






 本文全面介绍了OpenCV 4.10.0版本的功能模块、数据类型与类对象,并深入探讨了Mat矩阵的操作方法、图像和视频处理流程。此外,还详细阐述了相机标定的过程与注意事项,以及OpenCV与其他工具如ROS和Qt的联合开发技巧。
本文全面介绍了OpenCV 4.10.0版本的功能模块、数据类型与类对象,并深入探讨了Mat矩阵的操作方法、图像和视频处理流程。此外,还详细阐述了相机标定的过程与注意事项,以及OpenCV与其他工具如ROS和Qt的联合开发技巧。
可点击OpenCV来自简书 /// OpenCV官网
OpenCV中的单位
棋盘格边长尺寸:mm
【机器视觉】
OPENCV
一、各个模块简介
1、 OpenCV4.10.0库功能全解
opencv的头文件
#include "opencv2/core/core_c.h"
#include "opencv2/core/core.hpp"
#include "opencv2/flann/miniflann.hpp"
#include "opencv2/imgproc/imgproc_c.h"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/photo/photo.hpp"
#include "opencv2/video/video.hpp"
#include "opencv2/features2d/features2d.hpp"
#include "opencv2/objdetect/objdetect.hpp"
#include "opencv2/calib3d/calib3d.hpp"
#include "opencv2/ml/ml.hpp"
#include "opencv2/highgui/highgui_c.h"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/contrib/contrib.hpp"
【calib3d】:其实就是就是Calibration(校准)加3D这两个词的组合缩写。这个模块主要是相机校准和三维重建相关的内容。基本的多视角几何算法,单个立体摄像头标定,物体姿态估计,立体相似性算法,3D信息的重建等等。
【contrib】:也就是Contributed/Experimental Stuf的缩写, 该模块包含了一些最近添加的不太稳定的可选功能,不用去多管。2.4.8之后有新型人脸识别, 立体匹配 ,人工视网膜模型等技术。
【core】: 核心功能模块,尤其是底层数据结构和算法函数。包含如下内容:
(1)OpenCV基本数据结构
(2)动态数据结构
(3)绘图函数
(4)数组操作相关函数
(5)辅助功能与系统函数和宏
【imgproc】: Image和Processing这两个单词的缩写组合。图像处理模块,这个模块包含了如下内容:
(1)线性和非线性的图像滤波
(2)图像的几何变换
(3)其它(Miscellaneous)图像转换
(4)直方图相关
(5)结构分析和形状描述
(6)运动分析和对象跟踪
(7)特征检测
【features2d】: d也就是Features2D, 2D功能框架 ,包含兴趣点检测子、描述子以及兴趣点匹配框架。包含如下内容:
(1)特征检测和描述
(2)特征检测器(Feature Detectors)通用接口
(3)描述符提取器(Descriptor Extractors)通用接口
(4)描述符匹配器(Descriptor Matchers)通用接口
(5)通用描述符(Generic Descriptor)匹配器通用接口
【flann】: Fast Library for Approximate Nearest Neighbors,高维的近似近邻快速搜索算法库, 包含两个部分:快速近似最近邻搜索和聚类。
【gpu】: 运用GPU加速的计算机视觉模块。
【highgui】: 也就是high gui,高层GUI图形用户界面,包含媒体的I / O输入输出, 视频捕捉、图像和视频的编码解码、图形交互界面的接口等内容。
【legacy】: 一些已经废弃的代码库,保留下来作为向下兼容。
【ml】: Machine Learning,机器学习模块, 基本上是统计模型和分类算法,包含如下内容:
(1)统计模型 (Statistical Models)
(2)一般贝叶斯分类器 (Normal Bayes Classifier)
(3)K-近邻 (K-NearestNeighbors)
(4)支持向量机 (Support Vector Machines)
(5)决策树 (Decision Trees)
(6)提升(Boosting)
(7)梯度提高树(Gradient Boosted Trees)
(8)随机树 (Random Trees)
(9)超随机树 (Extremely randomized trees)
(10)期望最大化 (Expectation Maximization)
(11)神经网络 (Neural Networks)
(12)MLData
【nonfree】: 也就是一些具有专利的算法模块 ,包含特征检测和GPU相关的内容。最好不要商用,可能会被告哦。
【objdetect】: 目标检测模块,包含Cascade Classification(级联分类)和Latent SVM这两个部分。
【ocl】: 即OpenCL-accelerated Computer Vision,运用OpenCL加速的计算机视觉组件模块。
【photo】: 也就是Computational Photography,包含图像修复和图像去噪两部分。
【stitching】: images stitching,图像拼接模块,包含如下部分:
(1)拼接流水线
(2)特点寻找和匹配图像
(3)估计旋转
(4)自动校准
(5)图片歪斜
(6)接缝估测
(7)曝光补偿
(8)图片混合
【superres】: SuperResolution,超分辨率技术的相关功能模块。
【ts】: opencv测试相关代码,不用去管他。
【video】: 视频分析组件,该模块包括运动估计,背景分离,对象跟踪等视频处理相关内容。
【Videostab】: Video stabilization,视频稳定相关的组件。
二 、数据类型与类对象
1 、数据类型(点类、size类、向量类、矩形类、指针类、异常类等)
6种数据类型在库中一般缩写为b=unsigned char, w=unsigned short, s=short,
i=int, f=float, d=double。
1.1 cv::Point类
优势:简单而且开销小。必要时,可转换为固定向量类或者固定矩阵类。
cv::Point{2,3}{b,s,i,f,d}
1.2 cv::Size类
Size类在实际操作时与Point类相似,而且可以与Point类互相转换。
两者区别在于Point类的数据成员是x和y,而Size类中对应的成员是width和height。
Size类的3个别名分别是cv::Size, cv::Size2i, cv::Size2f(其中前两个是等价的)。
1.3 cv::Scalar类
cv::Scalar直接从固定向量类模板实例中继承而来。
cv::Scalar是四维双精度向量的快速表示。
1.4 cv::Rect类
矩形类包含Point类的成员x和y(矩形左上角)和Size类的成员width和height(代表了矩形的大小)。
1.5 cv::RotatedRect类
该类包含一个中心点cv::Point2f、一个大小cv::Size2f和一个额外的角度float的容器。
1.6 固定矩阵类
固定矩阵类是为编译时就已知维度的矩阵打造的,这也是称为“固定”的原因。
因为它们内部的所有数据都是在堆栈上分配的,所以它们的分配和清除很快。
固定矩阵类实际上是一个模板,这个模板称为cv::Matx<>,但独立的矩阵通常
通过别名分配。这些别名的基础格式是cv::Matx{1,2,..6}{1,2,..6}{f,d}。
1.7 固定向量类
固定向量类是从固定矩阵类派生出来的。
固定向量模板cv::Vec{2,3,4,6}{b,s,w,i,f,d}。
固定向量类的最主要便利是它可以通过单个数索引各项,以及几个特定的额外的函数使常规矩阵运算有意义(比如叉乘)。
1.8 复数类
OpenCV中的复数类与STL复数类模板complex< >不一样,但与之兼容,可以相互转换。它们最大的区别在于成员获取。在STL类中,实部和虚部是通过成员函数real()和imag()获取的,而在OpenCV中,直接通过成员变量re和im获取。
复数类模板的别名是cv::Complexf和cv::Complexd,分别是单精度和双精度复数的别名。
1.9 辅助对象——cv::TermCriteria类
确定算法的终止条件。
cv::TermCriteria有三个成员变量(type,maxCount以及epsilon)
源码结构如下:
struct cv::TermCriteria(
Public:
//成员变量
enum
{
COUNT=1, //计算元素或者迭代次数最小值
MAX_ITER=COUNT, //最大迭代次数
EPS=2 //当满足该精确度时,迭代算法停止
};
//构造函数
TermCriteria::TermCriteria()
TermCriteria::TermCriteria(int type, int maxCount, double epsilon)
TermCriteria::TermCriteria(const CvTermCriteria& criteria)
//参数:
//type – 终止条件类型:
//maxCount – 计算的迭代数或者最大元素数
//epsilon – 当达到要求的精确度或参数的变化范围时,迭代算法停止
//type可选:
//TermCriteria::COUNT //达到最大迭代次数 =TermCriteria::MAX_ITER
//TermCriteria::EPS //达到精度
//TermCriteria::COUNT + TermCriteria::EPS //以上两种同时作为判定条件
);
上一个例子:
cv::TermCriteria criteria = cv::TermCriteria(
cv::TermCriteria::EPS + cv::TermCriteria::COUNT, 10, 0.1);
//COUNT=MAX_ITER(相等)
1.10 辅助对象——cv::Range类
cv::Range类用于确定一个连续的整数序列。构造函数cv::Range(int start, int end)中,范围包含初始值start,但不包含终止值end。
cv::Range类成员函数还有size(), empty()。
1.11 辅助对象——cv::Ptr模板和垃圾收集
指针模板的实例:可以通过调用类似
cv::Ptr<cv::Matx33f> p(new cv::Matx33f)
或
cv::Ptr<cv::Matx33f> p = cv::makePtr<cv::Matx33f>() #这种格式在3.0版本可以,在4.0版本好像不能用了
cv::Ptr<> 是线程安全的。
1.12 辅助对象——cv::Exception类和异常处理
请添加
1.13 辅助对象——cv::DataType<>模板
请添加
2、类对象
2.1 接口类
2.1.1 InputArray或OutputArray接口类
InputArray这个接口类可以是Mat、Mat_<T>、Mat_<T, m, n>、vector<T>、vector<vector<T>>、vector<Mat>。也就意味着当你看refman或者源代码时,如果看见函数的参数类型是InputArray型时,把上诉几种类型作为参数都是可以的。有时候InputArray输入的矩阵是个空参数,你只需要用cv::noArray()作为参数即可,或者很多代码里都用cv::Mat()作为空参。这个类只能作为函数的形参参数使用,不要试图声明一个InputArray类型的变量。如果在你自己编写的函数中形参也想用InputArray,可以传递多类型的参数,在函数的内部可以使_InputArray::getMat()函数将传入的参数转换为Mat的结构,方便你函数内的操作;必要的时候,可能还需要_InputArray::kind()用来区分Mat结构或者vector<>结构,但通常是不需要的。
三、OpenCV中的Mat(矩阵)
1、创建与初始化矩阵
请点击–> 【OpenCV3】cv::Mat的定义与初始化
请点击–> OpenCV Mat类详解和用法
请点击–> Opencv之Mat常用类成员
补充:创建矩阵
C++: void Mat::create(int rows, int cols, int type)
C++: void Mat::create(Size size, int type)
C++: void Mat::create(int ndims, const int* sizes, inttype)
参数:
ndims – 新数组的维数。 rows –新的行数。
cols – 新的列数。 size – 替代新矩阵大小规格:Size(cols, rows)。
type – 新矩阵的类型。 sizes – 指定一个新的阵列形状的整数数组。
示例:
cv::Mat srcImage = cv::imread("D:\\visual studio 2010\\Projects\\remap\\1.jpg");
cv::Mat dstImage;
dstImage.create(srcImage.size(),srcImage.type());
| imread的flags(不止3个) | 解释 |
|---|---|
| IMREAD_UNCHANGED | 如果设置,将加载的图像原样返回(带alpha通道,否则会被裁剪)。忽略EXIF方向。 |
| IMREAD_GRAYSCALE | |
| IMREAD_COLOR | 默认flags |
建立矩阵必须要指定矩阵存储的数据类型,得到矩阵Mat的类型( mat.type() ),图像处理中常用的几种数据类型如下:
CV_8UC{1,2,3,4} // 8位无符号单通道, 双通道,3通道,4通道
CV_8SC{1,2,3,4} // 8位短整型单通道, 双通道,3通道,4通道
CV_16UC{1,2,3,4} // 16位无符号单通道, 双通道,3通道,4通道
CV_16SC{1,2,3,4} // 16位短整型单通道, 双通道,3通道,4通道
CV_32SC{1,2,3,4} // 32位短整型单通道, 双通道,3通道,4通道
CV_32FC{1,2,3,4} // 32位浮点型单通道, 双通道,3通道,4通道
CV_64FC{1,2,3,4} // 64位浮点型单通道, 双通道,3通道,4通道
!!!!!强调:数组中的数据是按行连续组织的,因此不可以通过这种方式去访问一个指定的列。
int depth = img.depth(); // 获取图像的颜色位数,返回的是枚举类型的值(只针对单通道)
矩阵元素的数据类型:
| C1 | C2 | C3 | C4 | |
|---|---|---|---|---|
| CV_8U | 0 | 8 | 16 | 24 |
| CV_8S | 1 | 9 | 17 | 25 |
| CV_16U | 2 | 10 | 18 | 26 |
| CV_16S | 3 | 11 | 19 | 27 |
| CV_32S | 4 | 12 | 20 | 28 |
| CV_32F | 5 | 13 | 21 | 29 |
| CV_64F | 6 | 14 | 22 | 30 |
表头的 C1, C2, C3, C4 指的是通道(Channel)数,比如灰度图像只有 1 个通道,是 C1;JPEG格式 的 RGB 彩色图像就是 3 个通道,是 C3;PNG 格式的彩色图像除了 RGB 3个通道外,还有一个透明度通道,所以是 C4。大家还会发现 7 怎么没有被定义类型,这个可以看 OpenCV 源码,有如下所示的一行,说明 7 是用来给用户自定义的:
#define CV_USRTYPE1 7
如果仅仅是为了在数值计算前明确数据类型,那么看到这里就可以了;如果是要使用 at 方法访问数据元素,那么还需要下面一步。因为以单通道为例,at 方法接受的是 uchar 这样的数据类型,而非 CV_8U。在已知通道数和每个通道数据类型的情况下,指定给 at 方法的数据类型如下表所示:
| C1 | C2 | C3 | C4 | C6 | |
|---|---|---|---|---|---|
| uchar | uchar | cv::Vec2b | cv::Vec3b | cv::Vec4b | |
| short | short | cv::Vec2s | cv::Vec3s | cv::Vec4s | |
| int | int | cv::Vec2i | cv::Vec3i | cv::Vec4i | |
| float | float | cv::Vec2f | cv::Vec3f | cv::Vec4f | cv::Vec6f |
| double | double | cv::Vec2d | cv::Vec3d | cv::Vec4d | cv::Vec6d |
图像像素、通道操作
三通道彩色图像,则数据类型为Vec3b
cv::Vec3b vec3b = img.at<cv::Vec3b>(0,0);
uchar vec3b0 = img.at<cv::Vec3b>(0,0)[0];//第一个通道,对应于BGR类型的蓝色通道
uchar vec3b1 = img.at<cv::Vec3b>(0,0)[1];//第一个通道,对应于BGR类型的绿色通道
uchar vec3b2 = img.at<cv::Vec3b>(0,0)[2];//第一个通道,对应于BGR类型的红色通道
std::cout << "vec3b = " << vec3b << std::endl;
std::cout << "vec3b0 = " << (int)vec3b0 << std::endl;
std::cout << "vec3b1 = " << (int)vec3b1 << std::endl;
std::cout << "vec3b2 = " << (int)vec3b2 << std::endl;
二值化图像像素操作(数据类型为uchar)
// 这里inputmat是二值化图像的mat
inputmat.at<uchar>(y, x);
2、cv::Mat类函数列表
| cv::Mat函数(全)名称 | 描述 |
|---|---|
| cv::Mat::reshape(int cn, int rows=0) const | reshape函数既可以改变通道数,又可以对矩阵元素进行序列化,改变矩阵的形状 |
| cv::Mat::isContinuous() | 返回bool值,判断存储是否连续,如果矩阵的行之间没有空隙,返回true。补充: Mat的数据部分存储是按照行进行存储的,相同行内的数据是连续存储,行与行之间的存储是否有间隙,可以通过isContinuous函数来判断。对于11或1N矩阵总是连续的,一般使用Mat::create创建的矩阵总是连续的,而如果使用Mat::col、Mat::diag、Mat::rect等提取的矩阵一部分,或者外部分配的数据构造矩阵头,则此类矩阵可能不再连续存储。 |
| cv::Mat::clone() | m1 = m0.clone(); 将m0完全拷贝到m1中,同时拷贝m0中的所有数据,且拷贝的矩阵是连续的。 |
| void cv::Mat::convertTo( OutputArray m, int rtype, double alpha = 1, double beta = 0 ) const | 使用可选缩放将数组转换为另一种数据类型。主要是根据公式: m(x,y)=saturate_cast< rType >(α(∗this)(x,y)+β), m0.convertTo(m1, type, alpha, beta); 用于数据类型转换,但不能转换通道数,转换通道数用函数cv::cvtColor() 。 将m0中的元素转换成type类(CV_32F等)。 |
| cv::Mat::push_back() | m0.push_back(elem); 这些方法将一个或多个元素添加到矩阵的底部。它们模拟STL向量类的相应方法。当elem为Mat时,其类型和列数必须与容器矩阵中的相同。注意: 添加elem时,是深拷贝还是浅拷贝。 |
| cv::Mat::pop_back( size_t nelems = 1) | 该方法从矩阵底部删除一行或多行。 m0.pop_back(n); //从m0尾部移除n行,默认情况下n为1。 |
| cv::Mat::type() | m0.type(); //返回m0中元素的有效类型标识符(如CV_32FC3),不过返回的是一个数字。该方法返回一个矩阵元素类型。这是一个与CvMat类型系统兼容的标识符,如CV_16SC3或16位有符号的3通道数组,等等。 |
| cv::Mat::depth() | m0.depth(); //返回m0中单个通道中元素的有效类型标识符(如CV_32F)。该方法返回矩阵元素深度的标识符(每个单独通道的类型)。例如,对于16位有符号元素数组,该方法返回CV_16S。 |
| cv::Mat::channels() | m0.channels(); //返回m0中元素的通道数目。 |
| cv::Mat::size() | m0.size(); //以cv::Size对象的形式返回m0的大小。 |
| cv::Mat::empty() | m0.empty(); //如果数组中没有元素(如m0.total == 0 或 m0.data == NULL)则返回true。 |
| cv::Mat::ptr | 共有20种构造函数。常用形式: mat.ptr< type>(row)[col] , 对于Mat的ptr函数,返回的是<>中的模板类型指针,指向的是()中的第row行的起点,通常<>中的类型和Mat的元素类型应该一致,然后再用该指针去访问对应col列位置的元素 |
| MatExpr cv::Mat::inv ( int method = DECOMP_LU) const | 求矩阵的逆矩阵,method有3种:cv::DECOMP_LU(默认),cv::DECOMP_SVD,cv::DECOMP_EIG ,cv::DECOMP_CHOLESKY,cv::DECOMP_QR,DECOMP_NORMAL。 |
| Mat cv::Mat::cross (InputArray m) const | 计算两个三元素向量的外积。向量必须是相同形状和大小的3元素浮点向量。结果是与操作数具有相同形状和类型的另一个3元素向量。向量积,数学中又称外积、叉积,物理中称矢积、叉乘,是一种在向量空间中向量的二元运算。与点积不同,它的运算结果是一个向量而不是一个标量。并且两个向量的叉积与这两个向量和垂直。 |
| double cv::Mat::dot ( InputArray m ) const | 用法:A.dot(B) 计算两向量的点乘,又称内积,结果是一个标量。如果矩阵不是单列或单行向量,则使用从上到下从左到右的扫描顺序将它们视为1D向量。矢量必须具有相同的大小和类型。如果矩阵有多个通道,则所有通道的点积相加。 |
| cv::Mat::mul() | 计算两个Mat矩阵对应位元素的乘积,所以要求参与运算的矩阵A的行列和B的行列数一致。 函数原型:C++: MatExpr Mat::mul(InputArray m, double scale=1) const。 用法:Mat AB=A.mul(B); |
| 矩阵乘 A*B | 是以数学运算中矩阵相乘的方式实现的,即Mat矩阵A和B被当做纯粹的矩阵做乘法运算,这就要求A的列数等于B的行数时,才能定义两个矩阵相乘。如A是m×n矩阵,B是n×p矩阵,它们的乘积AB是一个m×p矩阵。 |
| cv::Mat::t() | 矩阵的转置运算 |
| cv::Mat::rowRange() cv::Mat::colRange() | rowRange为矩阵的指定行区间范围创建一个矩阵头,可取指定行区间元素; colRange为矩阵的指定列区间范围创建一个矩阵头,可取指定列区间元素。from官网 该函数包括左边界,但是不包括右边界。PS:这里的边界指的是下标索引。因为索引为0才表示第一行,而不是索引为1 表示第一行。 |
| Mat Mat::row( int i ) const Mat Mat::col( int j ) const | 创建一个指定行数的矩阵头并返回,新矩阵和原始矩阵共享一份基础数据函数原型,相当于是浅拷贝。 创建一个指定列数的矩阵头并返回,新矩阵和原始矩阵共享一份基础数据函数原型,相当于是浅拷贝。 |
| Mat Mat::diag(int d) const ----- --------static Mat Mat::diag(const Mat& matD) | 提取或创建矩阵对角线。 d: 对角线的索引值,可以是以下的值: d=0 是主对角线; d>0表示下半部的对角线。例如:d=1 对角线是紧挨着住对角线并位于矩阵下方; d<0表示来自矩阵上半部的对角线。例如:d= -1 表示对角线被设置在对角线的上方并紧挨着; matD: 单列用于形成矩阵对角线的列。 |
| void Mat::copyTo(OutputArray m) const void Mat::copyTo(OutputArray m, InputArray mask) const | 和clone相似,将矩阵复制到另一个矩阵中去。 m :目标矩阵。如果它的尺寸和类型不正确,在操作之前会重新分配。 mask: 操作掩码。它的非零元素表示矩阵中某个要被复制。 |
| Mat& Mat::setTo(const Scalar& s, InputArray mask=noArray()) | 功能: 将阵列中所有的或部分的元素设置为指定的值。mask必须为CV_8U型,可以有1个或多个通道。用法:src.setTo(value, mask)。当默认不添加mask的时候,表明mask是一个与原图尺寸大小一致的且元素值==全为非 0 ==的矩阵,因此不加mask的时候,会将原矩阵的像素值全部赋值为value;当带有mask这个参数的时候,对于mask中非零的位置,在src中的对应位置的元素会被置为value值,其他部分不变。例如: 1、有一个Mat src,想将他的值全部设置成0,则可以src.setTo(0); 2、setTo还有更为高级的用法,对于一个已知的src,我们要将其中大于或者小于某个值的像素值设置为指定的值,则可以如下:src.setTo(0,src < 10);这句话的意思是,当src中的某个像素值小于10的时候,就将该值设置成0。 |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::Mat:: | |
| cv::UMat | 它跟Mat有着多数相似的功能和相同的API函数,通过使用UMat对象,OpenCV会自动在支持OpenCL的设备上使用GPU运算,在不支持OpenCL的设备仍然使用CPU运算,这样就避免了程序运行失败,而且统一了接口。 |
3、独立获取数组元素(访问)
请点击-> cv::Mat像素遍历方式(3种)
请点击-> 访问Mat中每个像素的值
4、cv::Mat和std::vector之间的相互转换
1、 cv::Mat转换成std::vector
第(1)种:
cv::Mat mat;
std::vector<type_> vec;
vec = (std::vector<type_>)(mat.reshape(0,1));
reshape函数原型:C++: Mat Mat::reshape(int cn, int rows=0) const
cn: 表示通道数(channels), 如果设为0,则表示保持通道数不变,否则则变为设置的通道数。
rows: 表示矩阵行数。如果设为0,则表示保持原有的行数不变,否则则变为设置的行数。
用法:
cv::Mat data = Mat(20, 30, CV_32F);
cv::Mat dst = data.reshape(0, 1);
第(2)种:
cv::Mat M(rows,cols, CV_32FC1 );
std::vector<float> V;
V.assign ( (float*)M.datastart, (float*)M.dataend );
2、 std::vector转换成cv::Mat
(1)
使用Mat的构造函数
std::vector<type_> vec;
cv::Mat mat;
mat = cv::Mat(vec, true);
(2)
std::vector<type_> V;
cv::Mat M2=cv::Mat(rows,cols,CV_32FC1);
memcpy(M2.data,V.data(),V.size()*sizeof(type_));
memcpy函数
头文件:
C:#include<string.h>
C++:#include<cstring>
函数原型:
void *memcpy(void *dest, const void *src, size_t n);
功能:
从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中。
3、 cv::Mat_ 与cv::Mat
/
cv::Mat_
创建一个cv::Mat_并赋值
cv::Mat_<double> mat(3,3); //要注明类型double
mat(0,0)=VIRTUAL_FOCAL;
mat(0,1)=0;
mat(0,2)=roiSize_x/2;
mat(1,0)=0;
mat(1,1)=VIRTUAL_FOCAL;
mat(1,2)=roiSize_y/2;
mat(2,0)=0;
mat(2,1)=0;
mat(2,2)=1;
使用cv::Mat_类模板的话,at()方法不需要指明类型,如下:
cv::Mat_<Vec2f> m( 10, 10 );
m.at( i0, i1 ) = cv::Vec2f( x, y );
/
cv::Mat
...........
4、CvMat,Mat和IplImage之间的转化和拷贝
请点击-> CvMat,Mat和IplImage之间的转化和拷贝
5、图像
1、jpg
(1)JPEG英文全名是Joint Photographic Experts Group,JPG格式是一种有损压缩格式。
(2)由于JPG是有损格式,将图像压缩在很小的储存空间,一定程度上会造成图像数据的损伤,会造成锯齿状边缘。
(3)
2、png
(1)PNG图片格式全称是Portable Network Graphics,PNG是无损压缩算法的位图格式。
(2)PNG可以为原图像定义256个透明层次,使图片边缘平滑融合,从而消除图片锯齿边缘。
(3)PNG支持透明效果,可以作为背景透明的图片使用。
(4)PNG图片,体积小、清晰度高,锯齿情况少,并且兼容性非常强,PNG便携式网络图形,是一种采用无损压缩算法的位图格式,支持索引、灰度、RGB三种颜色方案以及Alpha通道等特性。
3、svg
SVG是一种用XML定义的语言,用来描述二维矢量及矢量/栅格图形。它具有现在网络流行的PNG和JPEG格式无法具备的优势:可以任意放大图形显示,但绝不会以牺牲图像质量为代价;可在SVG图像中保留可编辑和可搜寻的状态;平均来讲,SVG文件比JPEG和PNG格式的文件要小很多,因而下载也很快。可以相信,SVG的开发将会为Web提供新的图像标准。
X、图像的大小(所占存储空间)与哪些因素有关?
(1)分辨率
分辨率是指一张图像在每英寸内有多少像素点,相同尺寸的两张图片,分辨率越高,图像文件越大,分辨率相同的两张图片,图像尺寸越大,图像文件越大,也就是说图像文件的大小取决于前两者的参数,随这两者的改变而改变。
(2)图像深度
图像深度是指存储每个像素所用的位数,它也是用来度量图像的色彩分辨率的。它确定了彩色图像的每个像素可能有的色彩数,或者确定灰度图像的每个像素可能有的灰度级数。它决定了色彩图像中可能出现的最多的色彩数,或者灰度图像中的最大灰度等级。
图像深度是单个像素点的色彩详细度,如16位(65536色),32位等。比如一幅单色图像,若每个像素有8位,则最大灰度数目为2的8次方,即256.一幅彩色图像RGB 3个温良的像素位数分别为4,4,2,则最大颜色数目为2的4+4+2次方,即1024,就是说像素的深度为10位,每个像素可以是1024种颜色中的一种,例如:一幅画的尺寸是 1024*768,深度为16,则它的数据量为1.5M。
计算如下:
1024 * 768 * 16bit = (1024 * 768 * 16) / 8字节
= [(1024 * 768 * 16) / 8] / 1024KB
= {[(1024 * 768 * 16) / 8] / 1024} / 1024MB
=1.5MB。
(3)存储格式
不同的存储格式,压缩技术也会导致图像的大小不同,例如同一张图片,用JPG、PNG、BMP等格式图像大小会有差异,这个知道就行,不进行深度分析。
6、视频流
请点击-> 基于OpenCV的网络实时视频流传输
请点击-> 计算机视觉——利用openCV与Socket结合进行远程摄像头实时视频传输并保存图片数据
四、变换与投影、相机与标定
1、变换与投影
1.1 透视变换
透视变换可以通过一个矩形产生任何梯形。
1、 请点击-> 透视变换——cv::getPerspectiveTransform()与cv::warpPerspective()详解
2、 请点击-> 鱼眼相机外参的计算和图像的透视变换
3、 请点击-> uvc鱼眼相机畸变矫正标定、透视图变换为IPM图(鸟瞰图/俯视图)
IPM 鸟瞰图公式转换与推导
1.2 透视投影
1.3 仿射变换
仿射变换可以通过一个矩形产生任何平行四边形。
1.4 仿射投影
1.X 重映射
2、相机
平行光管成像原理与求待测模组的焦距:

2.1 相机内参矩阵
请点击–> 相机内参矩阵 ( Camera Matrix )
请点击–> 针孔相机模型和相机内参矩阵K
像素坐标系与(物理)成像平面之间,相差了一个缩放和一个原点的平移。
相机的内参是:
1
/
d
x
、
1
/
d
y
、
u
0
、
v
0
、
f
1/dx、1/dy、u0、v0、f
1/dx、1/dy、u0、v0、f
opencv相机内参矩阵
K
K
K:

常用的像素尺寸(pixel size)dx一般为
内参矩阵
K
K
K 包括5个未知参数。一般情况下,摄像机倾斜因子s=0。因此
K
K
K 就只有4个未知参数了,分别为
f
x
f_x
fx、
f
y
f_y
fy、
u
0
(
c
x
)
u_0(c_x)
u0(cx)、
v
0
(
c
y
)
v_0(c_y)
v0(cy),它们的单位是像素。其实opencv中的
f
x
f_x
fx也就是
f
∗
s
x
f*s_x
f∗sx,其中
f
f
f是物理焦距,
s
x
s_x
sx的单位是像素
/
/
/每毫米,也就是上面的1/dx,所以
f
x
f_x
fx的单位是像素。


2.2 相机畸变模型
COD:畸变中心(Center of Distortion) - 在传感器上的 ( x , y ) (x,y)(x,y) 表示拟合的最佳对称中心 (unit:pixel);
PP:主点(Principle Point) - 透镜光轴与传感器表面的交点
图像坐标系,坐标去畸变公式:

畸变参数是:
k
1
,
k
2
,
k
3
,
k
4
,
k
5
,
k
6
k1,k2,k3,k4,k5,k6
k1,k2,k3,k4,k5,k6 为径向畸变系数,
p
1
,
p
2
p1,p2
p1,p2 是切向畸变系数。
径向畸变偏移示意图:

切向畸变偏移示意图:
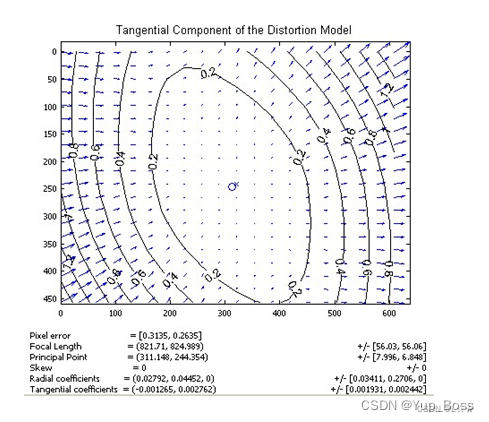
2.2.1 径向畸变
径向畸变发生在相机坐标系转像物理坐标系的过程中。枕形畸变(Pincushion distortion)又叫做正畸变,即垂轴放大倍率随视场角的增大而增大的畸变,它使对称于光轴的正方形物体的像呈现枕形。径向畸变系数k<0。桶形畸变(Barrel distortion)又叫做负畸变,即垂轴放大倍率随视场角的增大而减小的畸变,它使对称于光轴的正方形物体的像呈现桶形。径向畸变系数k>0。
枕形畸变(Pincushion Distortion)又称枕形失真,它是指光学系统引起的成像画面向中间“收缩”的现象。枕形畸变在长焦镜头成像时较为常见。使人变瘦高的哈哈镜成像属于枕型畸变。
桶形畸变 (Barrel Distortion)又称桶形失真,是指光学系统引起的成像画面呈桶形膨胀状的失真现象。桶形畸变在摄影镜头成像尤其是广角镜头成像时较为常见。使人变矮胖的哈哈镜成像是桶型畸变的一个比较形象的例子。
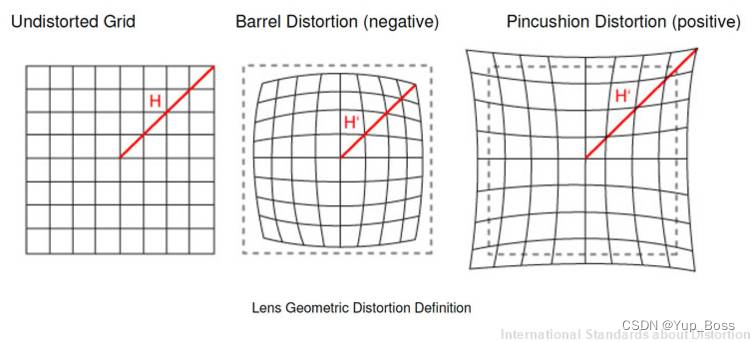
2.2.2 切向畸变
切向畸变:产生的原因是透镜不完全平行于图像。
2.3 相机外参



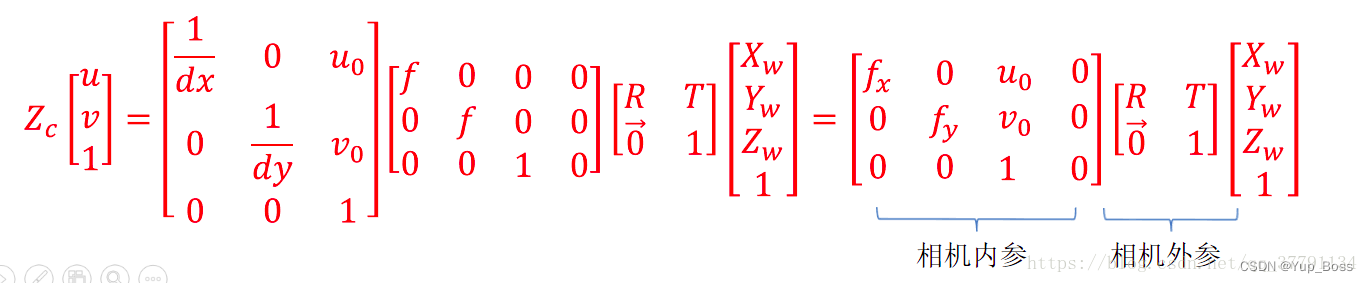
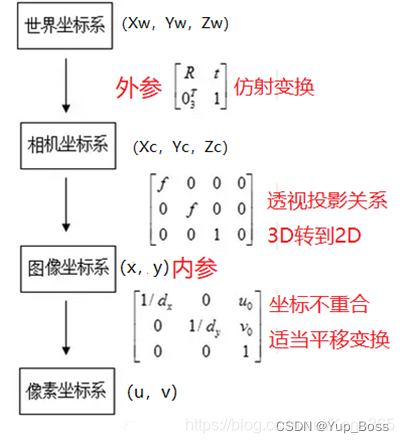
计算相机运动
| 方法 | 概念解释 |
|---|---|
| 对极约束 | 2D-2D,通过二维图像点的对应关系,恢复两帧之间相机的运动。作用:在已知 2D 的像素坐标的前提下,根据两幅图像间多组2D像素点对来估计相机的运动。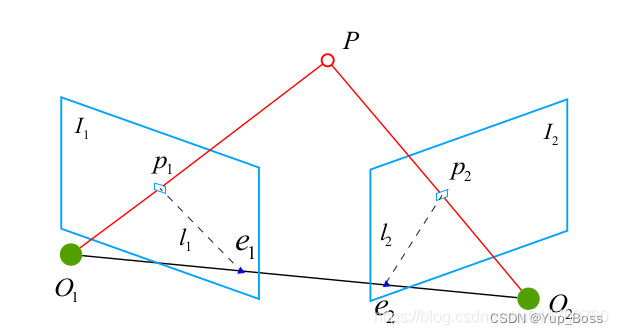 首先,连线 O1p1 和连线 O2p2 在三维空间中会相交于点 P 。这时候点O1 , O2 , P 三个点可以确定一个平面,称为极平面(Epipolar plane)。O1O2 连线与像平面 I1 , I2 的交点分为 e1 , e2 。e1 , e2 ,称为极点(Epipoles),O1O2 被称为基线(Baseline)。称极平面与两个像平面 I1 , I2 之间的相交线 L1 , L2 为极线(Epipolar line)。对极约束之所以称为约束,是因为我们在不知道P的真实空间位置的时候,通过几何关系将P点在第二帧图像上可能的投影位置约束在了一条直线上(即极线L2)。然后,通过特征匹配,我们确定p2与p1一样,都是空间点P的投影。 |
| PnP | 3D-2D,求解3D到2D点对运动的方法。已知3D空间点及其在相机投影位置时,求解相机运动。 |
| ICP | 3D-3D,配对好的3D点,已知世界坐标系下的3D点和相机坐标系下的3D点。 |
| NDT |
请点击–> 像素坐标转到世界坐标时相机坐标系中的
Z
c
Z_c
Zc值求解-理论公式 ,可用于验证外参标定结果准确性。
请点击–> 代码链接
代码如下:
cv::Mat uvPoint = (cv::Mat_<double>(3,1) << 363, 222, 1);
cv::Mat Mat_1 = rotationMatrix.inv() * cameraMatrix.inv() * uvPoint;
cv::Mat Mat_2 = rotationMatrix.inv() * tvec;
//285 represents the height Zw
// s Equivalent to Zc
double s = (285 + Mat_2.at<double>(2,0))/Mat_1.at<double>(2,0));
std::cout << "P = " << rotationMatrix.inv() * (s * cameraMatrix.inv() * uvPoint - tvec) << std::endl;
一文了解PnP算法,python opencv中的cv2.solvePnP()的使用,以及使用cv2.sovlePnP()方法标定相机和2D激光雷达
PnP(Perspective-n-Point)问题就是在已知世界坐标系下N个空间点的真实坐标以及这些空间点在图像上的投影,如何计算相机所在的位姿。
外参求解函数: cv::solvePnP()
| flags | 名词解释及要点 |
|---|---|
| (默认)SOLVEPNP_ITERATIVE = 0 | 适合点在同一平面上的情况。该方法基于Levenberg-Marquardtoptimization(列文伯格-马夸尔特算法)迭代求解PNP问题,实质是迭代求出重投影误差最小的解,这个解显然不一定是正解。迭代法调用cvFindExtrinsicCameraParams2,进而使用SVD分解并调用cvFindHomography,而cvFindHomography需要至少4组点。 |
| SOLVEPNP_EPNP = 1 | 需要4对不共面的(对于共面的情况只需要3对)3D-2D匹配点,是目前最有效的PnP求解方法。深入EPnP算法 |
| SOLVEPNP_P3P = 2 | P3P只使用4组点,3组求出多个解,第四组确定最优解 |
| SOLVEPNP_DLS = 3 | opencv3版本的算法当前是不稳定的,至少四点不在同一平面 |
| SOLVEPNP_UPNP = 4 | opencv3版本的算法当前是不稳定的 |
| SOLVEPNP_AP3P = 5 | AP3P只使用4组点,3组求出多个解,第四组确定最优解 |
| SOLVEPNP_IPPE = 6 | 输入点必须 >= 4 并且对象点必须共面 |
| SOLVEPNP_IPPE_SQUARE = 7 | 适用于标记姿势估计的特殊情况。 输入点数必须为 4。对象点必须按顺序定义。 |
| SOLVEPNP_SQPNP = 8 | |
2.4 相机投影模型
缩略词与术语
( c x , c y ) ( c_x , c_y ) (cx,cy) 写的是 光心 或 principle point(PP),不是畸变中心(COD)!
| Term | Description |
|---|---|
| COD | 畸变中心(Center of Distortion) - 在传感器上的 ( x , y ) (x,y)(x,y) 表示拟合的最佳对称中心 (unit:pixel) |
| DM | 畸变模型(Distortion Model) |
| EFL | 有效焦距(Effective Focal Length) |
| Pinhole Model FL | 针孔模型焦距(Pinhole Model Focal Length) - 图像去畸变后的模型焦距 (unit:pixel) |
| FOV | 视野(Field of View)视场角 |
| PP | 主点(Principle Point) - 透镜光轴与传感器表面的交点 |
| LPP | 透镜主平面(Lens Primary Plane) |
请点击–> 相机模型–针孔相机投影(pinhole camera model)
请点击–> 相机模型–鱼眼模型(fisheye camera model)
请点击–> 相机模型–鱼眼模型/Omnidirectional Camera(1)
请点击–> 相机模型–鱼眼模型/鱼眼镜头标定基本原理及实现(2)
请点击–> VinsFusion中的MEI模型解析
[需翻墙]请点击–> OCamCalib: Omnidirectional Camera Calibration Toolbox for Matlab
3、旋转变换
请点击–> 旋转变换(一)旋转矩阵
三维旋转的表示:
1、欧拉角:简单易懂,但有万向节锁问题。
2、旋转矩阵:可以累乘,但有误差累计问题。
3、四元数:

4、旋转矩阵及左右乘的区别
请点击–> 旋转矩阵及左右乘的意义,看这一篇就够了
5、标定相关
相机标定方法分3类:
1.传统摄像机标定方法
特点:利用已知的景物结构信息。常用到标定块。
优点:可以使用于任意的摄像机模型,标定精度高
不足:标定过程复杂,需要高精度的已知结构信息。在实际应用中很多情况下无法使用标定块。
常用方法:Tsai两步法、张氏标定法
2.主动视觉摄像机标定方法
特点:已知摄像机的某些运动信息
优点:通常可以线性求解,鲁棒性比较高
不足:不能使用于摄像机运动未知和无法控制的场合
常用方法:主动系统控制相机做特定运动
3.摄像机自标定方法
特点:仅依靠多幅图像之间的对应关系进行标定
优点:仅需要建立图像之间的对应,灵活性强,潜在应用范围广。
不足:非线性标定,鲁棒性不高
常用方法:分层逐步标定、基于Kruppa方程
以张正友标定法为例:使用二维方格组成的标定板进行标定,采集标定板不同位姿图片,提取图片中角点像素坐标,通过单应矩阵计算出相机的内外参数初始值,利用非线性最小二乘法估计畸变系数,最后使用极大似然估计法优化参数。该方法操作简单,而且精度较高,可以满足大部分场合。
请点击–> 一文读懂重投影误差
请点击–> 鱼眼镜头的成像原理到畸变矫正(完整版)
请点击–> 张正友标定算法原理详解
相机标定的目的:
1、相机标定的第一个目的就是获得相机的内参矩阵和外参矩阵。
2、相机标定的第二个目的就是获得相机的畸变参数,进而对拍摄的图片进行去畸变处理。
5.1 双目标定、三维重建(附加)
请点击–> OPENCV3.0 双目立体标定
请点击–> Camera Calibration and 3D Reconstruction(内含各种标定函数与3D重建函数)
请点击–> 双目测距与三维重建的OpenCV实现问题集锦(一)图像获取与单目标定
请点击–> 双目测距与三维重建的OpenCV实现问题集锦(二)双目定标与双目校正
请点击–> 双目测距与三维重建的OpenCV实现问题集锦(三)立体匹配与视差计算
请点击–> 双目测距与三维重建的OpenCV实现问题集锦(四)三维重建与OpenGL显示
请点击–> 双目三维重建系统(双目标定+立体校正+双目测距+点云显示)Python
附加:三维重建
1、三维重建(知识点详细解读、主要流程)
2、三维重构 基础知识、三维数据、重建流程
三角测量(测距原理)
视差是指在左右摄像机观察得到的相同特征在x坐标上的差值,如下图中的d 。
提高三角化的精度的方法:(1)提高特征点的提取精度,也就是提高图像分辨率——但这会导致图像变大,增加计算成本;(2)使平移量增大。但是,这会导致图像的外观外观发生明显的变化,比如箱子原先被挡住的侧面被显示出来,或者物体的光照发生变化,等等。

图1. 双摄像头模型俯视图

图2, 双摄像头模型立体视图
在这种简化的情况下,可以发现深度与视差成反比,通过相似三角形容易求出深度Z,得到下式:

得出结论,立体视觉系统只有在物体与摄像机距离较近时才具有较高的深度分辨率,如下图所示。

请点击–> 双目相机选择——镜头与相机的参数介绍及选择
5.2 标定原理讲解(公式推导)
请点击–> 最详细、最完整的相机标定讲解
请点击–>相机标定(具体过程详解)张正友、单应矩阵、B、R、T
请点击–>相机标定系列(二)单应矩阵
请点击–>单应性(homography)变换的推导
5.3 标定板生成与创建
请点击–> 自动生成各种标定板
请点击–> 代码生成Aprilgrid标定板
请点击–> 现有已生成好的apriltag标定板样例
请点击–> 记录一下有关ChArUco标定板
请点击–> 相机标定与3D重建(1)创建标定板(上)
请点击–> OPENCV官网–aruco相关函数介绍(ArUco Marker Detection)
5.4 提高标定精度的注意事项
请点击–> 相机标定过程中的注意事项
请点击–> 摄像机高精度标定的一些方法
1、相机镜头标靶硬件搭配:
①同样视场范围内相机的分辨率越大,标定精度越高;
②镜头决定视场范围,标靶大小小于视场的1/5时会减小摄像机的标定精度。
③图像张数要求15-20张(但并不是越多越好),标靶出现在图像的任意位置,标靶平面与相机平面倾斜角度小于45度。
2、操作技巧:
①将标靶放在相机景深范围内,调节好镜头焦距和光圈,使标靶能够清晰成像;
②标定是将标靶放在测量区域内进行标定,在哪儿测量在那儿标定;
③标定时标靶处于静止状态或小幅度的晃动,减少由于相机的曝光时间引起的运动模糊造成的误差;
④使标靶尽可能多的放置在系统测量范围内不同位置进行标定;
⑤在测量范围的深度方向上(Z方向)有一定的平移,或绕X轴和Y轴有一定的旋转;
3、外界环境干扰:
①光线过亮或过暗,标靶特征圆与背景对比度低,会引起检测不到标靶,或检测精度低;
②光照不均匀,使得标靶部分过亮或过暗会也引起检测不到标靶,或检测精度低;
5.5 单目相机标定
请点击–> 鱼眼相机标定-基于张正友标定法
请点击–> 使用Ceres库进行鱼眼相机标定(迭代优化)来自Github
请点击–> OpenCV 相机校正过程中,calibrateCamera函数projectPoints函数的重投影误差的分析
请点击–> 相机标定(1)内\外参矩阵和畸变矩阵
请点击–> 相机内参模型Mei/omni-directional详解
请点击–> 相机标定和双目相机标定标定原理推导及效果展示 (内含内参矩阵求解)
相机标定(具体过程详解)张正友、单应矩阵、B、R、T【单应矩阵求内参和外参】
5.6 立体(多面)标定板标定
请点击–> 立体(多面)标定板标定,棋盘格图像角点识别代码-github
五、OpenCV中函数
1、cv工具函数列表
| CV工具函数名称 | 描述 |
|---|---|
| 基本的矩阵和图像算子 | 此处开始 |
| cv::abs() | 计算矩阵中所有元素的绝对值 |
| cv::absdiff(src1, src2, dst) | 计算两个矩阵差值的绝对值 |
| cv::add(InputArray src1, InputArray src2, OutputArray dst, InputArray mask = noArray(), int dtype = -1) | 实现两个矩阵逐元素相加 |
| addWeighted(InputArray src1, double alpha, InputArray src2, double beta, double gamma, OutputArray dst, int dtype = -1) | 实现两个矩阵逐元素加权求和,可用于图像融合。addWeighted()函数用法总结 |
| OpenCV:对图像的位操作bitwise_and(与),bitwise_or(或),bitwise_not(非),bitwise_xor(异或) | 适用于下面 4 个(原理:将像素值转为二进制,再进行位运算) |
| cv::bitwise_and | 计算两个矩阵逐元素按位与 |
| cv::bitwise_not | 计算两个矩阵逐元素按位非 |
| cv::bitwise_or | 计算两个矩阵逐元素按位或 |
| cv::bitwise_xor | 计算两个矩阵逐元素按位异或 |
| cv::calcCovarMatrix() | 给定一些向量,假设向量表示的点是近似的高斯分布,,那么该函数将计算这些点的均值和协方差矩阵。cv::calcCovarMatrix()函数的输入输出矩阵都应该是相同的浮点型。结果矩阵的尺寸应该是n x n或m x m,取决于计算的是标准协方差还是scrambled协方差,应该注意的是,使用cv::Mat*形式时,samples的向量输入不一定要是一维的,它们也可以是二维对象。 |
| void cv::cartToPolar(cv::InputArray x, cv::InputArray y, cv::OutputArray magnitude, cv::OutputArray angle, bool angleInDegrees = false) | 用于将直角坐标映射到极坐标。默认以弧度来保存角度值,如果参数angleInDegrees设置为true,角度值以角度(0,360)来保存。 |
| void cv::polarToCart(cv::InputArray magnitude, cv::InputArray angle, cv::OutputArray x, cv::OutputArray y, bool angleInDegrees=false) | 用于将极坐标转换为直角坐标 |
| bool cv::checkRange(cv::InputArray src, bool quiet = true, cv::Point* pos = 0, double minVal = -DBL_MAX, double maxVal = DBL_MAX ); | 函数cv::CheckRange()检查输入的矩阵的每一个元素,并确定该元素是否在给定范围内。范围由参数minVal和maxVal设置。但是如果为NaN或inf值也会被认为超出范围。如果找到超出范围的值,如果quiet设置为false,会抛出异常。如果所有值都在范围内,cv::cehckRange()的返回值为true;如果有任何值超出范围,cv::checkRange()的返回值为false。如果指针pos不为NULL,则第一个异常值的位置存储在pos中。 |
| void compare(InputArray src1, InputArray src2, OutputArray dst, int cmpop); | 应用所选择的比较运算符,对两个矩阵中的所有元素比较 |
| bool cv::completeSymm(cv::InputArray mtx, bool lowerToUpper = false); | 给定一个二维矩阵mtx,cv::completeSymm()通过复制来使矩阵对称。简单说就是使用该函数后的矩阵是一个对称矩阵,选择上三角被复制还是下三角被复制根据函数参数lowerToUpper选择,根据参数含义也可以理解。 lowerToUpper = true,下三角形的元素被复制到上三角形; lowerToUpper = false,上三角形的元素被复制到下三角形; |
| void cv::convertScaleAbs( cv::InputArray src, // 输入数组 cv::OutputArray dst, // 输出数组 double alpha = 1.0, // 乘数因子 double beta = 0.0 // 偏移量); | 该操作可实现图像增强等相关操作。缩放矩阵,取绝对值,然后转换为8位无符号数。convertScaleAbs( )可把任意类型的数据转化为CV_8UC1。 它的原理/用法为: (1)若像素值-255 < src * alpha + beta < 255,取绝对值; (2)若像素值 alpha + beta >= 255 或 src * alpha + beta <= -255,取255,不可溢出。 |
| int cv::countNonZero(cv::InputArray mtx) | 函数返回矩阵中的非0像素个数。使用时需要注意输入矩阵必须是单通道矩阵,否则会抛出异常。 |
| cv::dct (InputArray src, OutputArray dst, int flags=0) | 根据flags执行离散余弦变换或者离散余弦逆变换。 |
| double cv::determinant(cv::InputArray mat); | 计算方阵的行列式 |
| cv::dft() | 实现离散傅里叶变换及其逆变换。 |
| cv::divide() | 有两种用法。实现两个矩阵逐元素相除 |
| bool cv::eigen ( InputArray src,OutputArray eigenvalues, OutputArray eigenvectors = noArray() ) | 计算方阵的特征值和特征向量。src:输入矩阵,只能是 CV_32FC1 或 CV_64FC1 类型的方阵(即矩阵转置后还是自己)。备注: 对于非对称矩阵,可以使用 cv::eigenNonSymmetric() 计算特征值和特征向量。 |
| cv::exp() | 实现矩阵的逐元素求指数幂 |
| void cv::flip(InputArray src, OutputArray dst, int flipCode); | 绕选定的轴翻转矩阵,包含垂直翻转,水平翻转,以及垂直水平翻转 |
| void gemm(InputArray src1, InputArray src2, double alpha, InputArray src3, double gamma, OutputArray dst, int flags=0 ) | 实现广义矩阵乘法,广义矩阵乘法(GEMM)。 |
| cv::getConvertElem() | 获取单像素类型转换函数 |
| 图像像素类型 | uchar: 灰度图像像素,单个值 Vec3b:彩色图像像素,3个值 |
| cv::getConvertScaleElem() | 获取单像素类型的转换和缩放函数 |
| void cv::idct(cv::InputArray src, cv::OutputArray dst, int flags); | 计算矩阵的离散余弦逆变换,相当于调用带参数的dct()。 |
| cv::idft() | 计算矩阵的离散傅里叶逆变换,相当于调用带参数的dft()。 |
| void cv::inRange(cv::InputArray src, cv::InputArray upperb, cv::InputArray lowerb, cv::OutputArray dst ); // dst array类型:cv::U8C1 type | 判断src中的元素是否在upperb和lowerb之间,满足置为255,否则0。 |
| cv::invert() | 求矩阵的逆, 函数原型:double cv::invert(InputArray src, OutputArray dst, int flags = DECOMP_LU ) |
| void cv::log( cv::InputArray src, cv::OutputArray dst); | 计算矩阵逐元素的自然对数 |
| void cv::magnitude(cv::InputArray x, cv::InputArray y, cv::OutputArray dst); | 计算直角坐标系转换成极坐标系的幅值。 |
| void cv::phase( cv::InputArray x, cv::InputArray y, cv::OutputArray dst, bool angleInDegrees = false); | 对二维矢量场计算笛卡尔-极坐标转换的方位角(角度)部分。 |
| cv::LUT() | 将矩阵转换为查找表的索引 |
| cv::Size cv::mahalanobis(cv::InputArray vec1, cv::InputArray vec2, cv::OutputArray icovar); | 计算两个向量之间的马氏距离。马氏距离(Mahalanobis distance)表示点与一个分布之间的距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是,它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的),并且是尺度无关的(scale-invariant),即独立于测量尺度。对于一个均值为μ,协方差矩阵为Σ的多变量向量,其马氏距离为sqrt( (x-μ)'Σ^(-1)(x-μ) )。 |
| cv::max() | 计算矩阵src1和src2中每个对应的像素对的最大值。 |
| cv::min() | 计算矩阵src1和src2中每个对应的像素对的最小值。 |
| cv::Scalar cv::mean(cv::InputArray src, cv::InputArray mask = cv::noArray()); | 计算src矩阵的均值。 |
| void cv::meanStdDev(cv::InputArray src, cv::OutputArray mean, cv::OutputArray stddev, cv::InputArray mask = cv::noArray() ); | 计算矩阵元素的均值和和标准差 |
| void merge(const vector<cv::Mat>& mv, cv::OutputArray dst); mv : STL-style array of arrays | 将多个二维矩阵合并成一个多维矩阵。 |
| cv::minMaxLoc() 有两个重载函数 | 计算矩阵的最大最小值,并返回其位置。 |
| cv::minMaxIdx() 有两个重载函数 | 计算单通道矩阵的最大最小值,并返回其位置。 |
| cv::mixChannels() 有两个重载函数 | 对于输入图像的通道按照给定的顺序重新组合(打乱原来的通道顺序)。 |
| cv::mulSpectrums() | 计算两个傅里叶谱的逐元素乘积 |
| void cv::multiply(InputArray src1, InputArray src2, OutputArray dst, double scale = 1, int dtype = -1) | 计算两个矩阵的对应元素乘积 |
| void cv::mulTransposed(cv::InputArray src1, cv::OutputArray dst, bool aTa, cv::InputArray delta = cv::noArray(), double scale = 1.0, int dtype = -1 ); | 计算矩阵和其转置的乘积 |
| cv::norm() 有三个重载函数 | 计算一个矩阵的范数,或者如果提供两个矩阵,该函数也可以计算两个矩阵间的各种距离范数。 函数原型:double cv::norm (InputArray src1, int normType=NORM_L2, InputArray mask=noArray()) |
| cv::normalize() | 两个作用: 调整矩阵的值范围(归一化处理)、规范化矩阵的范数为某个值。有两个重载函数,from官网 |
| void cv::perspectiveTransform(cv::InputArray src, cv::OutputArray dst, cv::InputArray mtx ); | 实现一系列向量的透视矩阵变化,执行一系列点的平面投影变换。 |
| void cv::polarToCart( cv::InputArray magnitude, cv::InputArray angle, cv::OutputArray x, cv::OutputArray y, bool angleInDegrees = false ); | 已知角度和幅值,从向量场的极坐标中计算笛卡尔坐标(x,y)。 |
| void cv::pow(cv::InputArray src, double p, cv::OutputArray dst ); | 对矩阵逐元素取p次幂。 |
| void cv::randu(cv::InputOutArray mtx, cv::InputArray low, cv::InputArray high ); | 用均匀分布的随机数填充给定的矩阵 |
| void cv::randn( cv::InputOutArray mtx, cv::InputArray mean, cv::InputArray stddev ); | 用正态分布的随机数填充给定的矩阵 |
| cv::randShuffle( InputOutputArray dst, double iterFactor = 1.0, RNG* rng = 0 ) | 随机打乱矩阵元素 |
| void cv::reduce(InputArray _src, OutputArray _dst, int dim, int rtype, int dtype=-1) | 通过特定的操作将二维矩阵缩减为一维向量。rtype(操作)有4个: cv::REDUCE_SUM; cv::REDUCE_AVG; cv::REDUCE_MAX; cv::REDUCE_MIN; |
| cv::repeat() 有两个重载函数 | 本函数是将src的内容复制到dst中,根据需要重复多次填充dst。参数nx和ny表示重复复制多少次,比如如果nx=1,ny=2,那么src将会在x方向上复制一次,在y方向上复制两次。dst相对于src可以是任意尺寸的,可能比src大或比src小。 |
| cv::saturate_cast<>() | 转换原始类型(模板函数),饱和转换,防止上溢出或下溢出 |
| void cv::scaleAdd(cv::InputArray src1, double scale, cv::InputArray src2, cv::OutputArray dst ); | 逐元素计算两个矩阵的和并且第一个矩阵可以选择缩放,计算公式:dst = scale*src1 + src2; |
| void cv::setIdentity( cv::InputOutputArray dst, const cv::Scalar& value = cv::Scalar(1.0) ); | 将矩阵中对角线上的元素设为1(或者给定数值),其他置0 |
| bool cv::solve(cv::InputArray src1, cv::InputArray src2, cv::OutputArray dst, int method = cv::DECOMP_LU ); | 求出线性方程的解, 解决一个或多个线性系统或最小二乘问题。 |
| int cv::solveCubic(cv::InputArray coeffs, cv::OutputArray roots ); | 求解多项式的实根。给定由三个或四个元素向量系数表示的三次多项式,cv::solveCubic将计算该多项式的实根,如果coeffs有四个元素,则计算以下多项式的根:
c
o
e
f
f
s
[
0
]
x
3
+
c
o
e
f
f
s
[
1
]
x
2
+
c
o
e
f
f
s
[
2
]
x
+
c
o
e
f
f
s
[
3
]
=
0
coeffs[0]x^3 + coeffs[1]x^2+coeffs[2]x+coeffs[3]=0
coeffs[0]x3+coeffs[1]x2+coeffs[2]x+coeffs[3]=0;如果coeffs只有三个元素,则计算以下多项式的根:
x
3
+
c
o
e
f
f
s
[
0
]
x
2
+
c
o
e
f
f
s
[
1
]
x
+
c
o
e
f
f
s
[
2
]
=
0
x^3+coeffs[0]x^2+coeffs[1]x+coeffs[2]=0
x3+coeffs[0]x2+coeffs[1]x+coeffs[2]=0;结果会存储在矩阵roots中,它将具有一个或三个元素,具体取决于多项式具有多少个实根。 需包含头文件:#include <opencv2/core.hpp> |
| double cv::solvePoly( InputArray coeffs, OutputArray roots, int maxIters = 300 ) | 找到多项式方程的实根和复根。方程如下: c o e f f s [ n ] x n + c o e f f s [ n − 1 ] x n − 1 + . . . + c o e f f s [ 1 ] x + c o e f f s [ 0 ] = 0 coeffs[n]x^n+coeffs[n−1]x^{n−1}+...+coeffs[1]x+coeffs[0]=0 coeffs[n]xn+coeffs[n−1]xn−1+...+coeffs[1]x+coeffs[0]=0 |
| cvRound(), cvFloor(), cvCeil() | 函数cvRound,cvFloor,cvCeil 都是用一种舍入的方法将输入浮点数转换成整数 |
| void cv::sort ( InputArray src, OutputArray dst, int flags ) | 仅适用于单通道二维矩阵。参数flags可取的值有: cv::SORT_EVERY_ROW //对每一行排序 cv::SORT_EVERY_COLUMN //对每一列排序 cv::SORT_ASCENDING //升序 cv::SORT_DESCENDING // 降序 |
| void cv::sortIdx(InputArray src, OutputArray dst, int flags) | 分别对每行或每列进行排序,结果是与原矩阵大小相同但包含排序元素整数索引的新矩阵dst。仅适用于单通道二维矩阵。 |
| cv::sortIdx()与cv::sort() | cv::sort 负责返回排序后的矩阵–>from官网,cv::sortIdx 负责返回对应原矩阵的索引。 |
| void cv::split(const cv::Mat& mtx, vector& mv ); | 将一个多通道矩阵分割成多个单通道矩阵 |
| cv::merge() | 将多个单通道矩阵合并成一个多通道矩阵 |
| void cv::sqrt(InputArray src, OutputArray dst) | 计算矩阵中每个元素的平方根 |
| void cv::subtract(InputArray src1, InputArray src2, OutputArray dst, InputArray mask=noArray(), int dtype=-1) | 实现两个矩阵逐元素相减 |
| cv::Scalar cv::sum(InputArray src) | 计算矩阵src各个通道的所有像素的总和,最多四个通道。 |
| cv::theRNG() | 返回默认随机数生成器。函数cy:theRNG返回默认随机数生成器。每一个线程有一个单独的随机数生成器,所以可以在多线程环境中安全使用该函数。如果只需要使用这个生成器获得一个随机数或初始化一个数组,可以使用randu或randn代替。但是如果想在一个循环中产生很多随机数,使用这个函数检索生成器,然后使用RNG::operator_Tp(),这样速度要快得多。 |
| cv::RNG | 随机数发生器 。用RNG产生随机数 |
| cv::Scalar cv::trace(InputArray mtx) | 求取矩阵的迹,返回一个标量 |
| void cv::transform(InputArray src, OutputArray dst,InputArray m ) | 执行每个数组元素的矩阵变换,并将变换结果储存在dst中,该函数可用于N维点的几何变换、任意线性颜色空间变换(如各种RGB到YUV变换)、变换图像通道等。 |
| void cv::transpose(InputArray src, OutputArray dst) | 将src转置的结果赋给dst,注意:在复矩阵中不做复共轭。如有必要,应单独进行。 |
| 基本的矩阵和图像算子 | 此处结束 |
| cvtColor()与applyColorMap()的区别 | |
cv::applyColorMap(InputArray src, OutputArray dst, int colormap) | 用于实现图像的各种色系转换,得到伪彩色图。如何自己定义一个颜色映射。 |
| cv::cvtColor() | 用于将图像从一个颜色空间转换到另一个颜色空间的转换(目前常见的颜色空间均支持),并且在转换的过程中能够保证数据的类型不变,即转换后的图像的数据类型和位深与源图像一致。 |
| cv::perspectiveTransform() | void perspectiveTransform(InputArray src, OutputArray dst, InputArray mat) 透视变换一系列点,用于稀疏透视变换 。矩阵mat可以是3×3或4×4矩阵,如果是3×3,则投影从二维到二维;如果是4×4,则投影从三维到三维。 |
| cv::getPerspectiveTransform() | 计算出透视变换矩阵M(单应矩阵H) |
| cv::warpPerspective() | 透视变换得到鸟瞰图 |
| cv::setMouseCallback() | 回调函数中鼠标响应, 首先明确一点,这个函数在程序中始终运行,任何时候当你的鼠标有动作的时候,该函数被调用。 |
| void cv::initUndistortRectifyMap() | Computes the undistortion and rectification transformation map. [ from官网 ] |
| void cv::remap ( InputArray src, OutputArray dst, InputArray map1, InputArray map2, int interpolation, int borderMode = BORDER_CONSTANT, const Scalar & borderValue = Scalar() ) | Applies a generic geometrical transformation to an image,就是把输入图像中各个像素按照一定的规则映射到另外一张图像的对应位置上去,形成一张新的图像。 |
| cv::PCA::PCA() && 原理 | (1) cv::PCA::PCA ()默认构造; (2)cv::PCA ::PCA(InputArray data, InputArray mean, int flags, int maxComponents=0); (3)cv::PCA ::PCA(InputArray data, InputArray mean, int flags, double retainedVariance) |
| cv::randu | |
| cv::randn | |
| void setMouseCallback(const String& winname, MouseCallback onMouse, void* userdata = 0) | 设置鼠标事件回调, @param winname 需要设置回调的窗口名称 @param onMouse 回调函数typedef void (MouseCallback)(int event, int x, int y, int flags, void userdata); @param userdata 用户自定义数据,作为回调函数的第5个参数 |
| double cv::calibrateCamera () | 单目相机,根据校准模式的几个视图(也就是相机拍的几张不同的图片),求解摄像机的内在参数和外在参数。 返回值是 均方根(RMS)重投影误差,正确校准时,应介于0.1~1.0像素之间。 |
| void cv::undistortImage | |
| cv::threshold() 直接阈值化 | double cv::threshold( cv::InputArray src, // 输入图像 cv::OutputArray dst, // 输出图像 double thresh, // 阈值 double maxValue, // 向上最大值 int thresholdType // 阈值化操作的类型 ); |
| void adaptiveThreshold( InputArray src, OutputArray dst, double maxValue, int adaptiveMethod,int thresholdType, int blockSize, double C ); | 参数解释: src, // 表示需要进行二值化的图像;需要注意的是,该输入必须是8-bit单通道的图像; dst, // 输出图像的二值图像 double maxValue, //是一个非零值,用于对哪些满足条件的阈值进行赋值 int adaptiveMethod, // 自适应方法,平均或高斯 int thresholdType // 二值化类型,有两种:THRESH_BINARY 与 THRESH_BINARY_INV int blockSize, // 块大小,邻域范围,必须为奇数 double C // 可以为正数, 零或者负数;用于在计算过程中容忍程度 |
| cv::goodFeaturesToTrack() | 角点检测 |
| cv::cornerSubPix( InputArray image, InputOutputArray corners, Size winSize, Size zeroZone, TermCriteria criteria ) | 亚像素检测 InputArray image为灰度图像 |
| bool cv::findCirclesGrid() | 检测圆形的具体实现步骤 |
| cv::findChessboardCorners() | 棋盘格角点检测的函数,仅提供角点的近似位置 返回值为bool类型。CALIB_CB_FAST_CHECK在图像上运行一个快速检查,寻找棋盘角,如果没有找到,则快速调用。opencv棋盘格角点检测原理总结–函数内部算法逻辑。 所需头文件:#include <opencv2/opencv.hpp> |
| cv::find4QuadCornerSubpix ( InputArray img, InputOutputArray corners, Size region_size) | 找到棋盘角的亚像素精确位置。作用同cornerSubPix()函数 返回值为bool类型 所需头文件:#include <opencv2/opencv.hpp> |
| 基于生长的棋盘格角点检测方法–(1)原理介绍 基于生长的棋盘格角点检测方法–(2)代码详解(上) Opencv之—棋盘格角点检测算法源码解析 | |
| cv::drawChessboardCorners() | 用于绘制棋盘格角点的函数 所需头文件:#include <opencv2/opencv.hpp> |
| bool cv::solvePnP ( InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, OutputArray rvec, OutputArray tvec, bool useExtrinsicGuess = false, int flags = cv::ITERATIVE ); | 从3D-2D点对应关系中找到一个对象的姿态。如果场景的三维结构已知,利用多个控制点在三维场景中的坐标及其在图像中的透视投影坐标即可求解出摄像机坐标系与表示三维场景结构的世界坐标系之间的绝对位姿关系,该类求解方法统称为 N点透视求解(Perspective-N-Point,PNP问题) 。 使用cv::Rodrigues()函数主要用于将cv:: solvePnP() {from官网}和cv::calibrateCamera()的输出从Rodrigues格式的1x3或3x1向量转化为旋转矩阵,反之亦然。 |
| cv::solvePnP 函数中参数flags( 三个flags区别(非官方) ): (1) cv::ITERATIVE( flags=0 ) : (2)cv::P3P( flags=2 ): (3)cv::EPNP( flags=1 ): | (1)默认值,它通过迭代求出重投影误差最小的解作为问题的最优解(似乎只能使用共面的四个特征点求位姿)。 (2)是使用非常经典的Gao的P3P问题求解算法。(3)使用文章《EPnP: Efficient Perspective-n-Point Camera Pose Estimation》中的方法求解。 |
| bool cv::solvePnPRansac() | cv::solvePnP的一个缺点是对异常值不够鲁棒(针对棋盘格相机标定影响不大)。 |
| cv::findHomography(InputArray srcPoints, InputArray dstPoints, int method=0, double ransacReprojThreshold=3, OutputArray mask=noArray(), const int maxIters=2000, const double confidence=0.995) | Finds a perspective transformation between two planes,得到H单应矩阵。单应矩阵的推导与理解(R, t, {n,d}) |
| cv::decomposeHomographyMat (InputArray H, InputArray K, OutputArrayOfArrays rotations, OutputArrayOfArrays translations, OutputArrayOfArrays normals) | 用法来自CSDN,Decompose a homography matrix to rotation(s), translation(s) and plane normal(s) ,分解单应矩阵H得到旋转向量、平移向量、平面法向量。 |
| cv::filterHomographyDecompByVisibleRefpoints(InputArrayOfArrays rotations, InputArrayOfArrays normals, InputArray beforePoints, InputArray afterPoints, OutputArray possibleSolutions, InputArray pointsMask=noArray()) | 用法来自CSDN,Filters homography decompositions based on additional information,过滤得到我们想要的旋转向量和平移向量。 |
| void cv::Rodrigues ( InputArray src, //输入旋转向量or矩阵 OutputArray dst, //输出旋转矩阵or向量 OutputArray jacobian = noArray() ) | 将旋转矩阵转换为旋转向量,反之亦然(from官网) |
| cv::reprojectImageTo3D() | 该函数将单通道视差图像,通过4X4重投影矩阵Q,得到一副映射图,图像大小与视差图相同,且每个像素具有三个通道,分别存储了该像素位置在相机坐标系下的三维点坐标在x, y, z,三个轴上的值,即每个像素的在相机坐标系下的三维坐标。 |
| cv::cv2eigen() cv::eigen2cv(); | 这两个函数都要输入两个参数,第一个参数为输入的矩阵,第二个参数为输出的矩阵。 所需头文件:#include <Eigen/Dense> #include <opencv2/core/eigen.hpp> #include “opencv2/opencv.hpp” |
| aruco标定板相关标定 | |
| cv::aruco::interpolateCornersCharuco( ) | Interpolate position of ChArUco board corners. 通过marker标记点来线性内插棋盘格角点 |
| cv::aruco::drawDetectedCornersCharuco( ) | |
| cv::getTextSize() | 获取一个文字的宽度和高度 |
| cv::putText() | 在图片上绘制指定文字 |
| void cv::setWindowProperty(const String &winname, int prop_id, double prop_value) | 设置窗口属性(from官网) |
| cv::getWindowProperty(winname, prop_id) | 得到窗口属性(from官网) |
| void cv::namedWindow (const String &winname, int flags=WINDOW_AUTOSIZE) | 命名一个窗口(from官网) WINDOW_NORMAL or WINDOW_AUTOSIZE WINDOW_FREERATIO or WINDOW_KEEPRATIO WINDOW_GUI_NORMAL or WINDOW_GUI_EXPANDED |
| void cv::destroyWindow (const String &winname) | 销毁一个窗口(from官网) |
| void cv::resize( InputArray src, OutputArray dst, Size dsize, double fx = 0, double fy = 0, int interpolation = INTER_LINEAR ); | 尺寸均匀调整。 尺寸调整(from官网) INTER_LANCZOS4: Lanczos滤波器通常用于处理数字图像,因为它具有增加图像感知清晰度的效果。 |
| void cv::pyrDown ( InputArray src, OutputArray dst, const Size & dstsize = Size(), int borderType = BORDER_DEFAULT) | 高斯金字塔用于降采样图像。 |
| void cv::buildPyramid ( InputArray src, OutputArrayOfArrays dst, int maxlevel, int borderType = BORDER_DEFAULT) | 希望构建一系列新图像,每个新图像从前一个图像缩减,该函数创建一个输出图像堆栈。 |
| cv::pyrUp() | 可以用来构建拉普拉斯金字塔。拉普拉斯金字塔是通过源图像减去先缩小再放大的图像的一系列图像构成。拉普拉斯金字塔的第i层由以下关系定义: L i = G i − p y r U p ( G i + 1 ) L_i=G_i - pyrUp(G_{i+1}) Li=Gi−pyrUp(Gi+1) |
| cv::Mat cv::findFundamentalMat() | 计算基本矩阵F(from官网) |
| cv::Mat findEssentialMat() | 计算本征矩阵E(from官网) |
| 基本矩阵、本征矩阵和单应矩阵的讲解 | 基本矩阵F和本征矩阵E没有什么差别,基础矩阵F是在图像像素坐标中操作,而本征矩阵E在物理坐标系(纯几何)中操作 |
| void cv::computeCorrespondEpilines() | 根据一幅图像中的点列,计算其在另一幅图像中对应的极线。 |
| void projectPoints(InputArray objectPoints, InputArray rvec, InputArray tvec, InputArray cameraMatrix, InputArray distCoeffs, OutputArray imagePoints, OutputArray jacobian=noArray(), double aspectRatio=0 ) | from 官网-函数projectPoints()根据所给的3D坐标和已知的几何变换来求解投影后的2D坐标。 通过给定的内参数和外参数计算三维点投影到二维图像平面上的坐标。 重投影误差显示在图像上。 |
| double cv::stereoCalibrate( ) | 标定立体相机(双目相机)(from官网) 。 imagePoints1包含第一个(通常是左侧)摄像机观察到的点。返回值是 均方根(RMS)重投影误差,正确校准时,应介于0.1~1.0像素之间。两个摄像头的焦距f应该保持一致,因为在后续的视差图转换为三维图时的Q矩阵只有 焦距f值。所以必须要求至少焦距相近。而且立体成像的三角测量的前提假设就是 f l f_l fl= f r f_r fr。(调整两个摄像头的焦距相同的方法:离两个相机相同远处放置标定板,分别调节两个相机的焦距,使得两个画面的清晰度相似。) |
| 双目校正函数 cv::stereoRectify() | 鱼眼相机也有类似的函数 |
| 双目标定 块匹配算法 cv::StereoBM | from官网 |
| 双目标定 半全局块匹配算法 cv::StereoSGBM | from官网 |
| cv::circle() | 画圆(空心圆、实心圆) |
| cv::waitKey(delay = 0) | 1、delay≤0:一直等待按键; 2、delay取正整数:等待按键的时间(ms)。 该函数的返回值: 等待期间有按键:返回按键的ASCII码(比如:Esc的ASCII码为27); 等待期间没有按键:返回值为 -1; 用法:char c = (char)waitKey(); if( c == 27 逻辑或 c== ‘q’ 逻辑或 c == ‘Q’ ) break; |
| cv::glob() | 作用:读取文件夹中数据,from官网 |
| cv::fitLine() | 在图像处理中,通常会遇到根据给定的点集(比如轮廓)拟合出一条直线的情形。opencv2和opencv3中提供了一个专门用于直线拟合的函数——cv::fitLine() |
| cv::mixChannels() | 作用:将输入数组的指定通道复制到输出数组的指定通道。from官网 |
| 类 cv::CommandLineParser &&& second link | 命令行解析类 |
| cv::getTickCount() | 该函数为opencv中的函数,该函数返回的值为自从某一时刻(比如计算机启动)开始,计算机总共经过的tick的次数,其需要结合getTickFrequency()函数使用,getTickFrequency()返回的是CPU在一秒钟内会发出的tick的次数,总体来说,该函数的精度较高,能够精确到1ms左右。 举例: double t = (double)getTickCount(); t = ((double)getTickCount()-t)/getTickFrequency(); //获得时间,单位是秒 |
| cv::FileStorage 类 | from官方连接。FileStorage类将各种OpenCV数据结构的数据存储为XML 或 YAML格式并对xml,yml等文本文件的读写。 类中成员函数: wtrite() read() writeComment() 等等 |
| cv::FileStorage::writeComment ( const String & comment, bool append = false ) | 函数作用:写注释。该函数将注释写入文件存储。读取存储时,将跳过注释。参数解释:(1)comment:书面评论,单行或多行;(2)append:如果为true,函数将尝试将注释放在当前行的末尾。否则,如果注释是多行的,或者它不适合在当前行的末尾,则注释将开始一个新行。 |
| cv::FileNode 类 | OpenCV读取XML或YML文件 |
| void cv::hconcat( ) 水平拼接函数 | 对给定矩阵应用水平连接。from-opencv官网 |
| void cv::vconcat( ) 垂直拼接函数 | 对给定矩阵应用垂直连接。from-opencv官网 |
| cv::aruco 类 作用:ArUco Marker Detection | from-opencv官网 |
| void cv::meanStdDev () | 用于计算一个矩阵的均值和标准差。from-opencv官网 |
| cv::drawMarker() | 图像上绘制标记 |
| cv::Mat cv::estimateAffinePartial2D() | Computes an optimal limited affine transformation with 4 degrees of freedom between two 2D point sets. from-opencv官网 所需头文件: #include <opencv2/calib3d.hpp> |
| cv::Mat cv::estimateAffine2D() | Computes an optimal affine transformation between two 2D point sets. from-opencv官网 表示的是六自由度的仿射变换 所需头文件: #include <opencv2/calib3d.hpp> |
| class cv::detail::MultiBandBlender | 多波段图像融合 from官网 需包含头文件:#include “blenders.hpp” |
| void findContours(InputArray image, OutputArrayOfArrays contours, OutputArray hierarchy, int mode, int method, Point offset = Point() ) | 注意:该函数将白色区域当作前景物体。所以findContours()函数是黑色背景下找白色轮廓。 |
| void cv::drawContours( InputOutputArray binImg, // 输入输出图像 OutputArrayOfArrays contours,// 全部发现的轮廓对象 Int contourIdx// 轮廓索引号,-1 表示绘制所有轮廓 const Scalar & color,// 绘制时候颜色 int thickness,// 绘制线宽,-1 表示填充轮廓内部或CV_FILLED int lineType,// 线的类型LINE_8 InputArray hierarchy,// 拓扑结构图 int maxlevel,// 最大层数, 0只绘制当前的,1 表示绘制绘制当前及其内嵌的轮廓 Point offset = Point()// 轮廓位移,可选) | |
| double contourArea( InputArray contour, bool oriented = false ); | InputArray类型的contour,输入的向量,二维点(轮廓顶点),可以为std::vector或Mat类型。 |
| cv::Rect exRect = boundingRect(InputArray points) | 函数作用:计算轮廓的垂直边界最小矩形,矩形是与图像上下边界平行的;(也称之为最小正外接矩形).points:输入信息,可以为包含点的容器(vector)或是Mat; |
| RotatedRect boundingBox = minAreaRect(InputArray points) | 函数作用:主要求得包含点集最小面积的矩形,,这个矩形是可以有偏转角度的,可以与图像的边界不平行。(也称之为最小斜外接矩形).points:输入信息,可以为包含点的容器(vector)或是Mat; |
| cv::VideoCapture 类 | 视频的获取操作。VideoCapture 类基础知识 – – OpenCV中使用类VideoCapture加载视频和打开摄像头 VideoCaptureProperties-from官网 |
| cv::KeyPoint类 | 它是opencv中关键点检测函数detectAndCompute()返回的关键点的类,包含关键点的位置,方向等属性。from官网 。 具体属性如下: CV_PROP_RW Point2f pt; //位置坐标 CV_PROP_RW float size; //特征点邻域直径 CV_PROP_RW float angle; //特征点的方向,值为[零, 三百六十),负值表示不使用 CV_PROP_RW float response; //最重要关键点的响应 CV_PROP_RW int octave; //选择最重要关键点的响应 CV_PROP_RW int class_id; //用于聚类的id |
| cv::DMatch类 | 它是opencv中匹配函数(knnMatch)返回的用于匹配关键点描述符的类。from官网。 具体属性如下: CV_PROP_RW int queryIdx; //查询图像中描述符的索引 CV_PROP_RW int trainIdx; //目标图像中描述符的索引。 CV_PROP_RW int imgIdx; //目标图像的索引 CV_PROP_RW float distance;//描述符之间的距离。越小越好 |
| cv::triangulatePoints() | 该函数通过使用立体相机对三维点的观测来重建三维点(在齐次坐标中)[三角化]。 from官网。 请记住,为了使此函数工作,所有输入数据都应该是浮点类型。如果使用来自stereoRectify的投影矩阵,则返回的点在第一个相机的校正坐标系中表示。 |
| cv::sfm::triangulatePoints() | 通过三角测量重建一组点。函数内部使用DLT方法。 from官网。 需引入头文件:#include <opencv2/sfm/triangulation.hpp> |
| cv::connectedComponents() | 不带统计信息的API |
| cv::connectedComponentsWithStats() | 带有统计信息的API,计算布尔图像中标记图像的连接组件,并为每个标签生成统计输出 from官网 int cv::connectedComponentsWithStats ( cv::InputArrayn image, // input 8-bit single-channel (binary) cv::OutputArray labels, // output label map cv::OutputArray stats, // Nx5 matrix (CV_32S) of statistics: // [x0, y0, width0, height0, area0; // … ; x(N-1), y(N-1), width(N-1), // height(N-1), area(N-1)] cv::OutputArray centroids, // Nx2 CV_64F matrix of centroids: // [ cx0, cy0; … ; cx(N-1), cy(N-1)] int connectivity = 8, // 4- or 8-connected components int ltype = CV_32S // Output label type (CV_32S or CV_16U)); |
| double cv::kmeans(InputArray data, int K, InputOutputArray bestLabels, TermCriteria criteria, int attempts, int flags, OutputArray centers=noArray() ) KMeans 算法from CSDN 聚类分析的评价指标(性能度量) 聚类的评价指标 | 该函数可用于图像分割。该函数为kmeans聚类算法实现函数。参数data表示需要被聚类的原始数据集合,一行表示一个数据样本,每一个样本的每一列都是一个属性;参数k表示需要被聚类的个数;参数bestLabels表示每一个样本的类的标签,是一个整数,从0开始的索引整数;参数criteria表示的是算法迭代终止条件;参数attempts表示运行kmeans的次数,取结果最好的那次聚类为最终的聚类,要配合下一个参数flages来使用;参数flags表示的是聚类初始化的条件。其取值有3种情况,如果为KMEANS_RANDOM_CENTERS,则表示为随机选取初始化中心点,如果为KMEANS_PP_CENTERS则表示使用某一种算法来确定初始聚类的点;如果为KMEANS_USE_INITIAL_LABELS,则表示使用用户自定义的初始点,但是如果此时的attempts大于1,则后面的聚类初始点依旧使用随机的方式;参数centers表示的是聚类后的中心点存放矩阵。该函数返回的是聚类结果的紧凑性. |
| void Sobel(src,dst,dDepth,int dx,int dy,kSize=3,scale=1,delta=0,borderType=BORDER_DEFAULT) | from官网 需头文件:#include <opencv2/imgproc.hpp> |
| cv::convertScaleAbs() | |
| void grabCut( InputArray img, InputOutputArray mask, Rect rect, InputOutputArray bgdModel, InputOutputArray fgdModel, int iterCount, int mode = GC_EVAL ); | 图像分割函数,Grabcut 算法主要运用于计算机视觉中的前背景分割,立体视觉和抠图等。 |
| void filter2D( InputArray src, OutputArray dst, int ddepth, InputArray kernel, Point anchor=Point(-1,-1), double delta=0, int borderType=BORDER_DEFAULT); | 图像处理中常用的卷积核(kernel) |
| 滤波(去噪声)函数 | 此处修改 |
| 非线性 void medianBlur(InputArray src, OutputArray dst, int ksize) | 基本思想是用像素点邻域灰度值的中值来代替该像素点的灰度值,主要是利用中值不受分布序列极大值和极小值影响的特点,让周围的像素值接近真实的值从而消除孤立的噪声点。对于图像处理来说,非常适用去除于在不要求图像细节下的椒盐噪声以及脉冲噪声,能够克服线性滤波器带来的图像细节模糊等弊端,能够有效保护图像边缘信息,是非常经典的平滑噪声处理方法。 |
| 非线性 void bilateralFilter(InputArray src, OutputArray dst, int diameter, double sigmaColor, douboe sigmaSpace, int borderType=BORDER_DEFAULT) | bilateral filter双边滤波器的通俗理解 。双边滤波算法本质是基于高斯滤波,目的是解决高斯滤波造成的边缘模糊。双边滤波(Bilateral Filter)详解 |
| 非线性 void boxFilter(InputArray src, OutputArray dst, int ddepth, Size ksize, Point anchor=Point(-1, -1), boolnormalize=true, int borderType=BORDER_DEPAULT); | boxFilter(方框滤波),其最主要的作用就是来模糊一张图片(可以部分的消除掉图像出尖锐的边缘点)。 |
| 线性 void GaussianBlur(InputArray src, OutputArray dst, Size ksize, double sigmaX, double sigmaY=0, int borderType=BORDER_DEFAULT ) | 高斯滤波是一种线性平滑滤波,对于除去高斯噪声有很好的效果。 通俗的讲, 高斯滤波是对整幅图像进行加权平均的过程,每一个像素点的值都由其本身和邻域内的其他像素值经过加权平均后得到。 高斯滤波的具体操作是:用一个模板(或称卷积、掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值。 数值图像处理中,高斯滤波主要可以使用两种方法实现。一种是离散化窗口滑窗卷积,另一种方法是通过傅里叶变化。 |
| 线性 void blur( InputArray src, OutputArray dst, Size ksize, Point anchor = Point(-1,-1), int borderType = BORDER_DEFAULT ); | 均值滤波,均值滤波是典型的线性滤波算法,它是指在图像上对目标像素给一个模板,该模板包括了其周围的临近像素(以目标像素为中心的周围8个像素,构成一个滤波模板,即包括目标像素本身),再用模板中的全体像素的平均值来代替原来像素值。 |
| void filter2D( InputArray src, OutputArray dst, int ddepth, InputArray kernel, Point anchor = Point(-1,-1), double delta = 0, int borderType = BORDER_DEFAULT ); | 可输入自定义的kernel。 |
| void copyMakeBorder(InputArray src, OutputArray dst, int top, int bottom, int left, int right, int borderType, const Scalar& value = Scalar() ); | 扩充图像边界,为图像创建边框的函数。 int类型的top,表示向上扩展多少像素。 int类型的bottom,表示向下扩展多少像素。 int类型的left,表示向左扩展多少像素。 int类型的right,表示向右扩展多少像素。 |
| void cv::convertPointsToHomogeneous ( InputArray src, OutputArray dst) | 将点坐标从欧几里得空间转换到齐次空间。src: Input vector of N-dimensional points. dst: Output vector of N+1-dimensional points. |
| void cv::convertPointsFromHomogeneous ( InputArray src, OutputArray dst) | 将点坐标从齐次空间转换到欧几里得空间。 src: Input vector of N-dimensional points. dst: Output vector of N-1-dimensional points. 需引入头文件:#include <opencv2/calib3d.hpp> |
| double cv::pointPolygonTest(cv::InputArray contour, cv::Point2f pt, bool measureDist) | 作用:判断当前位置的像素点在多边形轮廓的相对位置,即内部、边缘和外部。measureDist = flase时,内部返回为+1,边缘返回为0,外部返回为-1;measureDist = true时,返回的是有符号的距离; |
| VideoWriter_fourcc()常见的编码参数 | 参数列表 |
|---|---|
| cv::VideoWriter 类 | from官方 |
| cv2.VideoWriter_fourcc(‘M’, ‘P’, ‘4’, ‘V’) | MPEG-4编码 .mp4 可指定结果视频的大小 |
| cv2.VideoWriter_fourcc(‘X’,‘2’,‘6’,‘4’) | MPEG-4编码 .mp4 可指定结果视频的大小 |
| cv2.VideoWriter_fourcc(‘I’, ‘4’, ‘2’, ‘0’) | 该参数是YUV编码类型,文件名后缀为.avi |
| cv2.VideoWriter_fourcc(‘P’, ‘I’, ‘M’, ‘I’) | 该参数是MPEG-1编码类型,文件名后缀为.avi |
| cv2.VideoWriter_fourcc(‘X’, ‘V’, ‘I’, ‘D’) | 该参数是MPEG-4编码类型,文件名后缀为.avi,可指定结果 |
| cv2.VideoWriter_fourcc(‘T’, ‘H’, ‘E’, ‘O’) | 该参数是Ogg Vorbis,文件名后缀为.ogv |
| cv2.VideoWriter_fourcc(‘F’, ‘L’, ‘V’, ‘1’) | 该参数是Flash视频,文件名后缀为.flv |
| cv2.VideoWriter_fourcc(‘M’, ‘J’, ‘P’, ‘G’) | 文件名后缀为.avi |
2、cv::fisheye相关函数列表
鱼眼镜头是一种极端的广角镜头,通常焦距小于等于16mm并且视角接近或等于180°(在工程上视角超过140°的镜头即统称为鱼眼镜头)。
鱼眼镜头常用的投影方式包括等距投影、等积投影、体视投影、正交投影等;
KannalaBrandt模型.对应实现OpenCV::Fisheye
| (等距投影模型)cv::fisheye相关函数from官网 | 描述 |
|---|---|
| cv::getOptimalNewCameraMatrix() + cv::fisheye::initUndistortRectifyMap() + cv::remap() | 需包含头文件:#include <opencv2/calib3d.hpp> 结果等同于下面的函数(此搭配效果较优) |
| void cv::fisheye::undistortImage ( InputArray distorted, OutputArray undistorted, InputArray K, InputArray D, InputArray Knew=cv::noArray(), const Size &new_size=Size() ) | Transforms an image to compensate for fisheye lens distortion,变换图像以补偿鱼眼镜头的畸变 |
| 参数: distorted undistorted | image with fisheye lens distortion。 Output image with compensated fisheye lens distortion |
| 参数: K D | K:相机矩阵 D: Input vector of distortion coefficients (k1, k2, k3, k4) 共4个参数,由于鱼眼相机的径向畸变非常严重,所以鱼眼相机主要的是 考虑径向畸变,而忽略其余类型的畸变。 |
| 参数: Knew = cv::noArray() 。 new_size = Size() | Camera matrix of the distorted image. By default, it is the identity matrix but you may additionally scale and shift the result by using a different matrix,扭曲图像的相机矩阵。默认情况下,它是单位矩阵,但您可以通过使用不同的矩阵来缩放和移动结果。 矩阵的尺寸 |
| double cv::fisheye::calibrate (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints, const Size &image_size, InputOutputArray K, InputOutputArray D, OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs, int flags=0, TermCriteria criteria=TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 100, DBL_EPSILON)) | Performs camera calibration(执行相机标定)from官网 CALIB_CHECK_COND: 是否检测条件; 检测最后的雅克比公式中B矩阵是不是满秩矩阵,在鱼眼标定的时候,一般设置为True,可以帮我们筛选掉不好的标定图片; CALIB_FIX_K1,K2,K3,K4:是否固定某个畸变参数; 如果选择CALIB_FIX_K4, 对应的畸变参数为:[K1, K2,K3,0], 同理,如果CALIB_FIX_K3, 则对应的畸变参数为[K1,K2,0,0] |
| cv::fisheye::distortPoints (InputArray undistorted, OutputArray distorted, InputArray K, InputArray D, double alpha=0) | Distorts 2D points using fisheye model,使用鱼眼模型扭曲2D点 |
| double cv::fisheye::stereoCalibrate (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints1, InputArrayOfArrays imagePoints2, InputOutputArray K1, InputOutputArray D1, InputOutputArray K2, InputOutputArray D2, Size imageSize, OutputArray R, OutputArray T, int flags=fisheye::CALIB_FIX_INTRINSIC, TermCriteria criteria=TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 100, DBL_EPSILON)) | Performs stereo calibration,执行立体相机标定 |
| void cv::fisheye::stereoRectify (InputArray K1, InputArray D1, InputArray K2, InputArray D2, const Size &imageSize, InputArray R, InputArray tvec, OutputArray R1, OutputArray R2, OutputArray P1, OutputArray P2, OutputArray Q, int flags, const Size &newImageSize=Size(), double balance=0.0, double fov_scale=1.0) | Stereo rectification for fisheye camera model,鱼眼相机模型的立体校正 |
3、cv::omnidir相关函数列表
CMei模型. 对应实现OpenCV::Omnidir
| double cv::omnidir::calibrate (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints, Size size, InputOutputArray K, InputOutputArray xi, InputOutputArray D, OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs, int flags, TermCriteria criteria, OutputArray idx=noArray()) | |
| void cv::omnidir::initUndistortRectifyMap (InputArray K, InputArray D, InputArray xi, InputArray R, InputArray P, const cv::Size &size, int m1type, OutputArray map1, OutputArray map2, int flags) | |
| void cv::omnidir::projectPoints (InputArray objectPoints, OutputArray imagePoints, InputArray rvec, InputArray tvec, InputArray K, double xi, InputArray D, OutputArray jacobian=noArray()) | |
六、OpenCV与其他工具联合开发
1、ROS 图像与 OpenCV图像 之间的转换
头文件:cv_bridge/cv_bridge.h,这个头文件主要是我们将使用这个进行图像格式的转换,把opencv的Mat转化ROS的消息格式,或者把ROS格式的消息转化为opencv的Mat。
请点击-> Ros图像与Opencv图像的相互转换cv_bridge(C++) >--------< 附加:ros官网
2、OpenCV与Qt
请点击-> OpenCV使用QT GUI显示
请点击-> Qt+OpenCV联合开发(十九)–鼠标操作与响应
请点击-> OpenCV实现SFM(三):多目三维重建
七、 Eigen相关
1、各个模块介绍
| 模块名称 | 头文件 | 介绍说明 |
|---|---|---|
| Core | #include <Eigen/Core> | Matrix and Array classes, basic linear algebra (including triangular and selfadjoint products), array manipulation |
| Geometry | #include <Eigen/Geometry> | Transform, Translation, Scaling, Rotation2D and 3D rotations (Quaternion, AngleAxis) |
| 矩阵分解方法: LU | #include <Eigen/LU> | Inverse, determinant, LU decompositions with solver (FullPivLU, PartialPivLU) |
| 矩阵分解方法: Cholesky | #include <Eigen/Cholesky> | LLT and LDLT Cholesky factorization with solver |
| Householder | #include <Eigen/Householder> | Householder transformations; this module is used by several linear algebra modules |
| 矩阵分解方法: SVD | #include <Eigen/SVD> | SVD decompositions with least-squares solver (JacobiSVD, BDCSVD) |
| 矩阵分解方法: QR | #include <Eigen/QR> | QR decomposition with solver (HouseholderQR, ColPivHouseholderQR, FullPivHouseholderQR) |
| Eigenvalues | #include <Eigen/Eigenvalues> | Eigenvalue, eigenvector decompositions (EigenSolver, SelfAdjointEigenSolver, ComplexEigenSolver) |
| Sparse | #include <Eigen/Sparse> | Sparse matrix storage and related basic linear algebra (SparseMatrix, SparseVector) |
| (see Quick reference guide for sparse matrices for details on sparse modules) | ||
| #include <Eigen/Dense> | Includes Core, Geometry, LU, Cholesky, SVD, QR, and Eigenvalues header files | |
| #include <Eigen/Eigen> | Includes Dense and Sparse header files (the whole Eigen library) |
请点击-> Eigen: C++开源矩阵计算工具——Eigen的简单用法
请点击-> C++学习笔记——Eigen模块(用于矩阵运算)
请点击-> Eigen介绍及简单使用
请点击-> Eigen等距变换(Isometry,Isometry3f,Isometry3d)常用函数翻译说明
请点击-> vector<Isometry3d> 和vector<Isometry3d, Eigen::aligned_allocator<Isometry3d>>有什么区别
2、Eigen函数列表
| 函数名称 | 函数说明 |
|---|---|
| Eigen::AngleAxis() | Represents a 3D rotation as a rotation angle around an arbitrary 3D axis. 将三维旋转表示为围绕任意三维轴的旋转角度。from官网 所需头文件:#include <Eigen/Geometry> |
| Eigen::AngleAxisd() | 旋转向量(3X1) |
| Eigen::JacobiSVD() | from官网 |
3、仿射变换矩阵
Eigen库中,仿射变换矩阵的大致用法为:
创建Eigen::Affine3f 对象a。
创建类型为Eigen::Translation3f 对象b,用来存储平移向量;
创建类型为Eigen::Quaternionf 四元数对象c,用来存储旋转变换;
最后通过以下方式生成最终Affine3f变换矩阵: a=bc.toRotationMatrix();
一个向量通过仿射变换时的方法是result_vector=test_affinetest_vector;
4、矩阵库的矩阵分解方法
Eigen主要提供了以下几种分解方法:Cholesky分解(包括LLT、LDLT),QR分解,SVD分解,LU分解(包括ParttialPivLU、FullPivLU) 这四种分解法。
方法的选择主要跟系数矩阵相关:
1、如果系数矩阵是非对称、可逆的:则最适合的分解求解方法是partialPivLu;
2、如果系数矩阵是对称、正定的(正定方程组):则最适合的分解方法是 llt 或ldlt;
3、求解通用的欠定或超定线性方程组的最小二乘解:svd,可以认为BDC是Jacobi的扩展版本,是兼容它的,对于小矩阵 (<16),最好直接使用JacobiSVD 。对于较大的,强烈建议使用BSDCSVD,它可以快几个数量级;
4、如果矩阵可逆,选用QR分解也比较好,一般使用ColPivHouseholderQR(列旋转,稳定性比较高),速度也介于三个中间;
八、相关理论知识(疑惑点)
请点击–> pitch yaw roll是什么
请点击–> opencv 的CV_Assert()函数
/*函数功能:求两条直线交点*/
/*输入:两条Vec4i类型直线*/
/*返回:Point2f类型的点*/
Point2f getCrossPoint(Vec4i LineA, Vec4i LineB)
{
double ka, kb;
ka = (double)(LineA[3] - LineA[1]) / (double)(LineA[2] - LineA[0]); //求出LineA斜率
kb = (double)(LineB[3] - LineB[1]) / (double)(LineB[2] - LineB[0]); //求出LineB斜率
Point2f crossPoint;
crossPoint.x = (ka*LineA[0] - LineA[1] - kb*LineB[0] + LineB[1]) / (ka - kb);
crossPoint.y = (ka*kb*(LineA[0] - LineB[0]) + ka*LineB[1] - kb*LineA[1]) / (ka - kb);
return crossPoint;
}
九、传感器相关知识
视场角与焦距的关系:一般情况下,视场角越大,焦距就越短,景深就越大(景深和视场角都与焦距成反比)。
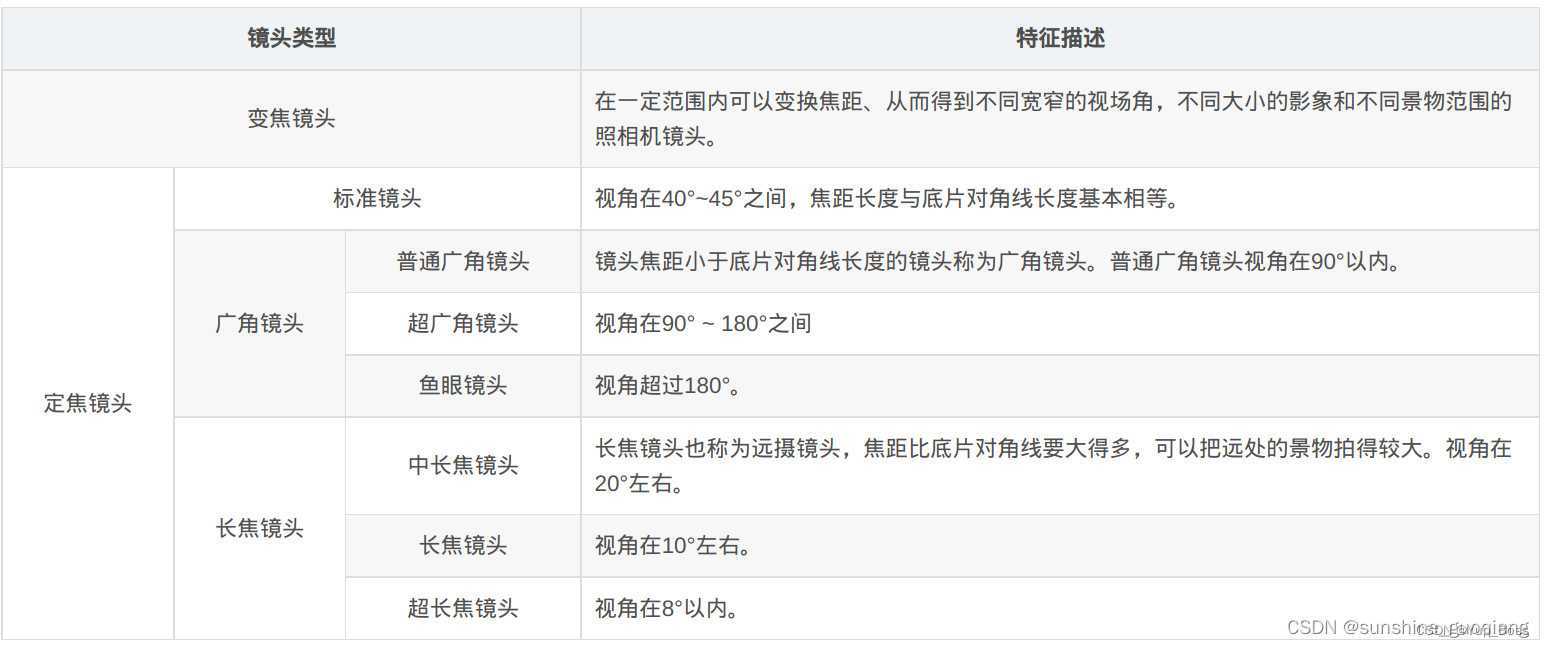
视场角与焦距的关系如下:像高 = EFL*tan (半FOV);EFL为焦距;FOV为视场角。
| 镜头模组类型 | 焦距/mm | 视场角/度—>分为水平视场角 (HFOV) 和垂直视场角 (VFOV) |
|---|---|---|
| 标准镜头 | 视角45度左右 | |
| 远摄镜头 | 视角40度以内 | |
| 远心镜头(Telecentric Lens) | 是一种特殊的光学镜头,其设计特点在于入射光瞳位于无穷远处,只接收平行于光轴的主射线。这种设计使得远心镜头具有一系列独特的性能优势,特别是在机器视觉和精密测量领域。首先,远心镜头的最显著特点是其图像比例在整个景深范围内保持一致。这意味着无论物体距离镜头的远近如何变化,所成的图像大小都保持恒定,从而避免了因距离变化而引起的透视误差。这一特性使得远心镜头在需要高精度的测量和检测应用中具有显著优势。其次,远心镜头还具有高畸变优化的特点。畸变是光学镜头中常见的问题,它会导致图像失真,影响测量的准确性。而远心镜头通过优化设计,可以显著减少畸变,使得图像更加真实、准确。 | |
| 超广角镜头-鱼眼 | ||
请点击–> 浅析相机FOV
请点击–> 摄像头(相机)焦距和视场角
请点击–> 工业相机与镜头选型方法(含实例)
请点击–> 模型 16个相机参数(内参、外参、畸变参数)
请点击–> 相机基础知识讲解:CMOS和CCD
请点击–> CCD CMOS传感器基本工作原理
请点击–> 中继镜(增距镜)详解
| 摄像头相关名词 | 名词解释 |
|---|---|
| 摄像头硬件结构 | 包括光学镜头(其中包含光学镜片、滤光片、保护膜等)、图像传感器、图像信号处理器ISP、串行器、连接器等器件 |
| 光学镜头 | 负责聚焦光线,将视野中的物体投射到成像介质表面,根据成像效果的要求不同,可能要求多层光学镜片。 光学镜头参数详解(EFL、TTL、BFL、FFL、FBL/FFL、FOV、F/NO、RI、MTF、TV-Line、Flare/Ghost) |
| 图像传感器 | 图像传感器可以利用光电器件的光电转换功能将感光面上的光像转换为与光像成相应比例关系的电信号。分为CMOS和CCD两种类型。CCD元件的色彩饱和度好,图像较为锐利,质感更加真实,特别是在较低感光度下表现较好。但是CCD元件制造成本较高,且在高感光度下表现不太好,功耗较大。CMOS的色彩饱和度和质感略差于CCD,但通过对芯片的处理可以弥补这些差距,而且CMOS具备硬件降噪机制,在高感光度下的表现好于CCD,它的读取速度更快。 |
| CMOS(complementary metal-oxide-semiconductor:互补金属氧化物半导体) | CMOS芯片由微透镜层、滤色片层、线路层、感光元件层、基板层组成。由于光线进入各个单像素的角度不一样,因此在每个单像素上表面增加了一个微透镜修正光线角度,使光线垂直进入感光元件表面。这就是芯片CRA的概念,需要与镜头的CRA保持在一点的偏差范围内。CRA(chief ray angle)主光线角度,通常来讲,sensor的效能与sensor本身的灵敏度和光线入射的角度有关。而光线入射到sensor pixel的角度由lens的CRA和sensor的micro lens开口布局共同决定的。 |
| ISP 图像信号处理器 | 主要使用硬件结构完成图像传感器输入的图像视频源 RAW 格式数据的前处理,可转换为 YCbCr 等格式。还可以完成图像缩放、自动曝光、自动白平衡、自动聚焦等多种工作。 |
| 串行器 | 将处理后的图像数据进行传输,可用于传输RGB、YUV等多种图像数据种类 |
| 焦距 f | 焦距也称为焦长,是光学系统中衡量光的聚集或发散的度量方式,指从透镜中心(即光心)到光聚集之焦点的距离。亦是照相机中,从镜片光学中心到底片、CCD或CMOS等成像平面的距离。焦距决定了视角,也即决定了取景范围。焦距越小,视野越宽,取景范围越广,能拍摄到的画面越多;焦距越大,视野越窄,取景范围也就越窄,能拍摄到的画面就越少。 |
| 景深(DOF) | 是指在摄影机镜头或其他成像器前沿能够取得清晰图像的成像所测定的被摄物体前后距离范围。光圈、镜头、及焦平面到拍摄物的距离是影响景深的重要因素。在镜头前方(焦点的前、后)有一段一定长度的空间,当被摄物体位于这段空间内时,其在底片上的成像恰位于同一个弥散圆之间。被摄体所在的这段空间的长度,就叫景深。 换言之,在这段空间内的被摄体,其呈现在底片面的影象模糊度,都在容许弥散圆的限定范围内,这段空间的长度就是景深。景深浅,前景清晰,背景模糊(适合拍人像);景深深,前景清晰,背景清晰(适合拍风景)。 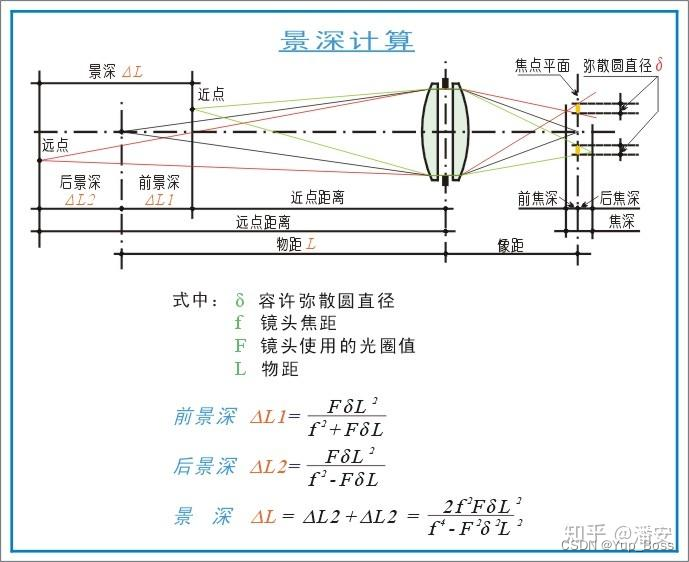 |
| 弥散圆(circle of confusion) | 物点成像时,由于像差,其成像光束不能会聚于一点,在像平面上形成一个扩散的圆形投影,成为弥散圆。当使点光源经过镜头在像平面成像,如果此时保持镜头与像平面距离不变,沿光轴方向前后移动点光源,则像平面上成的像就会成为有一定直径的圆形,就叫弥散圆。 它也被又译为弥散圈、弥散环、散光圈、 模糊圈、 散射圆盘。 |
| 镜头焦距、光圈、物距与景深之间的关系 | 镜头焦距、光圈、物距与景深之间的关系 |
| 帧率(frame rate) | 摄像机的参数 fps 是指每秒的帧数。一般摄像机的标准帧率范围是由制式所定。一般摄像机的帧数有两种情况,PAL制式一秒25帧,N制一秒30帧。高速摄像机一般是达到每秒120帧以上,也就是可以拍4.8倍的慢动作。PAL 是25fps;NTSC是29.97fps;电影格式24fps;单反另有30fps,高速摄像机每秒帧数没有具体最高规定。 |
| 码率 | |
| 以下是摄像头关键参数 | 以下是摄像头关键参数 |
| 探测距离 | |
| 分辨率 | |
| 最低照度 | 即图像传感器对环境光线的敏感程度,或者说是图像传感器正常成像时所需要的最暗光线。它是当被摄物体的光照逐渐降低时,摄像机的视频信号电平低于标准信号最大幅值一半时的景物光照度值。 |
| 信噪比 | 输出信号电压与同时输出的噪声电压的比值 |
| 动态范围 | 摄像机拍摄的同一个画面内,能正常显示细节的最亮和最暗物体的亮度值所包含的那个区间。动态范围越大,过亮或过暗的物体在同一个画面中都能正常显示的程度也就越大。 |
| 相对照度(Relative illumination又简写为RI) | 它是指一个光学系统所成像在边缘处的亮度相对于中心区域亮度的比值, 无单位. 在实际测量的结果中, 它不仅同光学系统本身有关, 也同所使用的感光片(SENSOR)有关. 同样的镜头用于不同的芯片可能会有不同的测量结果。这个车载镜头的RI指标是≥53%。 |
| 感光度 | 感光度使用ISO加数字来表示,一般的感光度级别有ISO100、200、400、800、1600等。低感光度指ISO100以下的胶片,中感光度指ISO200-800,高感光度为ISO800以上。感光度越低,画面越暗,画面越细腻;感光度越高,画面越亮,画质越粗糙。 |
| 快门 | 快门通常用百分比表示,如1/60。快门数字越大(1/60>1/2000),时间越长,画面越亮,越容易拍定格瞬间,适合拍运动中的物体;快门数字越小,时间越慢,画面越暗,越容易拍延时摄影。 |
| 光圈 | 光圈是镜头中控制孔径大小的组件。光圈大小与F数成反比。光圈F数值越小,光圈就越大,进光量越多,画面比较亮;光圈F数值越大,光圈就越小,画面比较暗。光圈是决定景深的重要因素,光圈小(光圈值大),景深深;光圈大(光圈值小),景深浅。 |
| AA制程(Active Alignment) | 是一种创新的装配技术,主要用于确定摄像头模组中各零部件的相对位置。 |
| 畸变 | 光学畸变(Opt distortion)和TV畸变(TV distortion) 。TV畸变则是指实际拍摄图像时的变形程度 |
怎样选择sensor的CRA?
- 广角镜头:这时一般lens的CRA比较大,需要选择CRA大于25度的sensor或者BSI的Sensor;一般用于手机、安防、玩具、网络摄像头等;
- 超长焦镜头:这时一般lens的CRA比较小,需要选择CRA为0度的sensor;一般用于安防、机器视觉等。
- 变焦镜头:这时Lens的CRA是变化的,一般需要根据实际应用选择,最好采用大Pixel,BSI的sensor;一般用于安防等。


















 3095
3095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









