







目前比较方便的LDA解法是gibbs采样,但是对于改进型LDA,如果分布不再是dirchlet分布,p(z|w)可能就不太好求了(这里z代表隐藏变量,w是观察量),只能用变分法。
LDA变分EM算法
LDA主要完成两个任务,给定现有文档集合D,要确定超参数
α,β
值;或者给一篇新的文档,能够依据前面的超参数来确定隐藏变量
θ,z
分布。其实后面一个任务可以归到前面中,因为前面可以顺带求出隐变量分布。
这里采用模型是比较原始的LDA模型,论文参考blei的2003年论文和“Note 1: Varitional Methods for Latent Dirichlet Allocation”
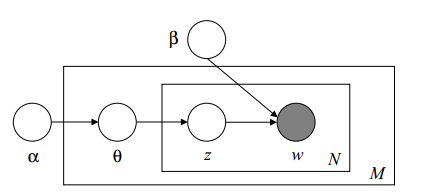
(这里
β
代表k*v的矩阵,代表一个确定的主题-词分布矩阵)
首先我们想计算出
p(D∣α,β)
,然后用最大似然估计来确定参数。然而发现:
ln(p(D∣α,β))=∑ln(∫p(w,θ,z)dθdz)
显然里面的联合概率很好求,但是积分没法求。所以得寻求其他方案。
可以参见prml书的第九章和第十章,采用EM算法。
ln(p(D∣α,β))=L(q(θ,z),α,β)+KL(q(θ,z)||p(θ,z|D))
这里把部分依赖\alpha ,\beta省略了。
由于KL>=0,所以L显然是ln(p(D∣α,β))的一个下界。首先让下界最大,即如果模型参数固定,那么左式显然是一个固定的常数,当且仅当KL最小的时候,即q(θ,z)是参数的后验概率时成立。
这里假定q的形式是已知的,变分参数未知,也就是假定:
q(θ,z|γ,ϕ)=q(θ|γ)∗q(z|ϕ)
,那么最大化L就可以得到变分参数
γ,ϕ
。这里主要的过程就是求导了。最后的结果是
γ=f(α,β,ϕ)
,
ϕ=g(α,β,γ)
,对了这里采用固定点迭代的方法求。
上面的这一过程就是E步,即在给定模型参数的情况下试图使下界尽可能大的一个过程,所表现出来的形式就是L函数可以是一个函数关于隐含变量后验期望的表示。
下面介绍M步。即对于前面变分参数确定后,q(\theta,z|\gamma,\phi)已知了,L函数也表示出来了,那么接下来就是使得L函数关于
α,β
最大化。注意前面L最大化针对的是
γ,ϕ
,结果上使得L趋近于ln(p(D∣α,β));而这里针对
α,β
,结果上是提升ln(p(D∣α,β)),同时KL>0,导致ln(p(D∣α,β))主要变化集中在M步,而且是单调的。然后继续是求导了,详细过程参考前面的文档。
(Note:在E步时,因为推断的是文档相关的变分参数和隐藏变量,而文档之间相互独立,所以可以用一篇文档w代替文档集D;而M步的模型参数是针对全文档集的,因此必须使用D)
LDA的gibbs采样
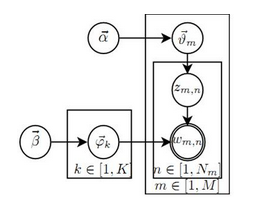
详细过程参考LDA数学八卦。这里主要做一些补充解释。
以该书推导过程为例,首先gibbs采样前提是假设超参数已知,然后任务是推断隐藏变量分布或者说隐藏变量的期望。也就是实际上估计:
p(θ,ϕ,z|D,α,β)
。由于\theta,\phi是多项分布的概率,所以可以依据z和w间的关系统计出来,所以实际上只要估计p(z|D,\alpha,\beta)就可以了,这称之为collapsed的lda gibbs采样。这就是gibbs要采样的概率分布。然后采样到这些样本后,可以直接拿来做平均就得到z的期望;或者统计次数得到其他隐藏变量的期望。
(NOTE:估计参数指得到一个固定的具体的值;估计随机量首先必须要得到该分布,或以概率最大的点MAP代替该随机量;或采样后以期望代替该随机量)















 434
434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









