










Java 集合框架
Java Collection Framework ,又被称为容器
container ,是定义在
java.util 包下的一组接口
interfaces 和其实现类
classes 。其主要表现为将多个元素
element
置于一个单元中,用于对这些元素进行快速、便捷的存储
store 、检索
retrieve 、管理
manipulate ,即平时我们俗称的
增删查改
CRUD。
一、类和接口总览
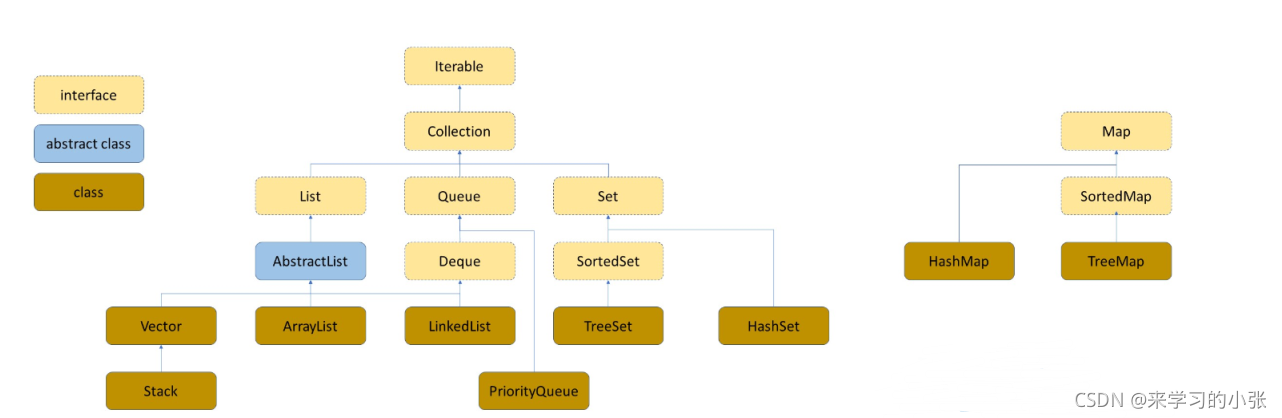
上图中最左边部分从上往下依次为:接口、抽象类、具体的实现类。
中间部分:
Iterable:迭代器。相当于for-each()。
Collection :用来存储管理一组对象 objects ,这些对象一般被成为元素elements。
Set: 元素不能重复,背后隐含着查找/搜索的语义。SortedSet: 一组有序的不能重复的元素。List: 线性结构。Queue: 队列。Deque: 双端队列。
右边部分:
Map: 键值对Key-Value-Pair,背后隐含着查找/搜索的语义。SortedMap: 一组有序的键值对。
二、Collection接口常用方法说明
2.1将元素放到集合中add
boolean add(E e) //将元素 e 放入集合中
示例:
public static void main(String[] args) {
//<>表示泛型
Collection<String> collection = new ArrayList<String>();
collection.add("hello");//将元素放入到集合中
// collection.add(1);
//<>里面的类型一定要是 类类型,不能是简单的基本类型
Collection<Integer> collection2 = new ArrayList<Integer>();
collection2.add(1);
collection2.add(2);
collection2.add(3);
}
2.2 删除集合中的所有元素clear()
void clear() //删除集合中的所有元素
2.3判断集合是否没有任何元素isEmpty()
boolean isEmpty() //判断集合是否没有任何元素,俗称空集合
2.4 删除集合中元素remove()
boolean remove(Object e) //如果元素 e 出现在集合中,删除其中一个
2.5 判断集合中元素个数size()
int size() //返回集合中的元素个数
2.6 返回一个装有所有集合中元素的数组
Object[] toArray() //返回一个装有所有集合中元素的数组
示例:
public static void main(String[] args) {
Collection<String> collection = new ArrayList<String>();
collection.add("hello");
collection.add("world");
System.out.println(collection);//[hello, world]
System.out.println(collection.size());//返回集合中的元素个数 2
/* collection.clear();//删除集合中的所有元素
System.out.println(collection);
System.out.println(collection.isEmpty());*/ //true
Object[] objects = collection.toArray();
System.out.println(Arrays.toString(objects));//[hello,world]
}
三、Map接口常用方法说明
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。Map中存储的就是key-value的键值对,Set中只存储了Key。
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。
3.1 根据指定的k查找对应的v(get)
方式一:
V get(Object k) //根据指定的 k 查找对应的 v
方式二:
V getOrDefault(Object k, V defaultValue) //根据指定的 k 查找对应的 v,没有找到用默认值代替
3.2 将指定的 k-v 放入Map(put)
V put(K key, V value) //将指定的 k-v 放入 Map
3.3 判断是否包含key(containskey)
boolean containskey(object key) //判断是否包含key
3.4 判断是否包含value(containsvalue)
boolean containsvalue(object value) //判断是否包含value
3.5 判断是否为空 isEmpty()
boolean isEmpty() //判断是否为空
3.6 返回键值对的数量size()
int size() //返回键值对的数量
3.7 删除 key 对应的映射关系(remove())
V remove(Object key)
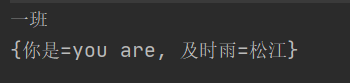
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("你是", "you are");
map.put("及时雨", "松江");
map.put("三年", "一班");
String ret = map.remove("三年");
System.out.println(ret);
System.out.println(map);
}
输出结果:
3.8 返回所有 key 的不重复集合
Set<K> keySet()
3.9 返回所有 value 的可重复集合
Collection<V> values()
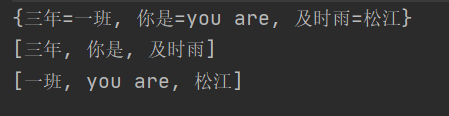
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
// Map<String,String> map2 = new TreeMap<>();
map.put("你是", "you are");//put在存储元素时要注意,key如果相同,那么value值会被覆盖
map.put("及时雨", "松江");
map.put("三年", "一班");
// String ret = map.remove("三年");
// System.out.println(ret);
System.out.println(map);
Set<String> set = map.keySet();
System.out.println(set);
Collection<String> sr = map.values();
System.out.println(sr);
}
输出结果:
示例:
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
// Map<String,String> map2 = new TreeMap<>();
map.put("你是","you are");
map.put("及时雨","松江");
String ret = map.get("你是");//根据key值获取val值
String ret2 = map.getOrDefault("你是","谁");//根据key值获取val值
//如果key值有的话,则返回对应key值的val,如果key值没有,则返回getOrDefault中得val 上面代码返回的值是you are
// String ret2 = map.getOrDefault("你是2","谁"); //谁
System.out.println(ret);//you are
System.out.println(ret2);//you are
boolean flg = map.containsKey("你是");
System.out.println(flg);//true
boolean flg2 = map.containsValue("宋江");
System.out.println(flg2);//false
boolean flg3 = map.isEmpty();
System.out.println(flg3);//false
System.out.println(map.size());//2
}
HashMap在存储元素的时候,不是按照存储的顺序进行打印的。存储的时候,是根据一个函数来进行存储的,具体存储到哪里是有这个函数来确定的,这个函数就是哈希函数。
3.10 将所有键值对映射关系返回entrySet()
Set<Map.Entry<K, V>> entrySet() //将所有键值对返回
示例:
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();//没有比较
//放入TreeMap当中的数据是可以进行比较的
//Map<Integer,String> map = new TreeMap<>();//进行比较了
map.put("你是","you are");
map.put("及时雨","宋江");
System.out.println(map);
System.out.println("=============");
Set<Map.Entry<String,String>> entrySet = map.entrySet();
for (Map.Entry<String,String> entry:entrySet) {
System.out.println("key:"+entry.getKey()+" value:"+entry.getValue());
}
}
注意:
Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap;Map中存放键值对的Key是唯一的,value是可以重复的;- 在
Map中插入键值对时,key不能为空,否则就会抛NullPointerException异常,但是value可以为空;(这个是指对于TreeMap的,在HashMap当中key和value都可以为null)。 Map中的Key可以全部分离出来用keySet,存储到Set中来进行访问(因为Key不能重复)。Map中的value可以全部分离出来,用values,存储在Collection的任何一个子集合中(value可能有重复)。Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。
TreeMap和HashMap的区别
| Map底层结构 | TreeMap | HashMap |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(log2(N)) | O(1) |
| 是否有序 | 关于Key有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
四、Set 常用方法说明
Set官方文档
Set与Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key。
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
set.add(1);
set.add(2);
set.add(3);
System.out.println(set);
Iterator<Integer> iterator = set.iterator();
while (iterator.hasNext()){
int ret = iterator.next();
System.out.print(ret +" ");
}
}

注意:
- Set是继承自Collection的一个接口类;
- Set中只存储了key,并且要求key一定要唯一;
- Set的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的;
- Set最大的功能就是对集合中的元素进行去重;
- 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。
- Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入;
- Set中不能插入null的key。
TreeSet和HashSet的区别 :

例1:
给定一万个数,统计每个数出现的次数。
public static Map<Integer,Integer> fun1(int[] arr){
Map<Integer,Integer> map = new HashMap<>();
for (int x: arr) {
if(!map.containsKey(x)){
map.put(x,1);
}else{
map.put(x,map.get(x) + 1);
}
}
return map;
}
public static void main(String[] args) {
int [] arr = new int[1_0000];
Random random = new Random();
for (int i = 0; i < arr.length; i++) {
arr[i] = random.nextInt(1000);
}
Map<Integer,Integer> map = fun1(arr);
System.out.println(map);
}
例2:将十万个数据中得数据去重。
直接把数据放到set当中
public static Set<Integer> fun2(int[] arr){
Set<Integer> set = new HashSet<>();
for (int x: arr) {
set.add(x);
}
return set;
}
例3.找到十万个数据中第一个重复的数据。
每次把元素放到set里面,放之前都检查一下,set中是不是已经有了。
public static int fun3(int[] arr){
Set<Integer> set = new HashSet<>();
for (int x: arr) {
if(set.contains(x)){
return x;
}
set.add(x);
}
return -1;
}

/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
//第一次遍历链表存储老节点和新节点的对应关系
//第2次遍历,修改新节点的next和random
//return map.get(head);
class Solution {
public Node copyRandomList(Node head) {
if(head == null){
return null;
}
Node cur = head;
Map<Node,Node> map = new HashMap<>();
while(cur != null){
Node node = new Node(cur.val);
map.put(cur,node);
cur = cur.next;
}
cur = head;
while(cur != null){
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
}
return map.get(head);
}
}

class Solution {
public int numJewelsInStones(String jewels, String stones) {
Set<Character> set = new HashSet<>();
char[] j = jewels.toCharArray();
for(int i = 0;i < j.length;i++){
set.add(j[i]);
}
char[] s = stones.toCharArray();
int count = 0;
for(int i = 0;i < s.length;i++){
if(set.contains(s[i])){
count++;
}
}
return count;
}
}
import java.util.*;
public class Main{
public static void func(String strExec,String strActu){
Set<Character> set1 = new HashSet<>();
Set<Character> broken = new HashSet<>();
char[] s1 = strExec.toCharArray();
char[] s2 = strActu.toCharArray();
for(char ch : strActu.toUpperCase().toCharArray()){
set1.add(ch);
}
for(char ch : strExec.toUpperCase().toCharArray()){
if(!set1.contains(ch) && !broken.contains(ch)){
System.out.print(ch);
broken.add(ch);
}
}
}
public static void main(String[] args){
Scanner scanner = new Scanner(System.in);
while(scanner.hasNextLine()){
String str1 = scanner.nextLine();
String str2 = scanner.nextLine();
func(str1,str2);
}
}
}
class Solution {
//统计每个单词出现的次数
//创建一个大小为k的小根堆
//遍历Map
public List<String> topKFrequent(String[] words, int k) {
//统计每个单词出现的次数
Map<String,Integer> map = new HashMap<>();
for(String s :words){
if(map.get(s) == null){
map.put(s,1);
}else{
map.put(s,map.get(s) + 1);
}
}
//创建一个大小为k的小根堆
PriorityQueue<Map.Entry<String,Integer>> minHeap = new PriorityQueue<>(k,new Comparator<Map.Entry<String,Integer>>() {
public int compare(Map.Entry<String,Integer> o1,Map.Entry<String,Integer> o2){
if(o1.getValue().compareTo(o2.getValue()) == 0){
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue() - o2.getValue();
}
});
//遍历Map
for(Map.Entry<String,Integer> entry : map.entrySet()){
if(minHeap.size() < k){
minHeap.offer(entry);
}else{
//说明堆中已经放满了k个元素,需要看堆顶元素和当前数据的大小关系
Map.Entry<String,Integer> top = minHeap.peek();
//判断频率是否相同,如果相同,比较单词大小,单词小的先入堆
if(top.getValue().compareTo(entry.getValue()) == 0){
if(top.getKey().compareTo(entry.getKey()) > 0){
minHeap.poll();
minHeap.offer(entry);
}
}else{
if(top.getValue().compareTo(entry.getValue()) < 0){
minHeap.poll();
minHeap.offer(entry);
}
}
}
}
List<String> ret = new ArrayList<>();
for(int i = 0;i < k;i++){
Map.Entry<String,Integer> top = minHeap.poll();
ret.add(top.getKey());
}
Collections.reverse(ret);
return ret;
}
}
以上。















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









