







在数据集合并的时候可以使用 IN 选项来标识新生成数据集每条观测来源,IN 选项可以与SET、UPDATE、MERGE语句共用,但最常与MERGE 语句合用,常用格式是IN=VARIABLE,如:
data both;
merge state(in=instate) country(in=incountry)
by statename;
run;
值得注意的是,此处的IN=variable里面的variable是临时的,且该variable的值只有0或1,如上程序所示,instate=1表示来自于该条观测存在于名为state的数据集,incountry=0表示该条观测不存在于名为country的数据集,该变量虽然是临时变量但也可以与if else语句连用来筛选合并数据集中需要输出的观测。
举例如下:

proc sort data=customer;
by customernumber;
proc sort data=orders;
by customernumber;
run;
data noorders;
merge customer orders(in=recent);
by customernumber;
if recent=0;
(这里不论是否能通过customernumber变量匹配与否,使用merge语句合并会将两个数据集观测都纳入合并数据集,
而使用recent=0则只会输出在orders数据集中不存在的观测)
run;
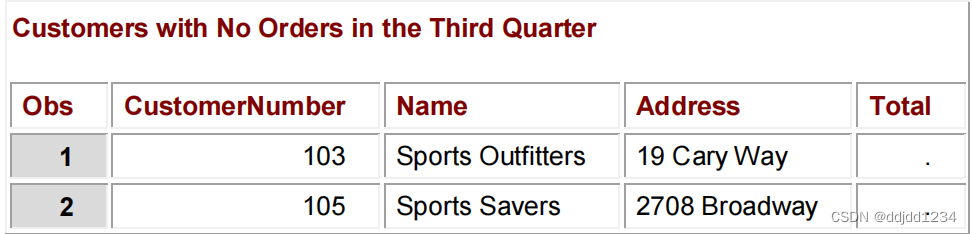
proc print data=noorders;
title "Customers with No Orders in the Third Quarter";
run;
结果如下:
在data 步还可以使用where =condition选项,其使用规范与where语句相同,示例如下:
data gone ;
set animals(where=(status="extinct"));
proc import datafile="c:\mayrawdata\wildlife.csv"
out=animals(where=(class="mammalia")) replace;
proc export data=animals(where=(status="Threatended"))
outfile="c:\myrawdata\wildlife.xls";
SAS数据集里面默认自带的变量:
_N_ 表示SAS在data step里面循环的次数,该次数不一定的观测数;
_ERROR_ 表示每行观测是否存在错误,存在错误为取值为1,不存在错误取值为0
FIRSR.VARIABLE 和LAST.VARIABLE 当存在by variable 语句时才可使用,在每个分组内当该变量的取值是第一次出现的观测标记1,其余标记0;或者末次出现标记1,其余标记0;
数据如下:

SAS程序如下:
data ordered ;
set walkers;
places=_N_;
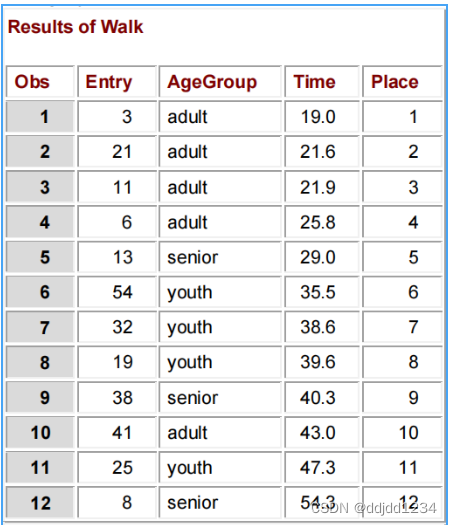
proc print data=ordered;
title “Results of Walk”;
run;
结果如下:
proc sort data=ordered;
by agegroup time;
data winners;
set ordered;
by agegroup time;
if first.agegroup=1;
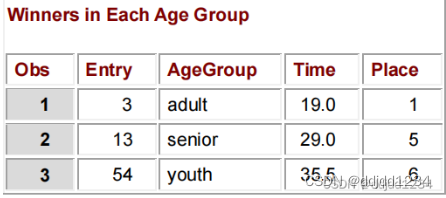
proc print data=winners;
title "Winners in Each Age Group";
run;
结果如下:















 3527
3527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









