







前言
大家都爱用Python,很大程度是因为Python有非常丰富好用的扩展包,比如Numpy、Matplotlib、Pandas等。特别是Numpy,为科学计算提供了基础支撑,使得Python具有类似Matlab一样的科学计算能力。如果用C/C++语言进行算法开发,实际上我们需要的就是一个类似Numpy的线性代数库,最基本的是支持BLAS三级运算(矢量基本计算、矩阵与矢量的基本计算、矩阵的基本计算),在在此基础上封装一些成熟常见的线性代数算法,如解方程、矩阵分解等。
ViennaCL与Eigen都是C++线性代数库。前者基于OpenCL、CUDA等后端,可实现GPU加速的线性代数运算;后者是以头文件发布的运行于CPU上的轻量级线性代数库。ViennaCL支持从Eigen拷贝数据,结合这两者的优势,可达到双剑合璧的效果。
1. ViennaCL简介
前面几次专题介绍了OpenCL并行程序开发的基础,利用GPU等多核设备对规模较大的数据块进行并行计算,从而提升计算效率。而ViennaCL则是在OpenCL、CUDA、OpenMP之上,封装了矢量、矩阵的相关计算,并实现了一些常用的线性代数算法,可以把ViennaCL看作OpenCL上的Numpy。简单讲,ViennaCL有以下两点核心价值:
- 屏蔽了OpenCL异构编程的底层细节
- 提供了标量、矢量、矩阵的数据结构,并对它们之间的基本运算符进行了重载,支持BLAS三级运算
- 封装了一些线性代数算法,如多种线性方程求解算法、特征值算法、QR分解算法、快速傅立叶变换算法、奇异值分解算法、非负矩阵分解算法等
2. ViennaCL安装
ViennaCL的官网地址http://viennacl.sourceforge.net。
下载后,可以通过cmake编译运行其中附带的测试和示例。但对于项目开发,只需要将其中的头文件库viennacl/复制到项目文件夹或全局系统包含路径就足够了。在基于Unix的系统上,这通常是/usr/include/或/usr/local/include/。如果您的系统上没有安装OpenCL头文件,您还需要将cl/文件夹复制到项目文件夹或者全局系统包含路径下,cl/文件夹也在下载的包中一并提供了。
Windows 上的情况很大程度上取决于您的开发环境。在Visual Studio中,这通常类似于C: /Program Files/Microsoft Visual Studio 9.0/VC/include,并可以在 Tools-> Options-> Projects and Solutions-> VC + ±Directory中设置。为了使用 CUDA 后端,请确保CUDA SDK安装正确,并支持您的主机编译器套件。如果您打算使用OpenCL后端,那么OpenCL SDK的包含和库目录也应该添加到那里。
ViennaCL为用户快速入门提供了几个示例,这些示例可以手动构建和运行,也可以使用提供的CMake构建设置。比如直接用编译器手工构建:
$> g++ /path/to/ViennaCL/examples/tutorial/amg.hpp -I/path/to/ViennaCL
其中“/path/to/ViennaCL/”需要替换为适当的绝对或相对路径。编译后将产生一个二进制可执行文件 a.out,其中将使用ViennaCL的CPU后端。若要启用OpenCL或CUDA,请传递其他标志-DVIENNACL_WITH_OPENCL或-DVIENNACL_WITH_CUDA。在前一种情况下,还需要传递OpenCL的头文件目录和动态链接库目录:-lOpenCL和-L/path/to/libOpenCL.so。在后一种情况下,您需要使用NVIDIA编译器包装器nvcc而不是GCC或 Clang,以便正确编译所有CUDA内核。
关于编译时传递标志-DVIENNACL_WITH_OPENCL,我们也可以通过在程序中定义常量#define VIENNACL_WITH_OPENCL来实现,该常量定义需要在引入任何ViennaCL头文件之前。
3. ViennaCL基本数据结构
3.1 标量scalar<T>
带有模板参数T的标量类型scalar<T>表示底层CPU或GPU上的标量类型(char、short、int、long、float 和double) ,注意,有些设备上不支持double类型。用户必须记住,在 scalar<T>上的每个操作都可能需要在GPU上启动一个OpenCL计算内核,因此这个操作比传统的CPU等效操作要慢得多。即使使用了ViennaCL的基于CPU的计算后端,也会出现一些小的开销。
因此,标量一般不会在GPU上进行计算,GPU等多核设备适用于大规模的数据块计算,数据块越大,并行所带来的性能提升才足以抵消总线数据传输和计算内核编译所带来的性能下降。但GPU上的标量可以作为矢量、矩阵运算的结果。
#define VIENNACL_WITH_OPENCL
#include <viennacl/scalar.hpp> //GPU标量
#include <viennacl/tools/timer.hpp> //跨平台计时器
#include <iostream>
using namespace std;
typedef float ScalarType;
#define LOOP 1000
void testScalar()
{
ScalarType s1,s2,s3;
viennacl::scalar<ScalarType> vcl_s1, vcl_s2, vcl_s3;
viennacl::tools::timer timer;
s1=3.1415926;
s2=2.71763;
s3=42.0;
vcl_s2=1.0;
vcl_s3=1.0;
//CPU Scalar和GPU Scalar可以相互赋值
vcl_s1=s1;
s2=vcl_s2;
vcl_s3=s3;
//GPU中变量的运算比CPU变量运算慢
timer.start();
for(int i=0;i<LOOP;i++) s1=s3+s2;
cout<<"CPU标量加"<<LOOP<<"次耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LOOP;i++) vcl_s1=vcl_s3+vcl_s2;
cout<<"GPU标量加"<<LOOP<<"次耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LOOP;i++) s1=s3-s2;
cout<<"CPU标量减"<<LOOP<<"次耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LOOP;i++) vcl_s1=vcl_s3-vcl_s2;
cout<<"GPU标量减"<<LOOP<<"次耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LOOP;i++) s1=s3*s2;
cout<<"CPU标量乘"<<LOOP<<"次耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LOOP;i++) vcl_s1=vcl_s3*vcl_s2;
cout<<"GPU标量乘"<<LOOP<<"次耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LOOP;i++) s1=s3/s2;
cout<<"CPU标量除"<<LOOP<<"次耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LOOP;i++) vcl_s1=vcl_s3/vcl_s2;
cout<<"GPU标量除"<<LOOP<<"次耗时:"<<timer.get()<<endl;
}
在某平台上,测试得到的结果如下:
CPU标量加1000次耗时:0.000106
GPU标量加1000次耗时:1.97466
CPU标量减1000次耗时:1e-05
GPU标量减1000次耗时:0.838568
CPU标量乘1000次耗时:1.1e-05
GPU标量乘1000次耗时:0.759756
CPU标量除1000次耗时:1.2e-05
GPU标量除1000次耗时:0.760834
从测试结果可看出,对单个浮点数计算单元的计算效率,CPU比GPU快大约4个数量级。
3.2 矢量vector<T>
ViennaCL中的向量类型是vector ,表示计算设备上的一块内存。T是底层的标量类型(char、short、int、long、float或double(如果支持) )。ViennaCL不支持复杂类型。在构造时vector时,通过clear()成员函数可将内存初始化为零(类似于std::vector<T>)。与CPU实现不同的是,访问单个向量元素的成本非常高,因为每次访问一个元素时,都会发生CPU与GPU之间的数据传输,所以尽量避免这种操作。通过重载的copy()函数对大规模的矢量进行CPU和GPU之间的传输,效率很高。copy()函数是通用的,并不假定CPU对象位于连续内存序列(堆空间),如果能确定CPU对象位于连续内存序列中,则可以使用fast_copy()函数进行CPU与GPU之间的数据传输。
vector<T>的成员函数如下表:
| 成员函数 | 简介 |
|---|---|
| CTOR(n) | 具有条目数的构造函数 |
| v(i) | 访问v的第i个元素(GPU 慢!) |
| v[i] | 访问v的第i个元素(GPU 慢!) |
| v.clear() | 用0初始化v |
| v.resize(n, bool preserve) | 将v调整为长度n。如果bool为true,则保留旧值。 |
| v.begin() | 矢量开始的迭代器 |
| v.end() | 矢量末尾的迭代器 |
| v.size() | 矢量的长度 |
| v.swap(v2) | 用v2交换v的内容 |
| v.internal_size() | 返回GPU上分配的条目数(考虑到对齐) |
| v.empty() | v.size ()==0的简写符号 |
| v.handle() | 返回内存句柄(自定义内核所需) |
除了这些成员函数,还有BLAS的操作符重载,适用于矢量和矩阵,包括内积、范数、转置、element-wise四则运算、element-wise三角函数运算、对数运算、开方运算、四舍五入运算、指数运算等。关于BLAS运算,将在后面专题单独介绍。下面的示例中用到了内积、范数、element-wisesize运算来测试性能。
#define VIENNACL_WITH_OPENCL
#include <viennacl/scalar.hpp> //GPU标量
#include <viennacl/vector.hpp> //GPU矢量
#include <vector> //CPU向量
#include <viennacl/tools/timer.hpp> //跨平台计时器
#include <viennacl/tools/random.hpp> //跨平台随机数生成器
#include <viennacl/linalg/inner_prod.hpp> //计算向量内积
#include <viennacl/linalg/norm_1.hpp> //计算向量1范数
#include <viennacl/linalg/norm_2.hpp> //计算向量2范数
#include <viennacl/linalg/norm_inf.hpp> //计算向量无穷范数
#include <viennacl/linalg/vector_operations.hpp> //向量的BLAS运算
#include <iostream>
using namespace std;
typedef float ScalarType;
#define LENGTH 1000000
#define LOOP 10
void testVector()
{
ScalarType s1,s2,s3;
viennacl::scalar<ScalarType> vcl_s1, vcl_s2, vcl_s3;
vector<ScalarType> vec1(LENGTH),vec2(LENGTH),vec3(LENGTH);
viennacl::vector<ScalarType> vcl_vec1(LENGTH),vcl_vec2(LENGTH),vcl_vec3(LENGTH);
viennacl::tools::uniform_random_numbers<ScalarType> random;
viennacl::tools::timer timer;
timer.start();
for(int i=0;i<LENGTH;i++) vec1[i]=random();
cout<<"初始化长度为"<<LENGTH<<"的CPU向量耗时:"<<timer.get()<<endl;
// timer.start();
// for(int i=0;i<LENGTH;i++) vcl_vec2[i]=random(); //GPU Vector也可以这样操作,但速度很慢
// cout<<"初始化GPU向量耗时:"<<timer.get()<<endl;
for(int i=0;i<LENGTH;i++) vec2[i]=random();
for(int i=0;i<LENGTH;i++) vec3[i]=random();
//CPU向量与GPU向量互拷贝
timer.start();
viennacl::copy(vec1.begin(),vec1.end(),vcl_vec1.begin());
cout<<"使用copy从CPU向GPU拷贝数据耗时:"<<timer.get()<<endl;
//timer.start();
viennacl::copy(vec2,vcl_vec2); //缩写形式
viennacl::copy(vec3,vcl_vec3);
//使用循环进行CPU与GPU之间的拷贝,非常耗时
// //cout<<"使用copy从GPU向CPU拷贝数据耗时:"<<timer.get()<<endl;
// timer.start();
// for(int i=0;i<LENGTH;i++) vcl_vec3[i]=vec3[i];
// cout<<"使用循环从CPU向GPU拷贝数据耗时:"<<timer.get()<<endl;
// timer.start();
// for(int i=0;i<LENGTH;i++) vec3[i]=vcl_vec3[i];
// cout<<"使用循环从GPU向CPU拷贝数据耗时:"<<timer.get()<<endl;
//计算内积
timer.start();
for(int loop=0;loop<LOOP;loop++) s1=viennacl::linalg::inner_prod(vec1,vec2);
cout<<"CPU计算内积耗时:"<<timer.get()<<endl;
timer.start();
for(int loop=0;loop<LOOP;loop++) vcl_s1=viennacl::linalg::inner_prod(vcl_vec1,vcl_vec2);
cout<<"GPU计算内积耗时:"<<timer.get()<<endl;
//计算范数
timer.start();
for(int loop=0;loop<LOOP;loop++) s1=viennacl::linalg::norm_1(vec1);
cout<<"CPU计算1范数耗时:"<<timer.get()<<endl;
timer.start();
for(int loop=0;loop<LOOP;loop++) vcl_s1=viennacl::linalg::norm_1(vcl_vec1);
cout<<"GPU计算1范数耗时:"<<timer.get()<<endl;
timer.start();
for(int loop=0;loop<LOOP;loop++) s2=viennacl::linalg::norm_2(vec2);
cout<<"CPU计算2范数耗时:"<<timer.get()<<endl;
timer.start();
for(int loop=0;loop<LOOP;loop++) vcl_s2=viennacl::linalg::norm_2(vcl_vec2);
cout<<"GPU计算2范数耗时:"<<timer.get()<<endl;
timer.start();
for(int loop=0;loop<LOOP;loop++) s3=viennacl::linalg::norm_inf(vec3);
cout<<"CPU计算无穷范数耗时:"<<timer.get()<<endl;
timer.start();
for(int loop=0;loop<LOOP;loop++) vcl_s3=viennacl::linalg::norm_inf(vcl_vec3);
cout<<"GPU计算无穷范数耗时:"<<timer.get()<<endl;
//标量、矢量的加减乘除
//仅支持标量与矢量的乘除、矢量与矢量的加减
//CPU上vector未重载*/运算
// timer.start();
// vec1=s1*vec2/s3;
// cout<<"CPU标量与矢量乘除耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LENGTH;i++) vec1[i]=s1*vec2[i];
cout<<"CPU矢量与标量乘耗时:"<<timer.get()<<endl;
timer.start();
vcl_vec1=vcl_s1*vcl_vec2;
cout<<"GPU矢量与标量乘耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LENGTH;i++) vec1[i]=vec2[i]/s3;
cout<<"CPU矢量与标量除耗时:"<<timer.get()<<endl;
timer.start();
vcl_vec1=vcl_vec2/vcl_s3;
cout<<"GPU矢量与标量除耗时:"<<timer.get()<<endl;
//CPU上vector未重载+-运算
// timer.start();
// vec1=vec2+vec3;
// cout<<"CPU矢量与矢量加减耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LENGTH;i++) vec1[i]=vec2[i]+vec3[i];
cout<<"CPU矢量与矢量加减耗时:"<<timer.get()<<endl;
timer.start();
vcl_vec1=vcl_vec2+vcl_vec3;
cout<<"GPU矢量与矢量加减耗时:"<<timer.get()<<endl;
//CPU上矢量与矢量的element-wise乘除没有重载
timer.start();
for(int i=0;i<LENGTH;i++) vec1[i]=vec2[i]*vec3[i];
cout<<"CPU矢量与矢量的element-wise乘耗时:"<<timer.get()<<endl;
timer.start();
vcl_vec1=viennacl::linalg::element_prod(vcl_vec2,vcl_vec3);
cout<<"GPU矢量与矢量的element-wise乘耗时:"<<timer.get()<<endl;
timer.start();
for(int i=0;i<LENGTH;i++) vec1[i]=vec2[i]/vec3[i];
cout<<"CPU矢量与矢量的element-wise除耗时:"<<timer.get()<<endl;
timer.start();
vcl_vec1=viennacl::linalg::element_div(vcl_vec2,vcl_vec3);
cout<<"GPU矢量与矢量的element-wise除耗时:"<<timer.get()<<endl;
}
在某平台上,测试得到的结果如下:
初始化长度为1000000的CPU向量耗时:0.150979
使用copy从CPU向GPU拷贝数据耗时:0.216836
CPU计算内积耗时:0.016806
GPU计算内积耗时:0.024737
CPU计算1范数耗时:0.150095
GPU计算1范数耗时:0.020284
CPU计算2范数耗时:0.146383
GPU计算2范数耗时:0.019676
CPU计算无穷范数耗时:0.15609
GPU计算无穷范数耗时:0.023376
CPU矢量与标量乘耗时:0.026665
GPU矢量与标量乘耗时:0.001067
CPU矢量与标量除耗时:0.030738
GPU矢量与标量除耗时:0.001046
CPU矢量与矢量加减耗时:0.038059
GPU矢量与矢量加减耗时:0.001114
CPU矢量与矢量的element-wise乘耗时:0.044527
GPU矢量与矢量的element-wise乘耗时:1.54116
CPU矢量与矢量的element-wise除耗时:0.037726
GPU矢量与矢量的element-wise除耗时:0.001409
从测试结果可看出,当数据量达到1百万规模单精度浮点数时(约4MB),GPU比CPU有了一个数量级的优势。随着数据规模的增大,优势将更加明显。当然并行加速的性能提升也取决于算法类型和硬件对特定指令的加速情况,如测试所用的硬件平台,GPU没有对乘法指令做优化,导致GPU内积耗时比CPU更大,element-wise乘耗时也同样落后于CPU。
3.3 稠密矩阵matrix<T>
matrix<T,F>表示一个稠密矩阵。第二个可选模板参数F指定存储布局,默认值为row_main,即以行为基本单元进行数据存储。也可以使用column_main内存布局。下图则是以行为存储单元的矩阵布局。
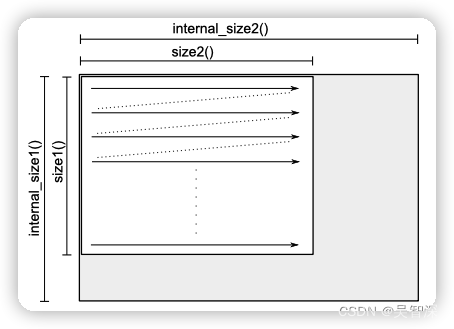
可以使用操作符()访问矩阵某个位置的元素,但这种操作在GPU后端非常慢,尽量避免使用。
更好的方法是使用copy()函数来初始化矩阵。在CPU上声明和初始化一个矩阵,在GPU上声明同样大小的矩阵,并利用copy()函数进行拷贝。CPU上的矩阵可以通过Eigen类库来实现。关于Eigen的介绍,请见下一节。这里先给出利用Eigen和viennacl::matrix<T>进行测试的代码。
#define VIENNACL_WITH_OPENCL
#define VIENNACL_WITH_EIGEN //若混合使用了Eigen,则必须声明该标志,编译器对viennacl的编译将会增加对Eigen的适配
#include <viennacl/scalar.hpp> //GPU标量
#include <viennacl/vector.hpp> //GPU矢量
#include <viennacl/matrix.hpp> //GPU矩阵
#include <viennacl/tools/timer.hpp> //跨平台计时器
#include <viennacl/tools/random.hpp> //跨平台随机数生成器
#include <iostream>
#include <Eigen/Dense> //Eigen稠密矩阵
using namespace std;
typedef float ScalarType;
#define ROWS 500
#define COLS 1000
void testMatrix()
{
viennacl::tools::uniform_random_numbers<ScalarType> random;
viennacl::tools::timer timer;
timer.start();
viennacl::vector<ScalarType> vcl_vec1(COLS), vcl_vec2(ROWS);
viennacl::matrix<ScalarType> vcl_matrix1(ROWS,COLS),vcl_matrix2(COLS,ROWS);
Eigen::VectorXf vec1(ROWS),vec2(ROWS);
Eigen::MatrixXf matrix1(COLS,ROWS), matrix2(COLS,ROWS);
cout<<"初始化耗时:"<<timer.get()<<endl;
timer.start();
vec1=Eigen::VectorXf::Random(COLS);
cout<<"CPU初始化长度"<<COLS<<"Eigen矢量耗时:"<<timer.get()<<endl;
timer.start();
matrix1=Eigen::MatrixXf::Random(ROWS,COLS);
cout<<"CPU初始化"<<ROWS<<"行"<<COLS<<"列"<<"Eigen矩阵耗时:"<<timer.get()<<endl;
timer.start();
viennacl::copy(vec1,vcl_vec1);
cout<<"CPU向GPU拷贝矢量耗时:"<<timer.get()<<endl;
timer.start();
viennacl::copy(matrix1,vcl_matrix1);
cout<<"CPU向GPU拷贝矩阵耗时:"<<timer.get()<<endl;
cout<<"矩阵尺寸:("<<vcl_matrix1.size1()<<","<<vcl_matrix1.size2()<<")"<<endl;
cout<<"矢量尺寸:"<<vcl_vec1.size()<<endl;
timer.start();
vec2=matrix1*vec1;
cout<<"CPU使用Eigen计算矩阵乘矢量耗时:"<<timer.get()<<endl;
timer.start();
//注意确保size(vcl_vec2)==size1(vcl_matrix1),size2(vcl_matrix1==size(vcl_vec1))
vcl_vec2=viennacl::linalg::prod(vcl_matrix1,vcl_vec1);
cout<<"GPU计算矩阵乘矢量耗时:"<<timer.get()<<endl;
timer.start();
matrix2=matrix1.transpose();
cout<<"CPU使用Eigen计算矩阵转置耗时:"<<timer.get()<<endl;
timer.start();
vcl_matrix2=viennacl::trans(vcl_matrix1);
cout<<"GPU计算矩阵转置耗时:"<<timer.get()<<endl;
}
在某平台上,测试得到的结果如下:
CPU初始化长度1000Eigen矢量耗时:0.000221
CPU初始化500行1000列Eigen矩阵耗时:0.080586
CPU向GPU拷贝矢量耗时:0.000971
CPU向GPU拷贝矩阵耗时:0.040543
矩阵尺寸:(500,1000)
矢量尺寸:1000
CPU使用Eigen计算矩阵乘矢量耗时:0.012117
GPU计算矩阵乘矢量耗时:0.000985
CPU使用Eigen计算矩阵转置耗时:0.036504
GPU计算矩阵转置耗时:1.62203
从测试结果可以看出,GPU计算矩阵与矢量乘法的运算比CPU上Eigen的计算效率高两个数量级,且随着矩阵规模增大,效率提升会更明显。但由于GPU上存储容量的限制,当超过一定规模后会发生溢出。具体可通过clinfo查看具体平台上的存储限制。
从测试结果也可以看出,对于矩阵转置运算,GPU的效率比CPU慢了两个数量级,这时因为转置操作并不能很好适配GPU多核心并行计算的架构。因此,在进行算法的并行化改进时,需要首先评估算法与GPU计算架构的适配性,将其中适配度高的步骤改成GPU计算。
4. Eigen简介
Eigen是一个运行于CPU上的线性代数C++模板库,包含了矩阵、向量、数值求解器和相关算法。该库以头文件形式发布,直接将含有这些头文件的目录拷贝到项目目录下即可调用,相比Boost的uBLAS这类重量级的库轻便不少,更适用于嵌入式开发。ViennaCL支持从Eigen拷贝数据(需要添加预编译头#define VIENNACL_WITH_EIGEN)。轻量化、支持ViennaCL,这两点使得其成为嵌入式系统上进行并行算法开发的最佳选择。
这里并不打算对其展开介绍,只简要介绍Eigen的矢量和矩阵对象,并介绍Eigen进行SVD分解的方法。关于其所支持的其它丰富线性代数算法,将不再深入,感兴趣的读者可参考Eigen官网文档。
在3.3节给出的ViennaCL矩阵测试代码中,就用到了Eigen。我们通过#include <Eigen/Dense>将Eigen的稠密矩阵类引入。
- Eigen::VectorXf vector(10)是声明一个长度为10的矢量。VectorXf中的X表示维度不定,在程序运行时动态分配,f表示是浮点数类型。我们也可利用Eigen::VectorXf::Random(10)函数来初始化一个随机矢量,One()、Zero()则是初始化为1或0。
- Eigen::MatrixXf matrix(10,20)是声明一个尺寸为10*20的矩阵。X和f的含义于矢量中一样。如果把X换成2,则是指明二维矩阵,f换成d则是表示整数类型。同样,也可以利用Eigen::MatrixXf::Random(10,20)函数来初始化一个随机矩阵。
- ViennaCL可以通过添加#define VIENNACL_WITH_EIGEN预编译头来适配Eigen。通过viennacl.copy()函数,可以从CPU上拷贝矢量或矩阵到GPU上的viennacl矢量或矩阵,反之亦然。
下面给出测试Eigen的代码:
#include <iostream>
#include "Eigen/Dense"
using namespace std;
//ROWS矩阵高,COLS矩阵宽,MIDDLE是SVD分解时奇异值的个数
#define ROWS 50
#define COLS 600
#if(ROWS<COLS)
#define MIDDLE ROWS
#else
#define MIDDLE COLS
#endif
int main()
{
Eigen::MatrixXf matrix=Eigen::MatrixXf::Random(5,10);
cout<<matrix<<endl;
cout<<matrix.rows()<<endl;
cout<<matrix.cols()<<endl;
cout<<matrix.size()<<endl;
cout<<matrix(0,0)<<endl;
Eigen::VectorXf vec=Eigen::VectorXf::Random(10);
cout<<vec<<endl;
Eigen::VectorXf vec1(10);
for(int i=0;i<10;i++) vec1[i]=random();
cout<<vec1<<endl;
//转置操作transpose()
cout<<vec.transpose()<<endl;
//Eigen重载了*运算符,可直接用于矢量、矩阵之间的点乘
cout<<vec.transpose()*matrix.transpose()<<endl;
cout<<endl<<endl<<"SVD:"<<endl;
Eigen::MatrixXf A=Eigen::MatrixXf::Random(ROWS,COLS);
Eigen::JacobiSVD<Eigen::MatrixXf> svd(A,Eigen::ComputeThinU|Eigen::ComputeThinV);
Eigen::MatrixXf U=svd.matrixU();
Eigen::MatrixXf V=svd.matrixV();
Eigen::MatrixXf sigma=svd.singularValues();
Eigen::MatrixXf Sigma=Eigen::MatrixXf::Zero(MIDDLE,MIDDLE);
for(int i=0;i<MIDDLE;i++) Sigma(i,i)=sigma(i);
cout<<"SVD END"<<endl;
return 0;
}
上面的Eigen测试代码中,测试了矢量与矩阵的声明、初始化、数值访问、打印、转置、点乘、SVD分解。与ViennaCL配合使用时,以上功能已经足够了。特别是转置操作,经过测试,其性能比ViennaCL在GPU上进行矩阵转置的性能高很多。
















 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









