






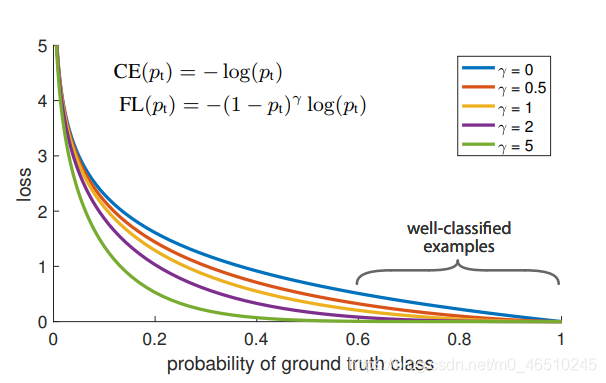
不同γ设置的损失曲线
Kaggle竞赛:SIIM-ISIC黑素瘤分类中,必须输出两类皮肤癌的皮肤病变图像中黑色素瘤的概率。因此它是一种二值图像分类任务。评价标准是AUC(曲线下面积)度量。首先,我研究了一个用交叉熵作为损失函数的模型。在网上搜索之后,我发现了这篇论文,Facebook AI research(FAIR)的团队引入了一个新的损失函数——Focal loss。
我用这个损失函数得到了一个很好的AUC分数(92+),所以我决定讨论一下这个损失函数。
目标检测器
在讨论Focal Loss之前,让我简要概述一下两种类型的对象检测器。一级和二级探测器。
两个阶段的探测器
此类对象检测器需要两个阶段来检测对象。第一阶段扫描图像并生成建议,第二阶段对这些建议进行分类并输出边框和类。精度相当好,但速度慢于一级物体探测器。
一个阶段的探测器
这类对象检测器只需要一个阶段来检测对象。将图像划分为(n x n)的网格,其中n可以是任意正整数。然后通过卷积神经网络检测对象,输出图像中与对象对应的包围框。请注意,所有网格都在这个网络的单一迭代中分类。这些物体探测器比两级物体探测器速度快,但相对来说精度较低。
Focal Loss(交叉熵损失的延伸)
Focal Loss基本上是交叉熵损失的延伸。它足够具体地处理阶级不平衡的问题。交叉熵损失被定义为
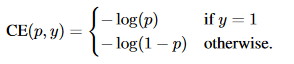
这里,y={-1,1}为ground truth label, p为待分类实例属于正类的概率(y=1)。
我们还可以将变量\pt定义为
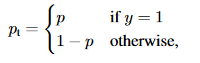
所以交叉熵损失可以写成
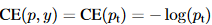
这个损失函数在某种程度上不能处理正/负例子的重要性,因此引入了一个新的版本,名称为:Balanced Cross entropy(平衡交叉熵),并被定义为
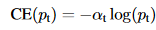
这里引入了一个权重因子“α”,其范围为[0,1],正类为α,负类为“1 -α”,这两个定义合并在一个名为“α”的名称下,可以定义为
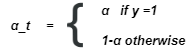
这个损失函数稍微解决了类不平衡的问题,但是仍然无法区分简单和困难的例子。为了解决这个问题,我们定义了焦损失。
Focal Loss的定义
理论定义:Focal Loss可以看作是一个损失函数,它使容易分类的样本权重降低,而对难分类的样本权重增加。
数学定义:Focal loss 调变因子(modulating factor)乘以原来的交叉熵损失。
公式为:
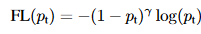
(1-pt)^γ为调变因子,这里γ≥0,称为聚焦参数。
从上述定义中可以提取出Focal Loss的两个性质:
- 当样本分类错误时,pt趋于0,调变因子趋于1,使得损失函数几乎不受影响。另一方面,如果示例被正确分类,pt将趋于1,调变因子将趋向于0,使得损耗非常接近于0,从而降低了该特定示例的权重。
- 聚焦参数(γ)平滑地调整易于分类的示例向下加权的速率。
FL(Focal Loss)和CE(交叉熵损失)的比较
当γ=2时,与概率为0.9的示例相比,概率为0.9的示例的损失比CE和0.968低100倍,损失将降低1000倍。
顶部的图描述了不同γ值下的FL。当γ=0时,FL等于CE损耗。这里我们可以看到,对于γ=0(CE损失),即使是容易分类的例子也会产生非平凡的损失震级。这些求和的损失可以压倒稀有类(很难分类的类)。
Focal Loss*(一种优化后的形式)
对于Focal Loss的新定义,我们可以将数量xt定义为:
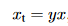
这里y={-1,1}指定基本真标签。我们可以将pt写成:
我们可以用xt来定义Focal Loss损失:
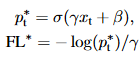
γ: 控制损失曲线的陡度。
β: 控制损失曲线的偏移。
最后,让我们用CE、FL和FL*的损耗曲线图结束讨本篇文章(β和γ有两个设置)-
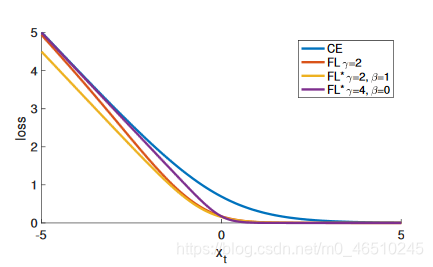
虽然Focal Loss是专门为单级目标检测定义的,它也可以很好地执行图像分类任务。
引用
Focal Loss for Dense Object Detection https://arxiv.org/pdf/1708.02002.pdf
作者:Sarthak khandelwal
deephub翻译组

















 4079
4079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









