







1. PROC UNIVARIATE
正态性检验可以使用proc univariate normal进行;normal表示正态性检验,在proc univariate 默认输出的skewness表示数据偏度,即不对称性,说明数据是否更偏向于一边;kurtosi表示数据的峰度,说明数据的分布是平坦的还是尖锐的;而正态性分布的偏度值(skewness)和峰度值(kurtosis)都是0。
使用proc univariate 的plot语句可以绘制图形,基本格式如下:
proc univariate;
var variable-list;
plot request variable-list/options;
run;
plot-request 包括:
cdfplot 累积分布函数图
histogram 直方图
ppplot probability-probability 图形(p-p图)
probplot 概率密度图
qqplot quantile-quantile图形(Q-Q图)
如果没有在plot request 里面设置 variable-list, 会对VAR 语句定义的变量绘制图形,如果没有定义var 语句,会对所有的数值变量定义图形;在options选项加入标准分布名称,将会在上述图形图形叠加标准分布曲线;PPPLOT、PROBPLOT、QQPLOT默认是使用正态分布绘制;也可以使用下列分布修改。
标准分布包括:BETA、EXPONENTIAL、GAMMA、LOGNORMAL、NORMAL、WEIBULL
如:probplot score/exponential
2.PROC MEANS
在proc means options 里面可以将options设置多个统计量名称,proc means支持的统计量如下:
CLM 双侧置信区间 CSS 校正平方和(corrected sum of squares) CV(变异系数)
KURTOSIS 偏度 LCLM 置信区间下限 MAX 最大值
MEAN 均值 MIN 最小值 MODE 众数
N 非缺失数 NMISS 缺失数 MEDIAN(P50) 中位数
Q1(P25) 25%分位数 Q3(P75)75%分位数 P1 1%分位数 P5 5%分位数 P10 10%分位数 P90 90%分位数 P95 95%分位数 P99 99%分位数 RANGE 范围
SKEWNESS 峰度 STDDEV 标准差 STDERR 标准误
SUM 求和 SUMWGT 加权求和 UCLM 置信区间上限
USS 不校正平方和 VAR 方差 PROBT T检验P值
T T值
计算置信区间CLM的时候可以考虑使用alpha=来定义置信区间宽度,不定义VAR 语句,PROC MEANS 对所有的数值变量计算统计量
3. PROC TTEST
使用proc ttest 进行单样本t检验的基本命令如下:
proc ttest H0=n options ;
var variable;
两独立样本t检验基本命令如下:
proc ttest options;
class variables;
var variable;
配对t检验的基本命令如下:
proc ttest options;
paried variable1*variable2;
常用的options选项如下:
alpha=n 设置检验水准,取值0-1,默认是0.05;
CI=type 设置标准差的置信区间计算方法,默认是EQUAL,上下限置信区间宽度是相等的,另一个取值是UMPU和NONE,NONE表示不输出标准差的置信区间
H0=n 单样本检验的原假设值,默认是0;
NOBYVAR 将变量的名称从标题放置表格中
SIDES=TYPE 设置检验方向,取值2表示双侧检验,取值L表示低测的单侧检验,设置U表示高侧的单侧检验
proc ttest会默认使用ODS GRAPH创建图形包括直方图、箱式图和Q-Q图,可以使用如下命令控制输出图形:
proc ttest plots=(plot-requestion-list)
常用的proc -requestion-list如下:
ALL 所有图形
BOXPLOT 创建箱式图
HISTOGRAM 创建直方图
INTERVALPLOT 创建均值置信区间图
NONE 不创建任何图形
QQPLOT 创建正态性的QQ图
SUMMARYPLOT 同时创建直方图和箱式图
配对t检验还可以创建如下两类图形:
AGREEMENTPLOT 创建一致性图形
PROFILESPLOT 创建成对详细信息图,示例如下:
当使用proc ttest时 QQPLOT 和SUMMRYPLOT会默认自动创建,在配对t检验时还会默认自动AGREEMENTPLOT和PROFILESPLOT,可以使用plots(only)=(plot-requestion-list)来告诉SAS只输出请求创建的图形
举例如下:
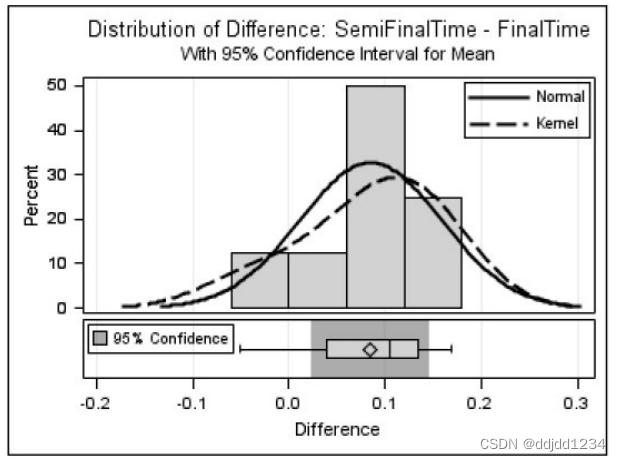
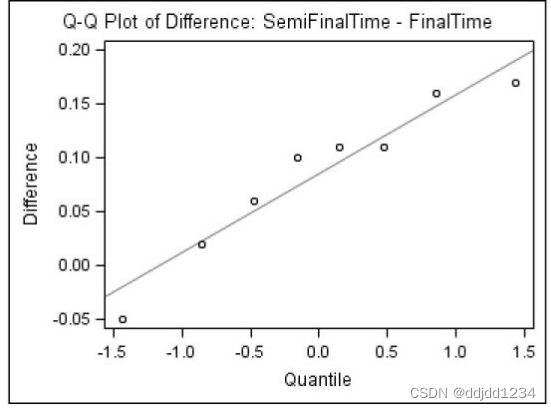
proc ttest data=swim plots(only)=(SUMMARY QQPLOT);
title "50m Freestyle Semifinal vs. Final Results";
paired SemiFinalTime*FinalTime;
run;
生成图形如下:
4.proc freq
proc freq用于对分类数据进行统计,一个是统计分类数据间是否存在关联,一个是统计关联的强度,基本格式如下:
proc freq ;
table variable-combination/options;
常见的选项options如下:
agree 输出一致性程度及对该程度检验,检验包括McNemar's test \Bowker's test\Cochran's Q test\Kappa test
chisq 输出卡方值以及关联强度
CL 输出关联强度的置信区间
CMH 输出针对分层表格的Cochran-Mantel-Haenszel的统计量(CMH 统计量)
EXACT 针对2*2y以上的表格输出fisher精确统计量
MEASURES 输出表示关联强度的指标,如person and spearman 相关系数,gamma,kendall's tau-b,Stuart's tau-c,Somer's D,lambda, odds ration(OR),risk ration,及其置信区间
RELRISK 输出2*2相对风险比(RR)
TREND 输出趋势性检验Cochran-Armitage
proc freq 还会使用ods graph 输出图形如频数图、OR图、RR图及一致性图等,proc freq 输出图形的基本命令如下:值得注意的是某些plot-list必须与某些options连用
proc freq;
tables variable-combinations/options plots=(plot-list)
以下是常见的plot-list 以及可以连用的options
agreeplot 适用于二联表, 与agree 联用
cumfreqplot 适用于单向表
deviationplot 适用于单向表,与chisq联用
freqplot 适用于各种形式
kappaplot 适用于三向表,与agree联用
oddsratioplot h*2*2,与 measures或relrisk联用
relriskplot h*2*2,与measures或relrisk联用
riskdiffplot h*2*2,与riskdiff联用
wtkappaplot h*r*r(r>2),与agree联用
SAS 还提供了一些选项控制图形的样式,比如:
tables variable1*variable2/plots=freqplot(two-way=grouphorizontal),输出的频数表成横向排列
5.proc corr
proc corr 可以计算两个变量的相关性,基本命令如下:
proc corr options;
var variable-list;(表示两两相关的列变量)
with variable-list;(表示两两相关的行变量)
如果只有var变量没有with 变量,则所有的var变量即是列变量也是行变量
常见选项pearson,spearman,hoeffding(hoeffding’s D),kendall(,kendall's tau-b)
可以使用proc corr生成图形,但需要用户自己向SAS请求,基本命令如下:
proc corr plots=(plot-list);
var variable-list;
with variable-list;
run;
可以使用plot-list如下:
scatter 为一对变量绘制带有预测椭圆,默认是出预测椭圆,如果不需要产生预测椭圆可以使用scatter(ellipse=none),如果需要为预测椭圆加上置信区间可以使用scatter(ellipse=confidence);
matrix 为所有变量绘制散点图矩阵,如果没有with 语句,matrix会为所有的var 语句内的变量生成对称矩阵散点图(variable即为横轴也为纵轴),该散点图的对角为空;加上histogram则会在为空的对角上加上直方图,如matrix(histogram)
举例如下:
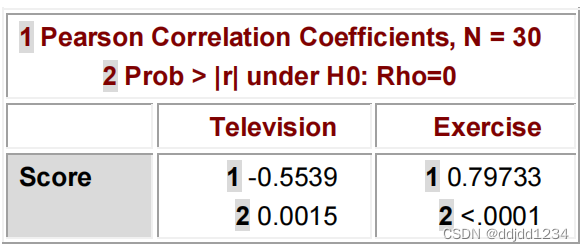
proc corr data=class plots=(scatter matrix);
var television exercise;
with score;
title "Correlations for Test Scores";
title2 "With Hours of Televsion and Exercise";
run;
结果如下:
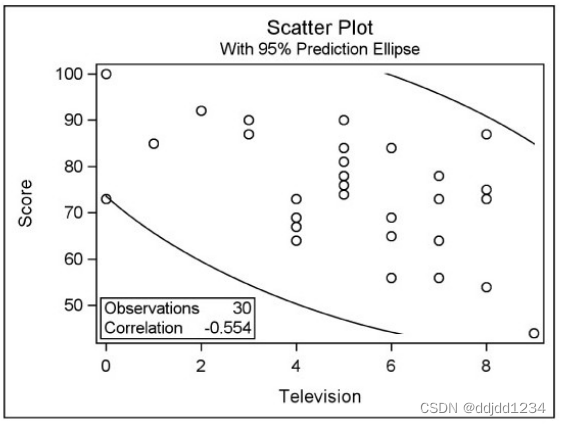
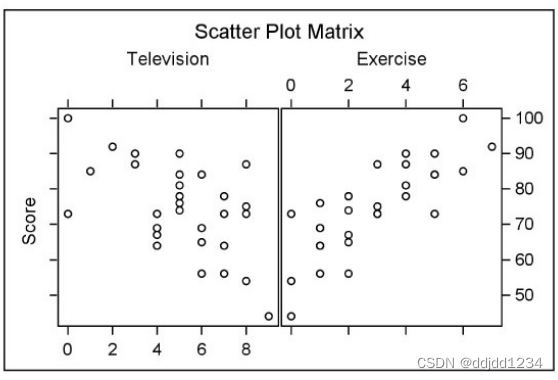
6.proc reg
使用proc reg 时会自动调用ODS GRAPH 来创建图形,基本格式如下:
proc reg plot(options)=(plot-requestion-list)
model dependent=independent
run;
常用的plot-request如下:
fitplot 散点图,带有拟合线、置信线和预测条带,(只有1个变量时默认输出)
residuals 残差vs自变量图(默认输出)
diagnostics 诊断图(包括下面所有图,也是默认输出)
cooksd 观测点的COOK'D值图
observedbypredicted 因变量vs预测值
QQPLOT 残差的正态性QQ图
residualbypredicted 残差vs预测值
rfplot 残差拟合线图
rstudentbyleverage 学生化残差vs杠杆值
rstudentbypredicted 学生化残差vs预测值
如果只需要输出某些自定义的图,可以使用plots(only)=(plot-requesi-list)
举例如下:
proc reg data=hist plots(only)=(diagnotics fitplot)
model Distance=height;
title "Results of Regression Analysis";
run;
图形如下:
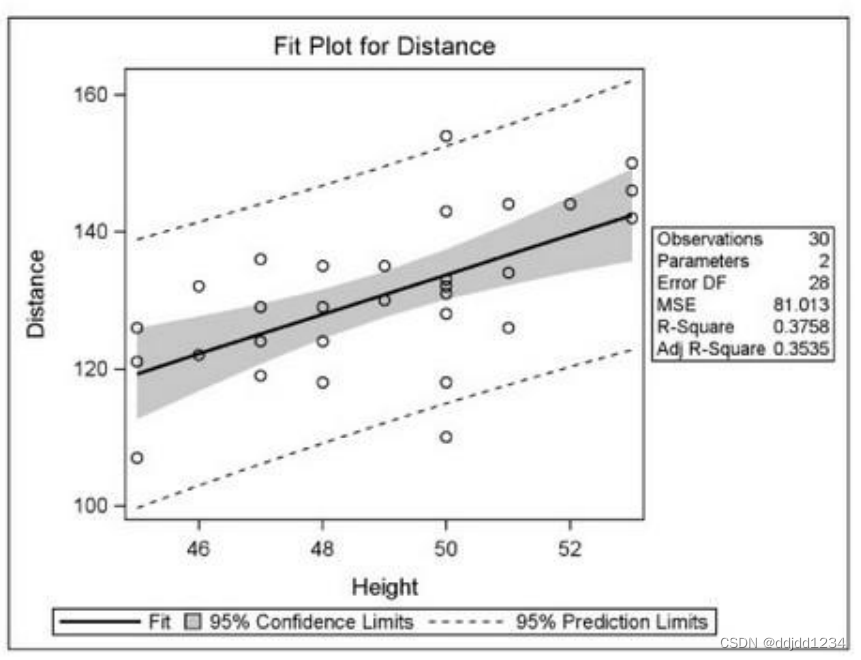
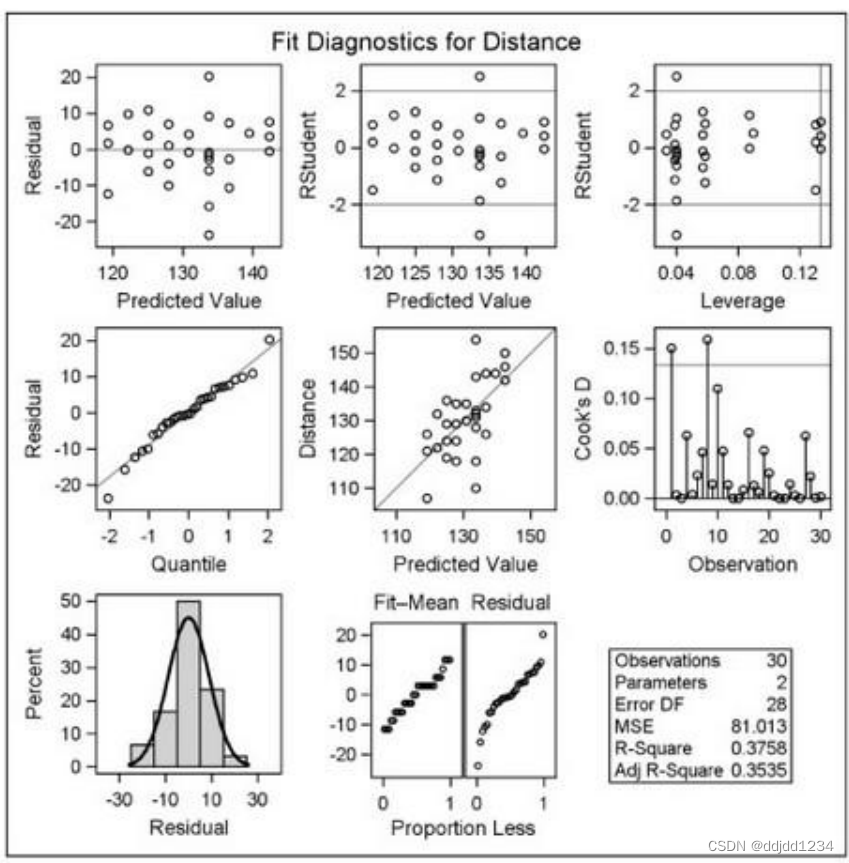
7.proc anova
proc anova 是用于进行方差分析,适用于平衡数据或者说单因素方差分析;当单因素方差分析且数据不平衡时则不适用于使用proc anova 进行分析,考虑使用proc glm进行分析。本节仅说明使用proc anova 进行单因素方差分析情形,基本格式如下:
proc anova;
class variable-list;
model dependent=effects;
means effects/options;
class表示分类变量,在单因素方差分析中class 中只包含1个分类变量,
model 表示进行方差分析,effect来源于class设置的分类变量,dependent则为因变量;
means表示计算因变量在各个主效应(main effects)的均值,effects来源于model 中的任意表示effect的变量;options表示可进行组间多重比较,多重比较的检验如下:
名称 检验
BON bonferroni t检验
DUNCAN duncan 多重检验
SCHEFFE scheffe多重检验
T 成对t检验
TUKEY TUKEY多重检验
举例如下:
proc anova data=heights;
class region;
model height=region;
means region/scheffe;
title "Girl's Heights from Four Regions";
run;
scheffe检验结果如下:
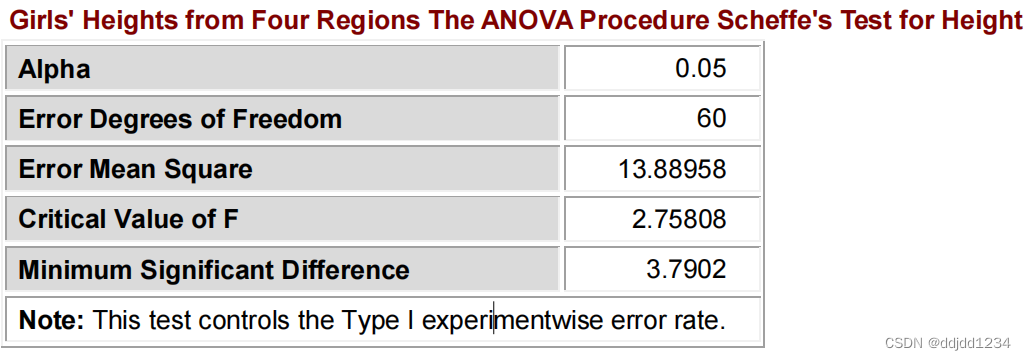
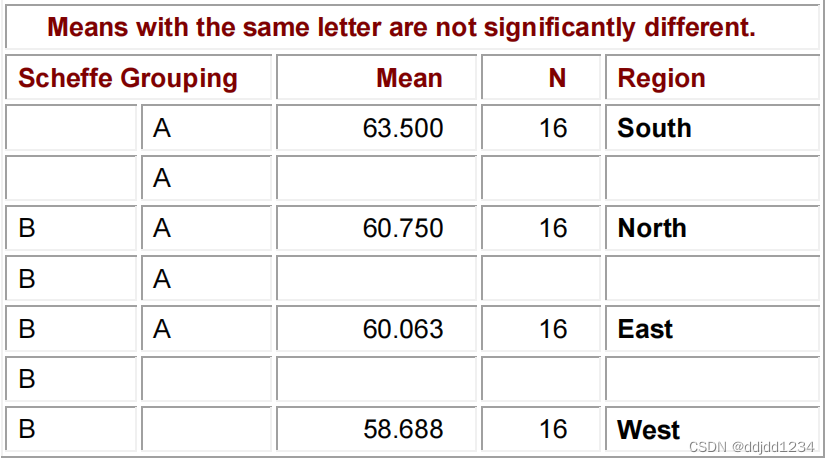
上表的字母用于表示组别,有相同的字母的两组表示没有显著性差异。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









