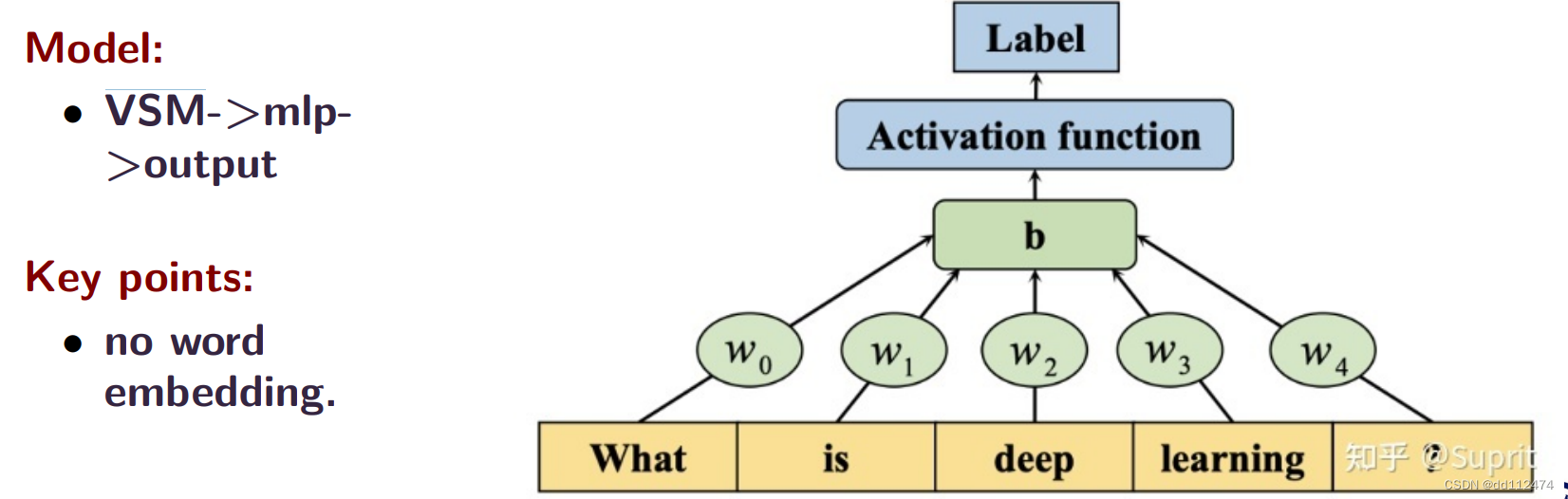
方法2:
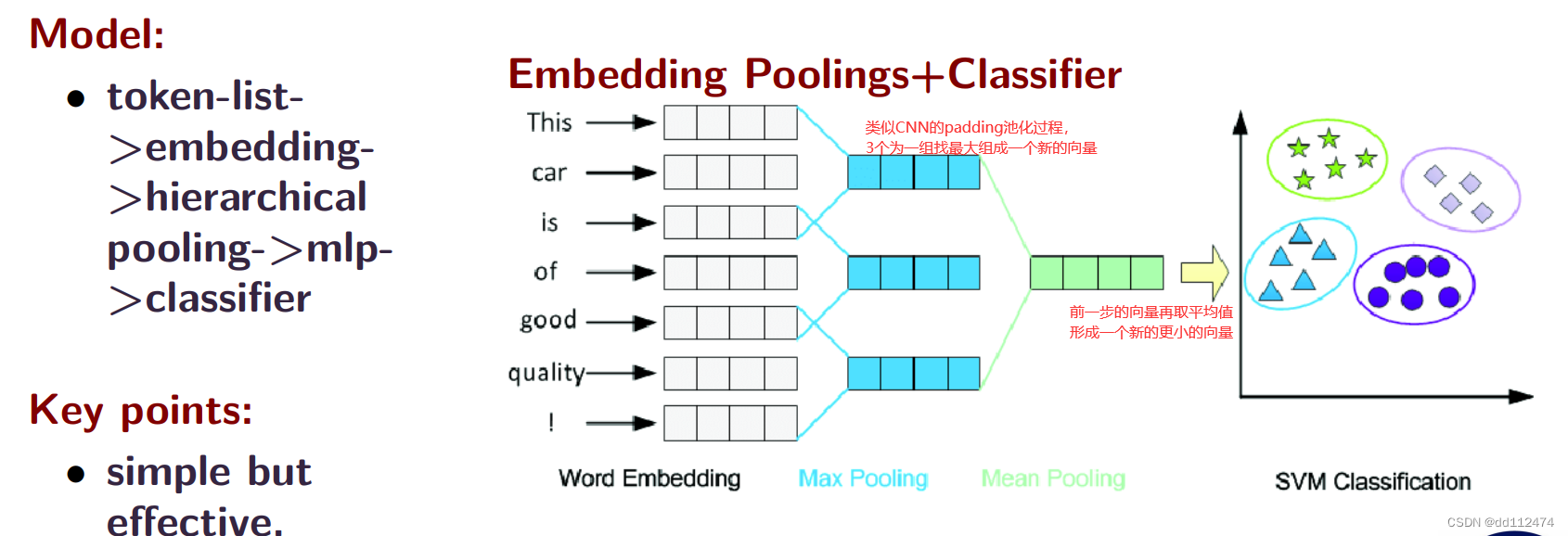
方法3:这个LSTM模型和方法1最大的不同是它考虑了词与词之间的顺序,方法2也考虑了一点点顺利
注意:这个方法原理很好,但最终效果不一定好,因为一句话的顺序有时候不是最重要的,关键词的语义可能更重要
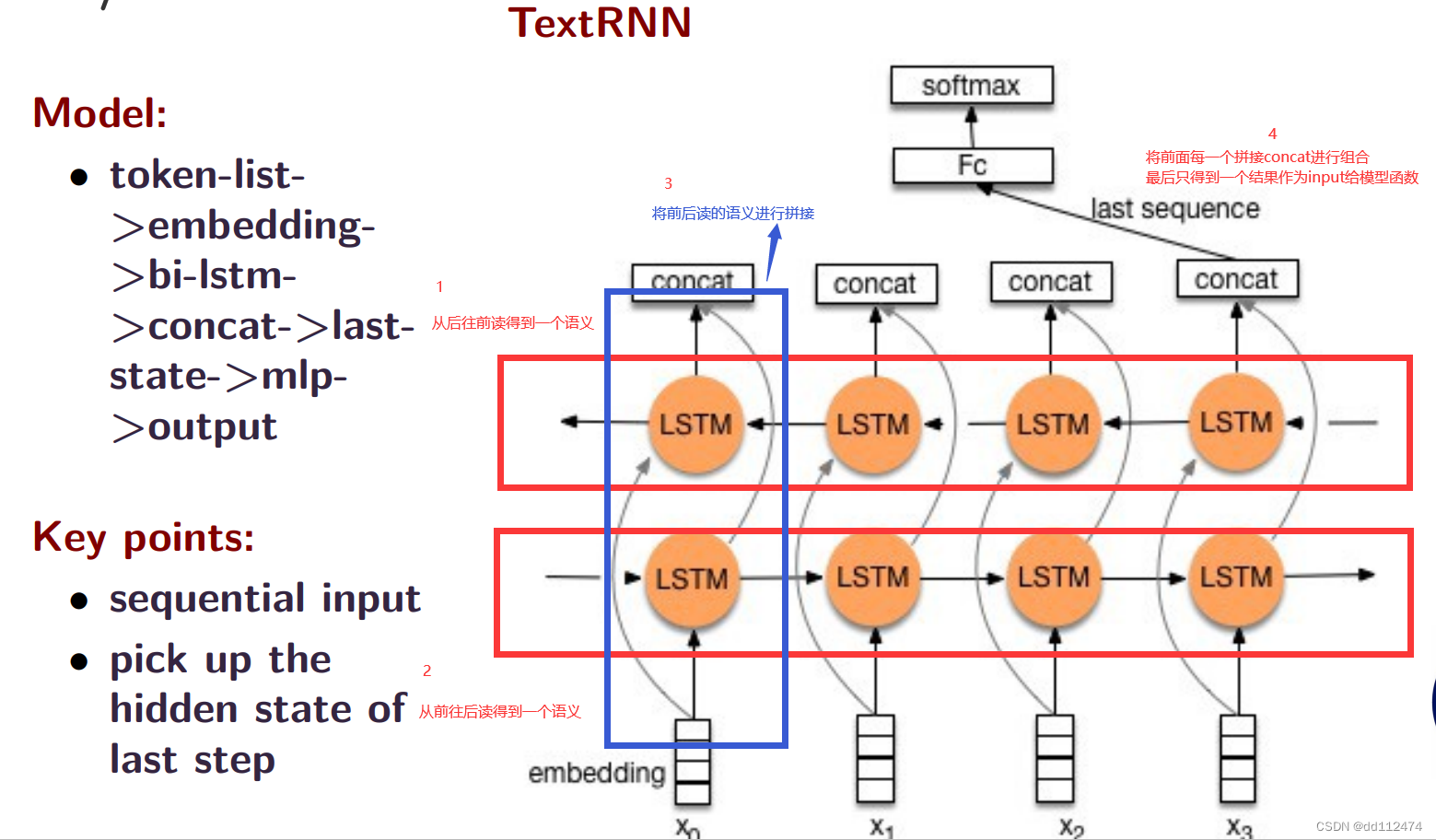
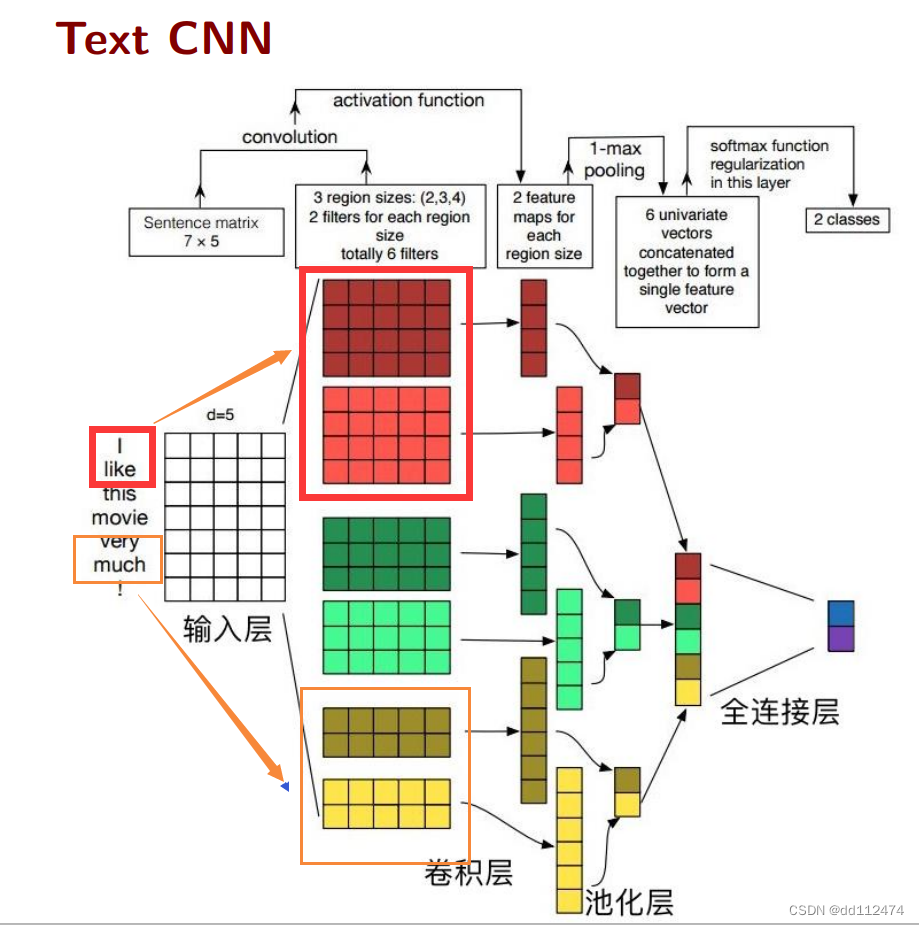
方法4:CNN (通过获取局部互相联系的信息)
与图片的CNN区别在于,卷积核的选择需要基于分词来来确定
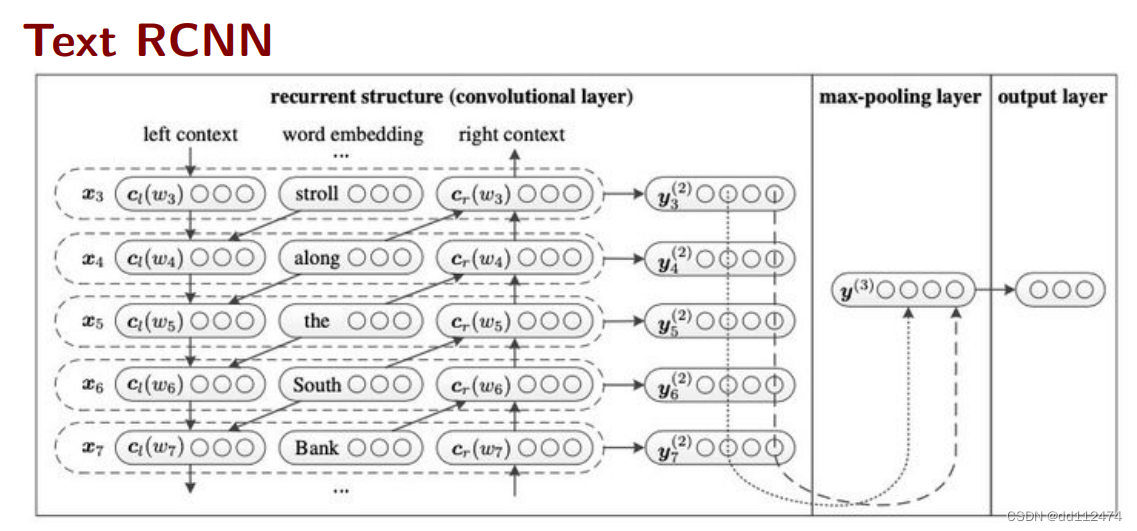
方法5:CNN+RNN融合
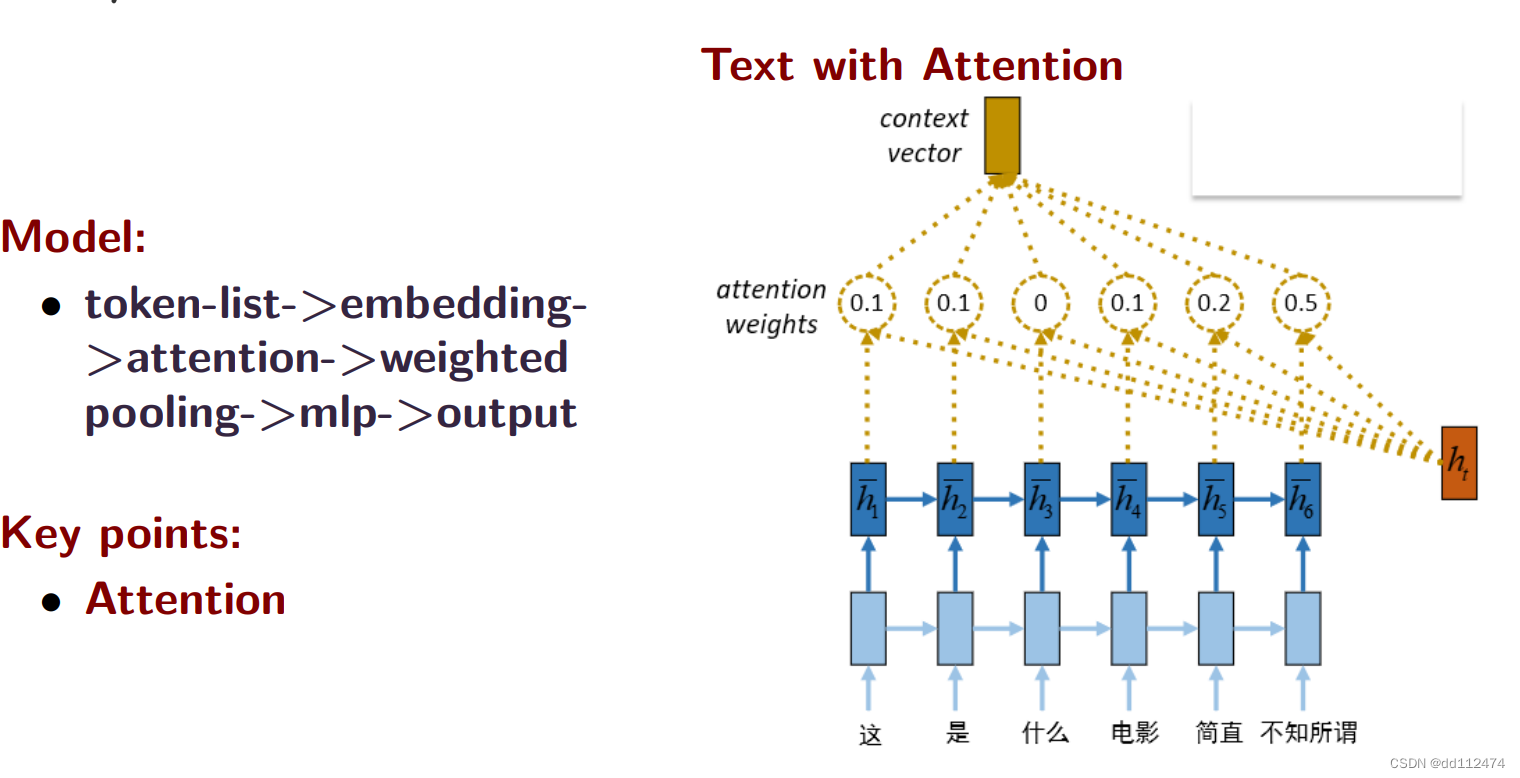
方法6:注意力机制Attention
引入一个额外的参数ht,与这个参数接近的就重要,不接近就不重要,对每个向量进行打分,得到一个修正的权重attention weights
CNN (局部),RNN(前后关系),LSTM(特征抽取),Attention(注意力机制)这几个可以随意组合来构建模型,只要能解释就行
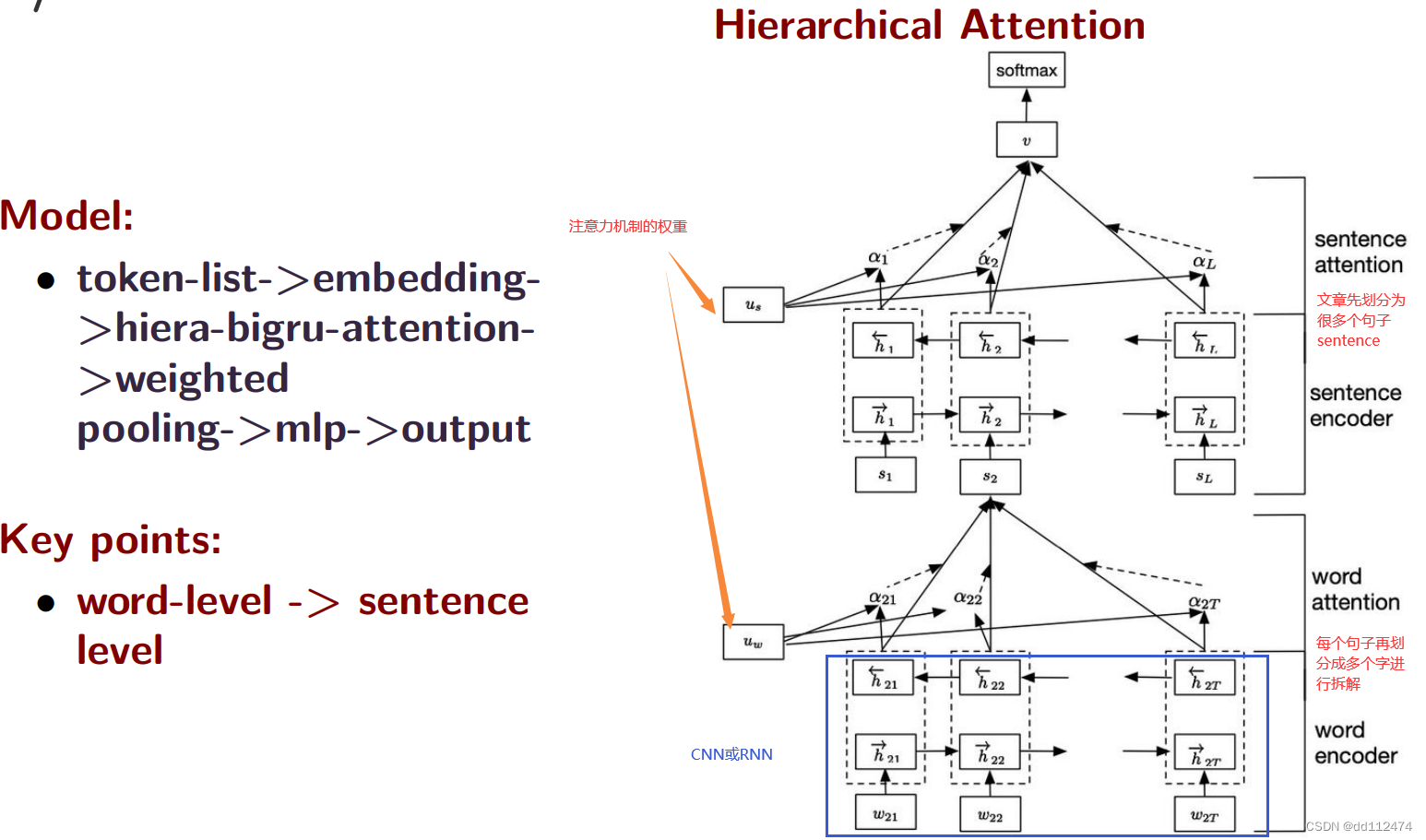
方法7:Hierarchical Attention 等级制分层的注意力机制
方法8:Multi-head self-Attention 自注意力机制(让注意力机制中的参数ht更合理)
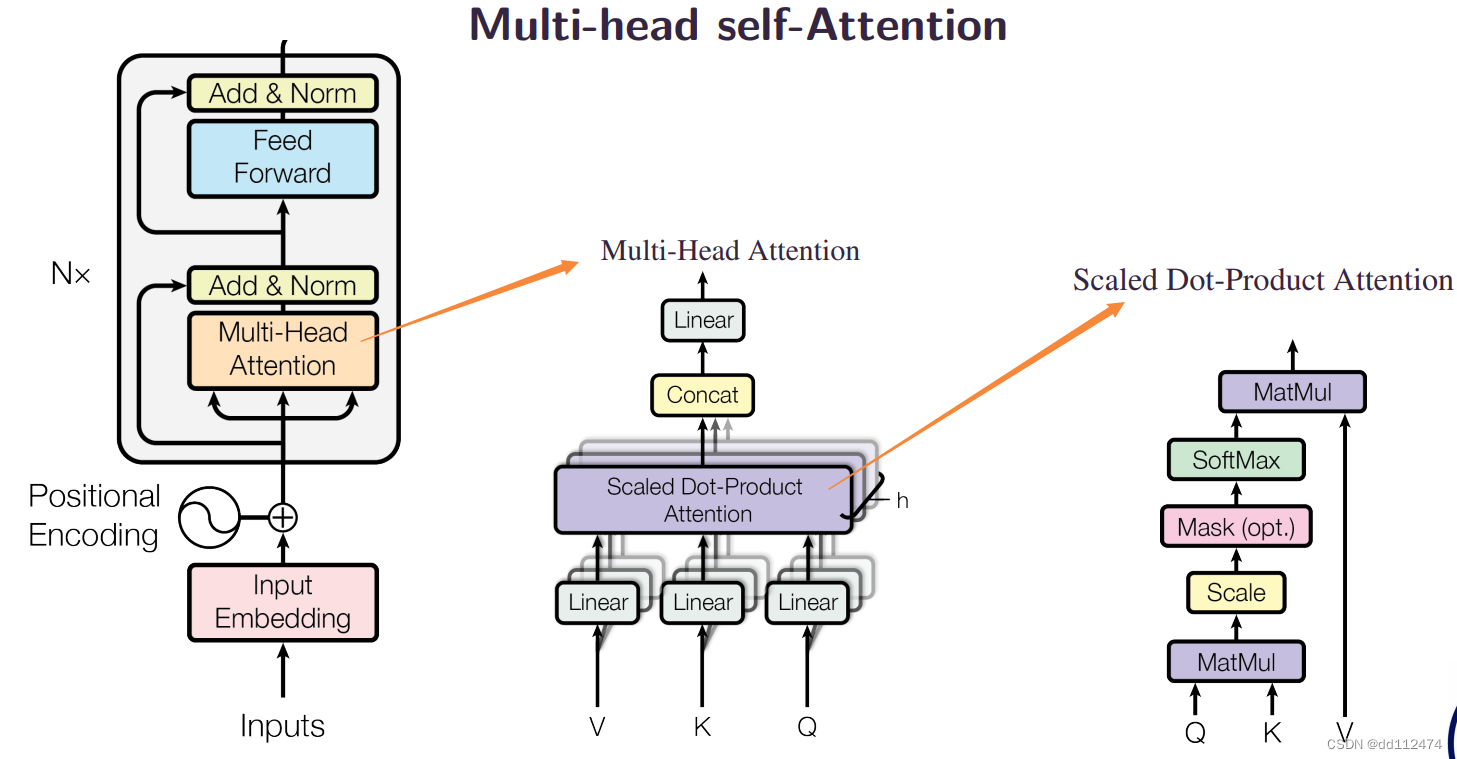
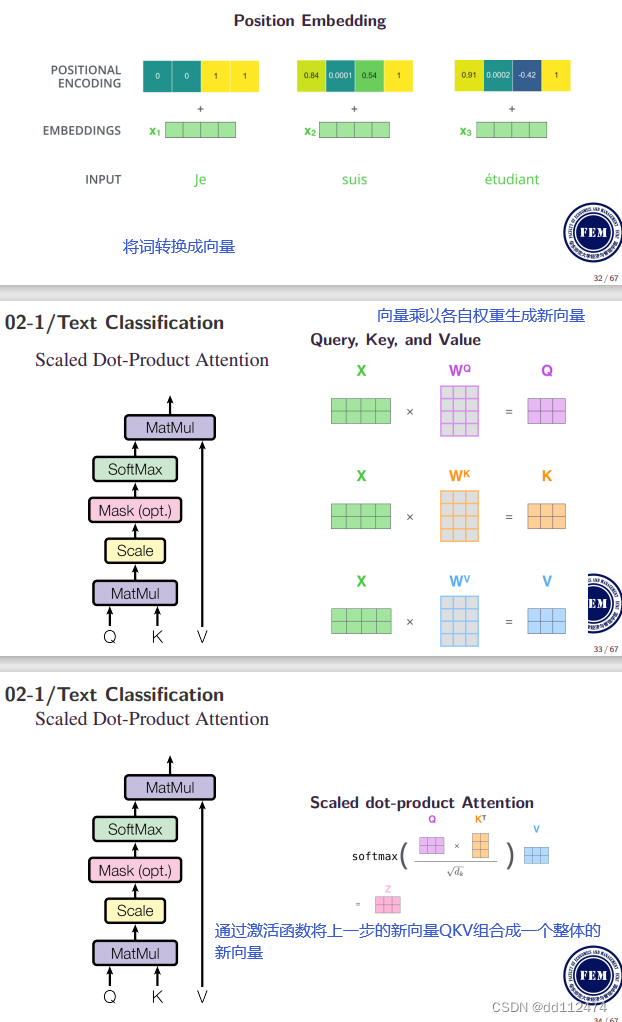
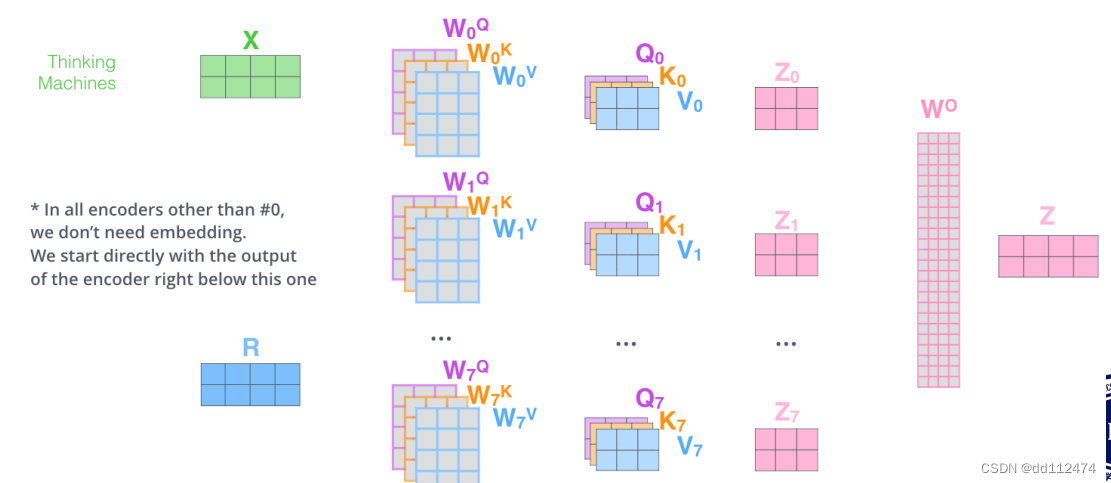
进行多次这样的运算就是muti-head
前面的词语的信息作为残差x,加到当前得到的f(x)后面,从而提高准确率
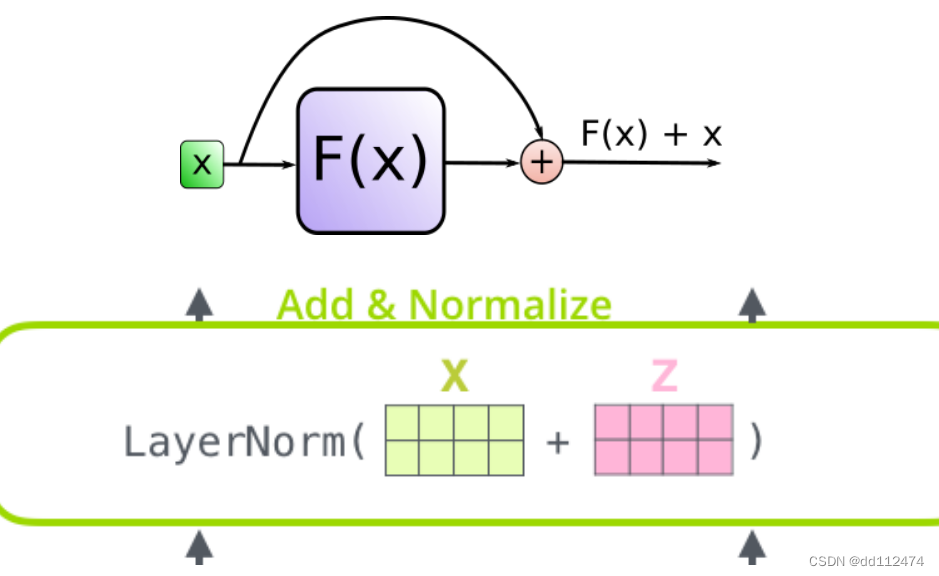
这个模型的缺陷:前面的所有的词的重要性都以一个x表示了,使得前面词语与当前词语的语序的顺序的重要性被忽略了
方法9:Pre-trained Language Models 预处理模型
BERT 和 ELMO 模型
2 情感分析Sentiment Analysis

3 模型实现
最推荐 pytorch
(更新后代码修改少)
4 模型评价
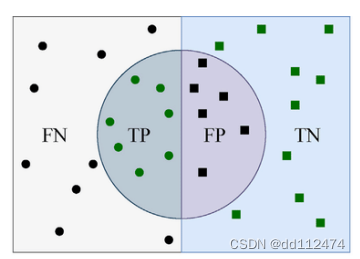
4.1 F1 score
用模型预测的准确性进行计算
链接:python计算准确率
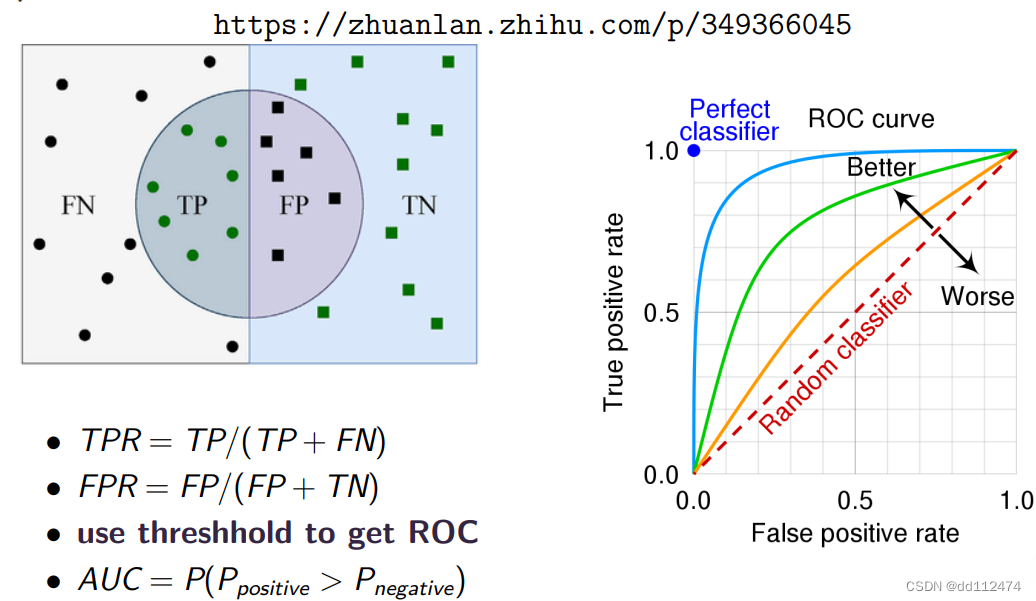
4.2 AUC
思考

工业、工作中更强调效率,学术强调模型创新
可解释性:
可解释性是指人类能够理解决策原因的程度。 机器学习模型的可解释性越高,人们就越容易理解为什么做出某些决定或预测。 模型可解释性指对模型内部机制的理解以及对模型结果的理解。 其重要性体现在:建模阶段,辅助开发人员理解模型,进行模型的对比选择,必要时优化调整模型;在投入运行阶段,向业务方解释模型的内部机制,对模型结果进行解释。
对抗性:
对抗攻击是指在原始样本中加入人眼无法察觉的噪声,该噪声不影响人对预测结果的判定,但是会让深度神经网络DNN受到愚弄,产生错误的预测结果。 加入噪音后的输入被称为对抗性样本。















 5430
5430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









